

Достоинства и недостатки связных списков
Связные списки обладают одним очень важным преимуществом: для них операции вставки и удаления принадлежат к классу O(1). Независимо от текущего элемента спуска и его емкости, для вставки или удаления элемента всегда требуется одно и то же время.
Основным недостатком связных списков является то, что получение доступа к их элементам принадлежит к классу О(n). В этом случае важно количество элементов в списке: при поиске n‑ного элемента мы начинаем с некоторой позиции в списке и переходим по ссылкам вплоть до искомого элемента. Чем больше элементов в списке, тем больше переходов придется совершить. Для увеличения быстродействия в реализации классов списков мы воспользовались небольшими хитростями, но, тем не менее, операция все равно принадлежит к классу O(n).
По сравнению с классом TList связные списки требуют большего объема памяти. В качестве ссылки на элемент в TList используется один указатель, т.е. в массиве TList для каждого элемента требуется, по крайней мере, sizeof(pointer) байт. С другой стороны, односвязный список содержит два указателя: указатель на данные и указатель на следующий элемент. Таким образом, для каждого элемента в односвязном списке нужно, по меньшей мере, 2*sizeof(pointer) байт.
Очевидно, что для каждого элемента в двухсвязном списке требуется не менее 3*sizeof(pointer) байт.
Но это еще не все. Если неэффективно использовать массив TList (другими словами, не использовать свойство Capacity для установки размера массива), будут распределяться несколько блоков памяти, каждый из которых больше предыдущего, и потребуется больший объем работ, связанный с копированием данных массива. Если элементы вставляются только в начало, быстродействие массива TList существенно уменьшается. В настоящей книге будут приведены несколько реализаций алгоритмов и структур данных, которые позволяют достичь для связных списков гораздо большей эффективности, нежели это показывает TList, однако в общем случае массив TList лучше, быстрее и эффективнее связных списков.
Стеки
Еще одной известной и широко используемой структурой данных является стек. Стек представляет собой структуру, которая позволяет выполнять две основных операции: заталкивание для вставки элемента в стек и выталкивание с целью считывания данных из стека. Структура устроена таким образом, что операция выталкивания всегда возвращает элемент, вставленный в стек последним (самый "новый" элемент в стеке). Другими словами, элементы в стеке считываются в порядке, обратном порядку их записи в стек. Благодаря такому устройству стек известен как контейнер магазинного типа.
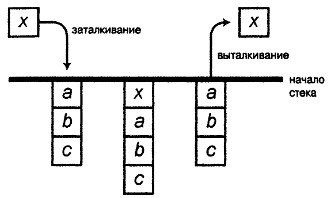
Рисунок 3.7. Операции заталкивания и выталкивания для стека
Написание кода стека не представляет никаких трудностей. Причем существуют два варианта реализации: первый ‑ на основе односвязного списка, второй ‑на основе массива. Как и в случае со списками, будем считать, что записываться и считываться из стека будут указатели на элементы. Сначала рассмотрим организацию стека на базе связного списка.