

Практическая работа 11
Вычисление статистических характеристик
Ввести данные из таблицы 4.
Вычислить следующие статистические характеристики ряда данных:
количество значений;
сумма;
максимум;
минимум;
среднее арифметическое;
среднее линейно отклонение;
Таблица 4
дисперсия по генеральной совокупности;
дисперсия по выборке;Месяц
Цена
Январь 2009
8,0
Февраль 2009
8,5
Март 2009
8,0
Апрель 2009
8,5
Май 2009
9,0
Июнь 2009
10,0
Июль 2009
9,5
Август 2009
10,0
Сентябрь 2009
10,5
Октябрь 2009
10,5
Ноябрь 2009
10,5
Декабрь 2009
11,0
среднее квадратичное отклонение;
смещенное среднее квадратичное отклонение (по выборке);
мода;
медиана.
Вычисления произвести тремя способами: по формулам, с помощью стандартных функций; с помощью надстройки Пакет анализа.
Указание:
для расчетов по формулам добавить к
таблице данных столбцы для вычисления
отклонений
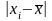 и квадратов отклонений.
и квадратов отклонений.
Экстраполяция
На новый лист поместить копию столбца Месяц и шесть копий столбца Цена. Дать новые названия столбцам: Линейное приближение, Предсказание, Тенденция, Экспоненциальное приближение, Рост, Геометрическая прогрессия. Над первыми тремя столбцами ввести общее название Линейная экстраполяция, над последними тремя столбцами – Экспоненциальная экстраполяция.
Используя маркер заполнения, дополнить столбец Месяц датами до июня 2010 г.
Выполнить линейную экстраполяцию, используя операцию автозаполнения. Для этого следует:
выделить значения столбца Линейное приближение (без заголовка);
протащить маркер заполнения правой на шесть ячеек вниз кнопкой мыши;
в открывшемся контекстном меню выбрать пункт Линейное приближение.
Выполнить экспоненциальную экстраполяцию, используя операцию автозаполнения и пункт контекстного меню Экспоненциальное приближение (использовать данные соответствующего столбца).
Выполнить линейную экстраполяцию при помощи функции ПРЕДСКАЗ():
установить курсор в ячейке столбца Предсказание, соответствующей дате «Январь 2010», вызвать функцию ПРЕДСКАЗ();
в поле X указать ячейку с датой «Январь 2010»;
в поле Известные значения x – диапазон ячеек столбца Месяц с датами от января 2009 до декабря 2009 (абсолютные ссылки);
в поле Известные значения y – диапазон ячеек столбца Предсказание, соответствующий датам от января 2009 до декабря 2009 (абсолютные ссылки);
скопировать формулу в остальные ячейки столбца Предсказание
Выполнить линейную экстраполяцию при помощи функции ТЕНДЕНЦИЯ():
выделить ячейки столбца Тенденция, соответствующие датам от января 2010 до июня 2010;
вызвать функцию ТЕНДЕНЦИЯ();
в поле Известные значения y указать диапазон ячеек столбца Тенденция, соответствующий датам от января 2009 до декабря 2009;
в поле Известные значения x ‑ диапазон ячеек столбца Месяц с датами от января 2009 до декабря 2009;
в поле Новые значения x ‑ диапазон ячеек столбца Месяц с датами от января 2010 до июня 2010;
нажать клавиши Ctrl + Shift + Enter.
Выполнить экспоненциальную экстраполяцию при помощи функции РОСТ() (аргументы этой функции такие же, как и у функции ТЕНДЕНЦИЯ).
Выполнить экстраполяцию, используя операцию автозаполнения и пункт контекстного меню Прогрессия (геометрическая прогрессия с автоматическим определением шага).
Построение линии тренда
На отдельном листе построить диаграмму, отображающую изменение цены за период с января по декабрь 2009 г.: в качестве категорий использовать данные из столбца Месяц, в качестве ряда – данные из столбца Цена.
Построить линии тренда различных типов: экспоненциальную, линейную, логарифмическую, полиномиальную, степенную. Сделать прогноз на 6 периодов вперед. Задать показ уравнений линий тренда. Задать разные цвета для линий.
Корреляционно-регрессионный анализ
Ввести данные из таблицы 5.
Значения столбца Себестоимость рассчитываются как сумма всех видов затрат; Наценка = Цена – Себестоимость.
Используя функцию КОРРЕЛ(), вычислить коэффициенты парной корреляции между ценой и себестоимостью.
При помощи функции ЛИНЕЙН() вычислить коэффициенты m и b уравнения регрессии y=mx+b, показывающего зависимость цены от себестоимости (эта функция возвращает массив из двух ячеек, поэтому перед вводом формулы надо выделить две ячейки, а закончить ввод формулы – нажатием клавиш Ctrl+Shift+Enter).
