

1nikitin_a_ya_sosunova_i_a_analiz_i_prognoz_v_ekologicheskikh
.pdf19
Для расчета коэффициента автокорреляции часто используют формулу:
|
|
|
( |
|
|
|
|
|
|
)/(σΥ |
* σΥ |
|
|
|
|
|
r = |
YY |
- |
|
* |
|
) |
|
(8), |
||||||
Υ |
Υ |
||||||||||||||
|
|
|
|
t t−τ |
|
t |
|
t−τ |
t |
t −τ |
|
|
|
||
|
Yt Yt-τ |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
средние арифметические соответствующих рядов, а |
|
|
||||||||
где |
|
|
и |
|
YtYt−τ |
- среднее |
|||||||||
Υt |
|||||||||||||||
|
Υt −τ |
||||||||||||||
арифметическое значение ряда их парных произведений (все средние арифметические
вычисляются в соответствии с формулой (1) оценки простой средней);
σ Υ t − τ - стандартные отклонения соответствующих рядов, которые равны квадратному из значений их дисперсий (4).
Значения ra изменяются в пределах: -1 < ra < 1.
Чем ближе значения ra к ± 1, тем сильнее связь между наблюдениями в ряду. Значимость коэффициента автокорреляции проверяется по таблице, составленной Р. Андерсеном (Приложение 1) /1/.
Если ra значим, то ряд неслучаен, и между последовательными наблюдениями в нем существует определенная связь. В противном случае нуль-гипотеза не может быть отклонена. Кроме того, величина коэффициента автокорреляции позволяет делать некоторые выводы о периоде колебаний. Высокие положительные значения достоверного ra указывают либо на наличие выраженного тренда, либо на низкочастотные, длиннопериодические колебания. Значимый отрицательный коэффициент свидетельствует о высокочастотных осцилляциях.
При измерении автокорреляции можно вычислить не один, а ряд последовательных значений ra.
Например, r1 - корреляция между двумя следующими друг за другом наблюдениями, начиная с первого;
r2 - корреляция между первым-третьим, вторым-четвертым и так далее уровнями; r3 - корреляция между первым-четвертым, вторым-пятым и так далее уровнями. В общем виде:
ra= r yt yt-τ |
(9), |
где yt – уровни исходного ряда; yt-τ |
- уровни того же ряда, но сдвинутые на τ (читает- |
ся «тал») шагов во времени; τ - величина лага (запаздывания), которая может принимать целые значения равные 1, 2, 3 и т.д. Эта величина определяет так называемый по-
20
рядок коэффициента автокорреляции. С увеличением величины лага (τ ) растет порядок коэффициента автокорреляции.
Совокупность последовательных значений ra называют автокорреляционной функцией или коррелограммой /1, 2, 7-10/. Если значим хотя бы один из серии рассчитанных ra, то это является основанием, чтобы отвергнуть нуль-гипотезу в пользу предположения о неслучайности наблюдений в анализируемом ряду. Вместе с тем, с увеличением порядка вычисляемого коэффициента автокорреляции, число коррелируемых пар, а, следовательно, и надежность оценки ra резко уменьшаются. В настоящее время, принято считать, что корректен расчет ra порядка не превышающего величины отношения n/4 /19/, где n - длина исследуемого ВР. Колебания ra , сболее высоким лагом не должны приниматься во внимание.
Пример 4.
Проведем расчет ra1 и ra2 по уравнению (8) и (9) для данных из табл.2.2 о заболеваемости населения Иркутска клещевым энцефалитом в 2001 г. /15/.
Порядок расчета дополнительных показателей, необходимых для оценки ra по этим формулам при использовании калькулятора приведен в табл.2.3. Значимость полученного коэффициента автокорреляции оценивают путем сравнения с табличными значениями по Приложению 1.
Проведя необходимые расчеты по табл.2.3, получаем:
r a1 = (105,75 –8,33*8,42)/(7,19*7,09) = 35,61/50,98 = 0,699
r a2 = (92,55-8,91*8,64)/(7,25*7,39) = 15,57/53,58 = 0,291
Полученные оценки ra сравниваем с критическими значениями по Приложению 1. Величина ra для лага 1 значима на 1 % уровне, а для лага 2 – несуществененна (Р>0,05). В нашем примере допустимо вычислять ra не более третьего порядка (из расчета n/4). Соответствующий расчет значения для третьего лага (ra3 = -0,180) выявляет его незначимость. Однако факт существенности величины ra1 является достаточным основанием для того, чтобы отвергнуть нуль-гипотезу в пользу Н1.
