

Проверка согласия по критерию
Рассмотрим производителя неких продуктов питания, который разработал новой рецепт продукта, который уже пользуется популярностью у потребителей. На основе данных сканирования по существующим продуктам было установлено, что на одну упаковку, проданную потребителю в возрасте от 18 до 35 лет, приходится три упаковки, проданные покупателю в возрасте от 35 до 55 лет и две упаковки, проданные людям старше 55 лет. Производителю требуется узнать, сохранится ли это соотношение продаж для продукта, изготовленного по новой рецептуре.
Для этого производитель провел рыночный тест для определения относительных частот приобретения нового продукта разными категориями покупателей. В результате надлежащим образом организованного рыночного теста было продано 1200 упаковок нового продукта в течение одной недели. Распределение этого объема продаж выглядит следующим образом: 18-35 лет – 265 упаковок; 35-55 лет – 610 упаковок; старше 55 лет – 325 упаковок.
Полученные цифры не соответствуют образцу соотношения, установленному по традиционной рецептуре продукта. Означает ли это, что продажа нового продукта не будет идти в традиционном соотношении?
Для решения такого типа задач хорошо подходит проверка согласия по критерию . Множество значений, принимаемых интересующей нас переменной разбивается на k взаимоисключающих интервалов (в нашем примере k=3). Каждое наблюдение логически попадает в один из этих интервалов. Фактически это – частотный анализ для переменной «возрастная категория». Предполагается, что испытания (покупки) независимы и объем выборки велик.
Для проведения проверки необходимо определить количество ожидаемых попаданий в рассматриваемые интервалы (ожидаемое число событий) и сравнить их с числом значений из выборки действительно попавших в соответствующие интервалы (наблюдавшимся числом событий), используя уравнение:
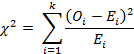
где
![]() - наблюдавшееся число событий, попадающих
в i-й
интервал;
- наблюдавшееся число событий, попадающих
в i-й
интервал;
![]() -
ожидаемое число событий, попадающих в
i-й
интервал; k
– число интервалов.
-
ожидаемое число событий, попадающих в
i-й
интервал; k
– число интервалов.
Ожидаемое число событий получаем из нулевой гипотезы, которая в рассматриваемом примере состоит в том, что распределение продаж нового продукта по возрастным группам будет повторять нормальное для продаж традиционного продукта соотношение 1:3:2. Если бы то продажа 1200 упаковок во время тестирования подчинялась ожидаемому образцу продаж, то потребители в возрасте 18-35 лет приобрели бы 200 упаковок; 35-55 лет – 600 упаковок; старше 55 лет – 400 упаковок. Соответствующая статистика рассчитывается следующим образом:
![]()
Распределение полностью определяется величиной, называемой числом степеней свободы n. Под термином «степени свободы» подразумевается такое количество параметров, характеризующих состояние некоторого объекта, которые могут меняться независимо. Как правило, число степеней свободы на единицу меньше числа категорий (n=k - 1), т.е. (n=k - 1=2).
Выберем
для этой поверки уровень значимости
α=0,05. Табулированное значение
для двух степеней свободы и α=0,05 составляет
5,99 (см. Таблицу 1 Приложения). Поскольку
рассчитанное значение
![]() =
7,23 больше, заключение состоит в том, что
вероятность случайного получения таких
различий (если бы нулевая гипотеза была
истинна) меньше 0,05. Таким образом,
результаты предварительного рыночного
тестирования показывают, что продажи
продукта, изготовленного по новой
рецептуре, будет идти иным образом, чем
считалось типичным для данной продукции.
Нулевая гипотеза о продаже в соотношении
1:3:2 отвергается.
=
7,23 больше, заключение состоит в том, что
вероятность случайного получения таких
различий (если бы нулевая гипотеза была
истинна) меньше 0,05. Таким образом,
результаты предварительного рыночного
тестирования показывают, что продажи
продукта, изготовленного по новой
рецептуре, будет идти иным образом, чем
считалось типичным для данной продукции.
Нулевая гипотеза о продаже в соотношении
1:3:2 отвергается.
Описанная в общих чертах проверка является приблизительной. Приближение оказывается сравнительно неплохим, если, как общее правило, ожидаемое число событий в каждой категории равно 5 и более, хотя в некоторых ситуация оно может опускаться даже до 1.
Z-тест для сравнения выборочной доли со стандартом
Рассмотрим данный параметрический метод сравнения независимых выборок на следующем примере. Допустим, компания получила данные о том, что достаточное количество потребителей предпочтут ее новый продукт. Но на решение о выходе на рынок накладывается еще одно ограничение: компания не будет выводить новый продукт на рынок в случае, если более 50% потребителей будут по-прежнему предпочитать существующий продукт конкурентов. Нулевая и альтернативная гипотеза будут сформулированы следующим образом:
![]()
![]()
Результаты исследования показали, что 322 респондента из 700 отдали предпочтение конкурентам, так что p=322/700=0,46. Таким образом, вероятно, менее 50% потребителей предпочтут продукцию конкурентов после выхода на рынок, однако необходимо проверить, отличается ли статистически полученное значение (0,46) от стандарта (0,50). Вычисляем по формуле:
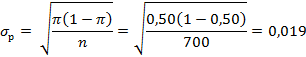
![]()
Вероятность (Р) получения z-статистики, равной -2,1 можно из стандартных таблиц (см. Таблицу 2 Приложения). Р=0,9642; 1-Р сравниваем с α. Оно ниже уровня значимости, заданного в исследовании (стандартный уровень значимости α=0,05). Поэтому нулевая гипотеза будет отвергнута и принята альтернативная, которая заключается в том, что после вывода на рынок нового продукта доля потребителей, предпочитающих продукцию конкурентов, не превысит 50%.
Контрольные вопросы и вопросы для самостоятельного изучения
Опишите процедуру определения частот распределения значений переменной.
Какие показатели центра распределения, вариации и формы распределения вычисляют в ходе обобщения сырых данных анкетирования?
Что показывает дисперсия выборочного среднего?
Из каких этапов состоит схема проверки гипотезы в маркетинговых исследованиях?
Как соотносятся нулевая и альтернативная гипотезы?
Что обусловливает выбор метода проверки гипотез об одной переменной?