При помощи функции ЛИНЕЙН() вычислить коэффициенты m и b уравнения регрессии y=mx+b, показывающего зависимость цены от наценки.
При помощи функции ЛИНЕЙН() вычислить коэффициенты m1, m2, m3, m4, m5, m6 и b уравнения регрессии
y=m1x1+m2x2+m3x3+m4x4+m5x5+m6x6+b,
показывающего зависимость цены от всех видов затрат (эта функция возвращает массив из семи ячеек).
Таблица 5
Товар |
Цена |
Материальные затраты |
Затраты на оплату труда |
Транспортные расходы |
Амортизация |
Реклама |
Прочие расходы |
Себестоимость |
Наценка |
Тов.1 |
3500 |
875 |
500 |
70 |
75 |
30 |
0 |
|
|
Тов.2 |
10000 |
1000 |
1500 |
220 |
330 |
100 |
10 |
|
|
Тов.3 |
300 |
75 |
140 |
10 |
20 |
25 |
2 |
|
|
Тов.4 |
250 |
63 |
80 |
13 |
10 |
30 |
1 |
|
|
Тов.5 |
9000 |
2000 |
3500 |
400 |
0 |
80 |
0 |
|
|
Тов.6 |
4700 |
1500 |
1880 |
230 |
200 |
47 |
24 |
|
|
Тов.7 |
2700 |
675 |
1080 |
100 |
100 |
27 |
14 |
|
|
Тов.8 |
900 |
300 |
360 |
50 |
50 |
0 |
10 |
|
|
Тов.9 |
950 |
100 |
400 |
48 |
40 |
55 |
20 |
|
|
Тов.10 |
3500 |
875 |
1500 |
178 |
100 |
60 |
18 |
|
|
Выполнить корреляционно-регрессионный анализ зависимости цены от себестоимости, цены от наценки и цены от всех видов затрат, используя надстройку Пакет анализа.
Частотный анализ
Ввести данные из таблицы 6.
Определить параметры группировки:
максимум = максимальное значение интервала;
минимум = минимальное значение интервала;
размах вариации = максимум ‑ минимум;
количество интервалов = 4;
интервал группировки = размах вариации / количество интервалов.
Выполнить частотный анализ при помощи функции ЧАСТОТА(). Для этого оставить таблицу со столбцами
№ группы – номера по порядку от 1 до 4;
Верхняя граница = МИН(массив)+{1:2:3:4}*(МАКС(массив)-МИН(массив))/4;
Число банков – использовать функцию ЧАСТОТА().
Таблица 6
№ банка |
Уставный капитал |
1 |
2351 |
2 |
17489 |
3 |
2626 |
4 |
2100 |
5 |
23100 |
6 |
18684 |
7 |
5265 |
8 |
2227 |
9 |
6799 |
10 |
3484 |
11 |
13594 |
12 |
8873 |
13 |
2245 |
14 |
9060 |
15 |
3572 |
16 |
7401 |
17 |
4288 |
18 |
5121 |
19 |
9998 |
20 |
2970 |
21 |
3415 |
22 |
4778 |
23 |
5029 |
24 |
6110 |
25 |
5861 |
26 |
17218 |
27 |
20454 |
28 |
10700 |
29 |
2950 |
30 |
12082 |
Массив данных – интервал ячеек столбца Уставный капитал;
Массив интервалов – интервал ячеек столбца Верхняя граница.
Построить гистограмму: в качестве ряда использовать значения столбца Число банков, в качестве категорий – значения столбца Верхняя граница.
На гистограмме построить линию тренда экспоненциального типа, показать уравнение на диаграмме.
Провести частотный анализ при помощи надстройки Пакет анализа:
в качестве входного интервала указать интервал ячеек столбца Уставный капитал;
в качестве интервала карманов указать интервал ячеек столбца Верхняя граница;
в качестве выходного интервала указать левую верхнюю ячейку диапазона, куда должны быть выведены результаты;
установить флажок Вывод графика.
Повторить частотный анализ при помощи надстройки Пакет анализа, но не указывать интервал карманов (в этом случае он будет сформирован автоматически). Сравнить результаты.
Выполнить частотный анализ, используя сводную таблицу: в область Названия строк поместить поле Уставный капитал, в область Значения – поле № банка, выбрать операцию Количество. Провести группировку по полю Уставный капитал, в качестве начального и конечного значений задать соответственно минимальное и максимальное значение поле Уставный капитал, в качестве шага – интервал группировки, равный (МАКС(Уставный капитал)-МИН(Уставный капитал))/4.
Построить сводную диаграмму. Для этого выделить любую ячейку в сводной таблице и на вкладке Работа со сводными таблицами – Параметры в группе Сервис выбрать команду Сводная диаграмма.