Таким образом, применив к ряду наблюдений о характере заболеваемости населения Иркутска клещевым энцефалитом в течение сезона 2001 г. второй способ анализа на не случайность, мы также пришли к выводу о наличии связи между последовательными подекадными оценками количества больных клещевым энцефалитом, поступивших в стационары города.
21
Таблица 2.3 Расчет коэффициента автокорреляции первого и второго порядка для ВР по данным о заболеваемости населения Иркутска клещевым энцефалитом в 2001 г.
№ наблюде- |
Заболевае- |
Ряд сдви- |
Υ t * Υ t-1 |
Ряд сдви- |
Υ t * Υ t-2 |
ния (n) |
мость (исход- |
нутый на |
|
нутый на |
|
|
ный рядΥ t) |
один шаг |
|
два шага |
|
|
|
( Υ t-1) |
|
( Υ t-2) |
|
1 |
0 |
6 |
0 |
6 |
0 |
2 |
6 |
6 |
36 |
7 |
42 |
3 |
6 |
7 |
42 |
15 |
90 |
4 |
7 |
15 |
105 |
20 |
140 |
5 |
15 |
20 |
300 |
21 |
315 |
6 |
20 |
21 |
420 |
13 |
260 |
7 |
21 |
13 |
273 |
5 |
105 |
8 |
13 |
5 |
65 |
4 |
52 |
9 |
5 |
4 |
20 |
1 |
5 |
10 |
4 |
1 |
4 |
2 |
8 |
11 |
1 |
2 |
2 |
1 |
1 |
12 |
2 |
1 |
2 |
- |
- |
13 |
1 |
- |
- |
- |
- |
Среднее |
8,33* |
8,42 |
105,75 |
8,64 |
92,55 |
|
8,91** |
|
|
|
|
Стандартное |
7,19* |
7,09 |
- |
7,39 |
- |
отклонение |
7,25** |
|
|
|
|
(σ) |
|
|
|
|
|
ra |
- |
0,699 |
- |
0,291 |
- |
*Определено без значений строки № 13
**Определено без значений строк № 12 и 13
Вместе с тем, применение калькулятора в настоящее время полезно лишь на начальном этапе освоения статистического метода обработки данных, так как позволяет лучше понять его суть. В дальнейшей работе следует использовать стандартные компьютерные программы, например, Excel или Statistica. Программа Statistica, в отличие от Excel, обладает менее «дружественным интерфейсом», однако позволяет автоматически рассчитать не только любое допустимое число ra, с одновременной оценкой их значимости, но и вычисляет частные ra, с ролью которых в анализе ВР можно ознакомиться по специальной литературе /2/. В целом, при приобретении определенного опыта анализа рядов, предпочтительнее использовать программу Statistica.
22
2. 2.2. Анализ временного ряда на стационарность Ряд называется стационарным, если в нем отсутствуют нециклические тренды, а
амплитуда колебаний исследуемого параметра примерно одинакова на любом его отрезке.
К стационарным временным рядам приложимо большинство методов анализа и прогноза динамических процессов. Некоторые методы приложимы исключительно к стационарным рядам (оценка периода цикла колебаний с помощью спектрального анализа, измерение связи между ВР и др.) /2, 18/. Нас будет преимущественно интересовать оценка стационарности ряда относительно его центральной тенденции.
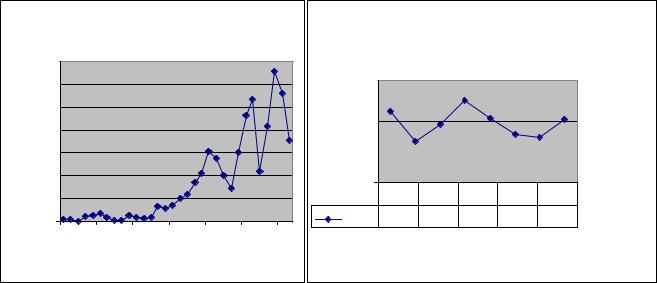
Часто для обнаружения нестационарности достаточно рассмотреть график процесса. Так, очевидно, что характер заболеваемости населения Иркутска клещевым энцефалитом за период с 1970 по 2001 гг. (рис.2а) в силу выраженного тренда на ее увеличение представляет нестационарный процесс.
