

Узлы связного списка
Перед началом описания операций со связным списком давайте рассмотрим, как каждый узел списка будет представляться в памяти. Знание структуры узла позволит нам более детально рассматривать основные операции со связными списком. Структура узла списка, не использующего классы и объекты, выглядит следующим образом:
type
PSimpleNode = ^TSimpleNode;
TSimpleNode = record
Next : PSimpleNode;
Data : SomeDataType;
end;
Тип PSimpleNode представляет собой указатель на запись TSimpleNode, поле Next которой содержит ссылку на точно такой же узел, а поле Data ‑ сами данные. В приведенном примере тип данных узла задан как SomeDataType. Для перехода по ссылке нужно написать примерно следующий код:
var
NextNode, CurrentNode : PSimpleNode;
begin
• • •
NextNode := CurrentNode^.Next;
Создание односвязного списка
Это тривиальная задача. В самом простом случае первый узел в связном списке описывает весь список. Первый узел иногда называют головой списка.
var
MyLinkedList : PSimpleNode;
Если MyLinkedList содержит nil, списка еще нет. Таким образом, это начальное значение связного списка.
{инициализация связного списка}
MyLinkedList := nil;
Вставка и удаление элементов в односвязном списке
А каким образом можно вставить новый элемент в связный список? Или удалить? Оказывается, что для выполнения этих операций требуется выполнить небольшую работу с указателями.
Для односвязного списка существует только один вариант вставки ‑ после заданного элемента списка. Нужно установить так, чтобы указатель Next нашего нового узла указывал на узел после заданного, а указатель Next заданного узла ‑ на наш новый узел. В коде это выглядит следующим образом:
var
GivenNode, NewNode : PSimpleNode;
begin
• • •
New(NewNode);
.. задать значение поля Data..
NewNode^.Next := GivenNode^.Next;
GivenNode^.Next := NewNode;
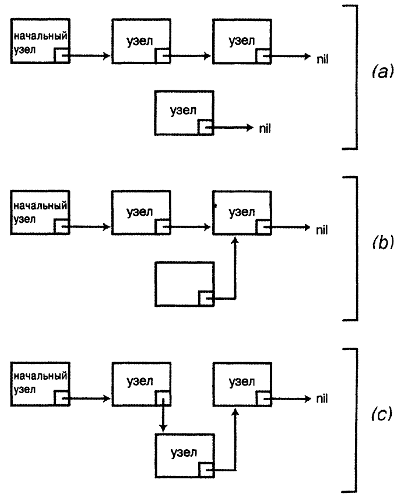
Рисунок 3.2. Вставка нового узла в односвязный список
Аналогично, для удаления простейшим вариантом является удаление элемента, находящегося после заданного узла. В этом случае мы устанавливаем, чтобы указатель Next заданного узла указывал на узел, расположенный после удаляемого. После этого удаляемый узел уже выделен из списка и может быть освобожден. В коде это выглядит следующим образом:
var
GivenNode, NodeToGo : PSimpleNode;
begin
• • •
NodeToGo := GivenNode^.Next;
GivenNode^.Next := NodeToGo^.Next;
Dispose(NodeToGo);
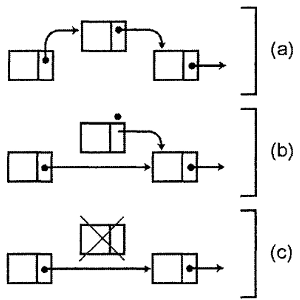
Рисунок 3.3. Удаление узла из односвязного списка
Тем не менее, для обеих операций существует специальный случай: вставка перед первым элементом списка (т.е. новый элемент становиться первым) и удаление первого элемента списка (т.е. первым становится другой элемент). Поскольку в наших рассуждениях первый элемент считается определяющим узлом всего списка, код для этих случаев нужно написать отдельно. Вставка перед первым узлом будет выглядеть следующим образом:
var
GivenNode, NewNode : PSimpleNode;
begin
• • •
New(NewNode);
.. задать значение поля Data..
NewNode^.Next := MyLinkedList;
MyLinkedList := NewNode;
а удаление будет выглядеть так:
var
GivenNode, NodeToGo : PSimpleNode;
begin
• • •
NodeToGo := GivenNode^.Next;
MyLinkedList := NodeToGo^.Next;
Dispose(NodeToGo);
Обратите внимание, что код вставки элемента будет работать даже в случае, когда исходный список пуст, т.е. содержит nil, а код удаления элемента правильно установит содержимое связного списка в случае удаления из него последнего узла.
Прохождение связного списка также не представляет никаких трудностей. Фактически мы переходим от узла к узлу по указателям Next до достижения указателя nil, который свидетельствует об окончании списка.
var
FirstNode, TempNode : PSimpleNode;
begin
• • •
TempNode := FirstNode;
while TempNode <> nil do
begin
Process(TempNode^.Data);
TempNode := TempNode^.Next;
end;
В этом простом цикле процедура Process (определенная в другом месте) выполняет обработку поля Data переданного ей узла. Очистка связного списка требует небольшого изменения алгоритма, чтобы гарантировать, что мы не ссылаемся на поле Next после освобождения узла (довольно‑таки частая ошибка).
var
MyLinkedList, TempNode, NodeToGo : PSimpleNode;
begin
NodeToGo := MyLinkedList;
while NodeToGo <> nil do
begin
TempNode := NodeToGo^.Next;
Dispose(NodeToGo);
NodeToGo := TempNode;
end;
MyLinkedList :=nil;
Теперь, когда мы научились проходить по узлам связного списка, давайте вернемся к вопросу, который, наверное, появился у вас пару абзацев назад. А что если нам нужно вставить узел перед заданным узлом? Как это сделать? Единственным решением такой задачи для односвязного списка является прохождение списка и поиск узла, перед которым мы должны вставить новый узел. При прохождении будут использоваться две переменных: одна будет указывать на текущий, а вторая на предыдущий узел (родительский узел, если можно так сказать). Когда будет найден заданный узел, у нас будет указатель на предыдущий узел, что позволит использовать алгоритм вставки после заданного узла. В коде это выглядит следующим образом:
var
FirstNode, GivenNode, TempNode,
ParentNode : PSimpleNode;
begin
ParentNode := nil;
TempNode := FirstNode;
while TempNode <> GivenNode do
begin
ParentNode := TempNode;
TempNode := ParentNode^.Next;
end;
if TempNode = GivenNode then begin
if (ParentNode = nil) then begin
NewNode^.Next := FirstNode;
FirstNode := NewNode;
end
else begin
NewNode^.Next := ParentNode^.Next;
ParentNode^.Next := NewNode;
end;
end;
Обратите внимание на специальный код для случая вставки нового узла перед первым узлом (в этом случае родительский узел nil). Код для вставки перед заданным узлом медленнее кода вставки после заданного узла, поскольку он требует прохождения списка с целью обнаружения родительского узла заданного узла. В общем случае, при необходимости вставки нового узла перед заданным мы будет использовать двухсвязный список, который будет подробно рассмотрен немного ниже.