|
|
|
а) |
|
|
|
|
населения |
35 |
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
25 |
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
100 тысяч |
|
|
|
|
|
|
|
15 |
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
на |
5 |
|
|
|
|
|
|
КЭ |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1970 |
1975 |
1980 |
1985 |
1990 |
1995 |
2000 |
|
|
|
|
Годы |
|
|
|
б)
0,8 |
|
|
|
|
|
|
|
|
r |
|
|
0,5 |
1 |
3 |
4 |
6 |
7 |
|
|||||
Ряд1 |
0,848 |
0,783 |
0,901 |
0,733 |
0,723 |
Рис. 2. а) Динамика заболеваемости населения клещевым энцефалитом в пригородах Иркутска; б) Изменение значений коэффициента автокорреляции (коррелограмма) ряда, представленного на рис.2а
Вместе с тем, для статистически обоснованного доказательства стационарности ВР необходимо пользоваться специальными приемами. Рассмотрим два из них: построение коррелограммы процесса и разбивки ряда на последовательные группы наблюдений с целью сравнения их между собой.

23
Оценка стационарности ряда с использованием коррелограммы
Если последовательные значения ra не имеют тенденции к затуханию, то ряд считают нестационарным (рис.2б). Для стационарных рядов последовательные значения ra стремятся к нулю /2/. Использование коррелограммы позволяет «улавливать» нестационарность в рядах даже в тех случаях, когда тренд отчетливо не виден на графиках. Вместе с тем, чтобы провести надежный анализ коррелограммы, необходимы достаточно длинные ряды, так как оценка каждого значения ra более высокого порядка становится все менее корректной и по сути не информативной (см. разд.2.2.1).
Применение метода будет рассмотрено в Примере 5.
Оценка стационарности ряда методом последовательной группировки Простым способом анализа ВР на стационарность является сравнение его пара-
метров, сгруппированных для начала, середины и конца ряда. Разбив ряд на три группы (выборки), для каждой из них вычисляют среднее значение по формуле (1) и величину дисперсии по формуле (4). Затем эти параметры сравниваются для отдельных отрезков исходного ряда.
Так, для установления факта стационарности ряда относительно его центральной тенденции (отсутствия нециклического тренда) сравнение средних арифметических выборок производится по t - критерию (критерий Стьюдента):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
t = |
|
|
|
|
|
|
|
|
|
Υ1 − Υ2 |
|
|
|
|
|
|
(10), |
||||||
|
σ |
2 |
(n −1) + |
σ |
2 (n |
|
|
−1) |
|
1 |
|
1 |
|||||||||||
|
|
2 |
|
|
|||||||||||||||||||
|
|
|
|
|
1 |
1 |
|
|
|
2 |
|
|
|
* |
|
|
+ |
|
|
|
|||
|
|
|
|
|
|
|
|
n + n |
2 |
− 2 |
|
|
|
|
n |
n |
2 |
|
|||||
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
||||
где |
|
|
1 |
и |
|
|
2 - средние арифметические, |
n1 и n2 – число наблюдений, σ1 и |
|||||||||||||||
Υ |
Υ |
||||||||||||||||||||||
σ2 |
- стандартные отклонения соответственно для первого и второго рядов. |
||||||||||||||||||||||
Степени свободы при расчете t- критерия определяются как: df = n1+ n2 –2. Полученное значение t сравнивается с приведенными в Приложении 2 оценками
критерия, табулированными для трех уровней значимости.
Если расчетное t меньше табличного, находящегося в графе соответствующей уровню значимости Р=0,05, то различия между средними отдельных отрезков исходного ВР признаются несущественными. Следовательно, принимается нуль-гипотеза о стационарности ряда относительно его центральной тенденции. Альтернативная гипотеза (о нестационарности ВР) принимается, когда расчетное t >t табл., из Приложения 2 для уровня значимости Р=0,05 с учетом имеющегося числа степеней свободы.
24
В настоящее время сравнение средних двух рядов можно провести с использова-
нием любой программы: Excel, Statistica, Lotus, Statgraphics и др.
Например, Excel в пункте «Сервис» основного меню содержит пакет команд «Анализ данных... ». После его активизации в раскрывшемся диалоговом окне выбираем либо «двухвыборочный t-тест с одинаковыми», либо с «...различными дисперсиями». Дальнейший порядок работы в программе проводится в соответствии с ее подсказками.
Применение метода будет рассмотрено в Примере 5.
2.2.2.1. Преобразование ряда к стационарному виду путем удаления трендов Если ряд не является стационарным по причине различия средних его значений на
отдельных участках, то для приведения исходного ВР к стационарному виду относительно центральной тенденции ряда необходимо удалить из него тренд. Рассмотрим два способа проведения этой процедуры.
Удаление тренда методом нахождения последовательных разностей Для преобразования ВР к стационарному виду используют прием взятия разно-
стей между двумя последовательными значениями наблюдений. Такие разности назы-
ваются первыми [ ∆ = ( Υt - Υt −1 )]. Если в ряду, представляющем первые разности,
вновь найти последовательные разности, то мы получим ряд вторых разностей [ ∆2], и так далее. Считается, что нахождение первых-вторых разностей процедура вполне достаточная для удаления трендов и приведения большинства ВР к стационарному виду /2/. Этот метод является простым и широко используемым, однако менее надежным, чем рассматриваемый ниже.
Удаление тренда из ряда путем подбора линии аппроксимации При использовании данного способа на первом этапе определяется тип тренда.
Эта процедура называется также заданием аналитического уравнения тренда.
Любая компьютерная программа статистических расчетов содержит несколько простых функций для аппроксимации данных, то есть, создания аналитических уравнений, математически описывающих исходные данные.
Так, в Excel с этой целью можно действовать следующим образом. Вначале создать график исходного ВР с помощью диалогового окна «Мастер диаграмм» основного меню программы. Затем, установив курсор мышки на исследуемой кривой, путем нажатия ее правой клавиши вызвать диалоговое окно, содержащее команду «Добавить
25
линию тренда...». Программа позволяет выбрать для аппроксимации имеющихся данных четыре простых (линейный, логарифмический, степенной, экспоненциальный) и полиномиальный тренды. Кроме того, перейдя в меню «Параметры» этой же панели управления, можно задать дополнительное условие вывода на график формулы аналитического уравнения выбранного тренда и величины коэффициента детерминации (R2). Последний параметр указывает, насколько хорошо выбранный тренд аппроксимирует исходную последовательность значений. По сути, этот показатель является квадратом коэффициента корреляции Пирсона /2, 4/ и отражает степень сходства двух кривых (см. разд.4). Чем больше R2, тем лучше уравнение тренда описывает исходные данные. Желательно, чтобы R2 был не ниже 0,7 – 0,8.
На втором этапе рассчитывают ожидаемые значения ВР по полученному аналитическому уравнению тренда.
На третьем этапе из каждого исходного наблюдения ВР вычитают значение, полученное по уравнению тренда, тем самым обеспечивая преобразование ряда остатков к стационарному виду.
Пример 5.
Рассмотрим работу статистических методов анализа рядов на стационарность, а также их преобразования к стационарному виду на примере рис.2 а, характеризующего динамику заболеваемости населения Иркутска клещевым энцефалитом /15/.
Для ряда, представленного на рис.2 а, по формулам: (8) и (9) проведен расчет коррелограммы, приведенной на рис.2 б. Очевидно, что изображенная на коррелограмме кривая не затухает. Следовательно, анализ рис. 2 б подтверждает сделанный ранее на основе визуального анализа исходного графика вывод о нестационарности рассматриваемого ряда.
К этим же данным применим второй подход, а именно метод анализа на стационарность путем последовательной группировки данных. Средняя заболеваемость населения в период с 1970 по 1980 гг. составила 0,79 случаев на 100 тысяч жителей, с 1980 по 1990 гг. – 5,23, а с 1991 по 2001 гг. - 18,77. Различия между первым и последним отрезками ВР являются высокодостоверными (t=7,21; df=20; по Приложению 2 P<0,001). Таким образом, с помощью еще одного метода подтверждено, что исследуемый ВР является не стационарным.
Попытаемся данные о заболеваемости населения клещевым энцефалитом за период с 1983 г. по настоящее время преобразовать таким образом, чтобы ВР стал стационарным относительно своей центральной тенденции. Варианты проведенных
26
трансформаций и их результаты приведены в табл. 2.4. Чтобы освоить методы преобразования рядов полезно все описанные далее операции выполнить самостоятельно.
Вначале проведено преобразование значений исходного ряда методом нахождения последовательных разностей (графа 4). Чтобы убедиться, что ряд остатков (гр.4) является стационарным относительно центральной тенденции, была произведена его разбивка на три группы. Величина средней для первой группы составила 1,04 (n=5), а для третьей средняя равна –1,79 (n=5). Различия в средних между отрезками ряда являются несущественными (t=0,51; df=8, P>0,05 по Приложению 2).
Таким образом, по отношению к центральной тенденции стационарность ряда остатков, полученных путем нахождения последовательных разностей исходных уровней, является доказанной.
Таблица 2.4
Преобразование ряда заболеваемости населения Иркутска клещевым энцефалитом к стационарному виду различными способами
№ |
Год |
Число |
Остатки |
Значения рядов, полученных по двум аналитическим |
|||
п/п |
|
боль- |
∆= Υt - Υt −1 |
уравнениям тренда и ряды остатков после их удаления |
|||
|
|
ных на |
|
|
|
|
|
|
|
100 |
|
Тренд |
Остат- |
Тренд |
Остат- |
|
|
тысяч |
|
=1,3343* Υi + 0,4184 |
ки |
=1,9614* Υi0,.8262 |
ки |
|
|
насе- |
|
|
(гр.3-гр.5) |
|
(гр.3-гр.7) |
|
|
ления |
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
1 |
1983 |
3,3 |
-0,40 |
1,8 |
1,5 |
2,0 |
1,3 |
2 |
1984 |
2,9 |
0,60 |
3,1 |
-0,2 |
3,5 |
-0,6 |
3 |
1985 |
3,5 |
1,50 |
4,4 |
-0,9 |
4,9 |
-1,4 |
4 |
1986 |
5 |
0,80 |
5,8 |
-0,8 |
6,2 |
-1,2 |
5 |
1987 |
5,8 |
2,70 |
7,1 |
-1,3 |
7,4 |
-1,6 |
6 |
1988 |
8,5 |
2,10 |
8,4 |
0,1 |
8,6 |
-0,1 |
7 |
1989 |
10,6 |
4,80 |
9,8 |
0,8 |
9,8 |
0,8 |
8 |
1990 |
15,4 |
-1,70 |
11,1 |
4,3 |
10,9 |
4,5 |
9 |
1991 |
13,7 |
-3,56 |
12,4 |
1,3 |
12,0 |
1,7 |
10 |
1992 |
10,1 |
-2,92 |
13,8 |
-3,6 |
13,1 |
-3,0 |
11 |
1993 |
7,2 |
7,90 |
15,1 |
-7,9 |
14,2 |
-7,0 |
12 |
1994 |
15,1 |
8,15 |
16,4 |
-1,3 |
15,3 |
-0,2 |
13 |
1995 |
23,3 |
3,32 |
17,8 |
5,5 |
16,3 |
6,9 |
14 |
1996 |
26,6 |
-15,59 |
19,1 |
7,5 |
17,4 |
9,2 |
15 |
1997 |
11,0 |
9,83 |
20,4 |
-9,4 |
18,4 |
-7,4 |
16 |
1998 |
20,8 |
12,03 |
21,8 |
-0,9 |
19,4 |
1,4 |
17 |
1999 |
32,9 |
-4,77 |
23,1 |
9,8 |
20,4 |
12,5 |
18 |
2000 |
28,1 |
-10,45 |
24,4 |
3,7 |
21,4 |
6,7 |
19 |
2001 |
17,7 |
- |
25,8 |
-8,1 |
22,3 |
-4,7 |
R2 |
между |
исходным |
ВР (гр.2) и |
69,0 % |
- |
79,0 % |
- |
27
Еще одним приемом приведения ВР к стационарному виду является подбор к исходным данным аналитического уравнения с последующим нахождением разности между фактическими значениями наблюдений и ожидаемыми в соответствии с расчетами на основе созданной модели процесса (см. разд.2.2.2.1).
В нашем случае с помощью программы Excel мы подобрали к данным табл.2.4 два аналитических уравнения тренда. Первое – линейная регрессия вида:
Υ =1,3343* Υt + 0,4184 (см. также разд.5). С ее помощью удается объяснить 69 % (R2 = 0,69) наблюдающейся изменчивости исходного ряда. Второе – степенная функция: Υ =1,9614* Υt0,.8262 , аппроксимирующая исходный ряд еще лучше (R2 =0,79).
Для проверки рядов остатков (гр.6 и гр.8) на стационарность относительно центральной тенденции была произведена разбивка каждого из них на три группы с последующим сравнением первой группы с третьей.
Величина средней для первой группы остатков из гр.6 составила -0,32 (n=5), а для третьей- –1,01 (n=5). Различия в средних между отрезками ряда являются несущественными (t=0,19; df=8, P>0,05 по Приложению 2). Следовательно, удаление линейного тренда действительно позволило преобразовать ряд остатков к стационарному виду.
Аналогично рассмотрим поведение остатков первой и третьей группы из гр.8. Для группы из начала ряда величина средней составила -0,68 (n=5). Для последних пяти членов ряда средняя равна 1,72. И в этом случае различия в средних между группами являются несущественными (t=0,65; df=8, P>0,05 по Приложению 2). Следовательно, ряд остатков, образовавшихся в результате удаления степенного тренда, является стационарным относительно его центральной тенденции.
Таким образом, оба приведенных метода проверки ряда на стационарность и оба метода удаления нециклического тренда с целью преобразования исходного ряда к стационарному виду дают относительно поставленных целей сходные результаты. Отдать предпочтение одному из них не представляется возможным, если не воспользоваться дополнительными соображениями или критериями (например, учесть, что аппроксимация исходной последовательности с помощью степенной функции дает лучшие результаты (R2 выше), чем при использовании линейной).

28
2.2.3. Оценка нормальности распределения наблюдений во временных рядах Иногда нормальное распределение называют гауссовским. Графически его можно
получить, если по оси абсцисс отложить сгруппированные в несколько классов результаты измерений, а по оси ординат – вероятность их возможного появления и соединить соответствующие точки отрезками в виде кривой линии. На рис.3 изображен возможный реальный вариант флуктуации некоторой переменной и его представление в виде кривой распределения, которая визуально очень близка к идеальному графику гауссовского процесса.
Нормальное распределение наблюдений в выборках является достаточно распространенным, о чем и свидетельствует его название. При нормальном распределении в пределах одного стандартного отклонения ( Υ ± σ ) находится 68,28 % всех уровней
ряда, Υ ± 2σ содержит 95,45 %, а Υ ± 3σ включает 99,75 % данных.
Методы сравнения параметров отдельных рядов, основанные на использование нормального распределения, называются параметрическими. Они являются более мощными, чем непараметрические, то есть для доказательства одного и того же утверждения при анализе ВР с нормальным распределением необходимо меньшее число наблюдений, чем при анализе рядов с другим характером распределений. Однако, если применить параметрические критерии к заведомо ненормальному распределению, то можно придти к ошибочным выводам. Ввиду этого возникает задача оценки характера распределения данных в ВР. Подсознательно на первых этапах работы бывает трудно воспринять, что сложные динамические ряды характеризуются достаточно простым графиком, описывающим характер их распределения (рис.3). Тем более невозможно по типу исходного ВР визуально оценить тип распределения данных.
Строгие критерии оценки нормальности (критерии Колмогорова-Смирнова, χ2,
Баррлета и др.) можно найти в специальной литературе /2, 4, 6, 10, 16-19, 22/. Мы ограничимся рассмотрением простого приблизительного приема оценки, использование которого часто является достаточным /6/. Предлагаемый метод основан на нахождении
отношения размаха изменчивости в исследуемом ВР к |
его стандартному отклонению. |
Расчет ведется по формуле: |
|
С = |Р /σ | |
(11) , |
где Р – размах колебаний, то есть значение, полученное путем вычитания минимального наблюдения из максимального; σ - стандартное отклонение ряда. Значения критерия С берутся по их абсолютной величине.