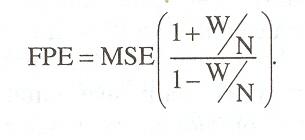Очистка и преобразование базы данных
Предварительное, до подачи на вход сети, преобразование данных с помощью стандартных статистических' приемов может существенно улучшить
как параметры обучения (длительность, сложность), так и работу системы. Например, если входной ряд имеет отчетливый экспоненциальный вид, то после его логарифмирования получится более простой ряд, и если в нем имеются сложные зависимости высоких порядков, обнаружить их теперь будет гораздо легче. Очень часто ненормально распределенные данные предварительно подвергают нелинейному преобразованию; исходный ряд значений переменной преобразуется некоторой функцией, и ряд, полученный на выходе, принимается за новую входную переменную. Типичные способы преобразования - возведение в степень, извлечение корня, взятие обратных величин, экспонент или логарифмов.
для того чтобы улучшить информационную структуру данных, могут оказаться полезными определенные комбинации переменных - произведения, частные и т.д. Например, когда вы пытаетесь предсказать изменения цен акций по данным о позициях на рынке опционов, отношение числа опционов пут (put options, т.е. опционов на продажу) к числу опционов колл (саll options, т.е. опционов на покупку) более информативно, чем оба этих показателя в отдельности. К тому же, с помощью таких промежуточных комбинаций часто можно получить более простую модель, что особенно важно, когда число степеней свободы ограниченно.
Наконец, для некоторых функций преобразования, реализованных в выходном узле, возникают проблемы с масштабированием. Сигмоид определен отрезке [0,1], поэтому выходную переменную нужно масштабировать так, чтобы она принимала значения в этом интервале. Известно несколько способов масштабирования: сдвиг на константу, пропорциональное изменение значений с новым минимумом и максимумом, центрирование путем вычитания среднего значения, приведение стандартного отклонения к единице, стандартизация (два последних действия вместе). Имеет смысл сделать так, чтобы значения всех входных и выходных величин в сети всегда лежали, например, в интервале [0,1] (или [-1,1]), - тогда можно будет без риска использовать любые функции преобразования.
Построение модели
Значения целевого ряда (это тот ряд, который нужно найти, например, доход по акциям на день вперед) зависят от N факторов, среди которых могут быть комбинации переменных, прошлые значения целевой переменной, закодированные качественные показатели.
Оценка качества модели обычно основывается на критерии согласия типа средней квадратичной ошибки (MSE) или квадратного корня из нее (RМSE). Эти критерии показывают, насколько предсказанные значения оказались близки к обучающему, подтверждающему или тестовому множествам.
В линейном анализе временных рядов можно получить несмещенную оценку способности к обобщению, исследуя результаты работы на обучающем множестве (МSЕ), число свободных параметров (w) и объем обучающего множества (N). Оценки такого типа называются информационными критериями (I С) и включают в себя компоненту, соответствующую критерию согласия, и компоненту штрафа, которая учитывает сложность модели. Были предложены следующие информационные критерии: нормализованный (NAIC), нормализованный байесовский (NВIC) и итоговая ошибка прогноза (FPE):
2W
NAlC = In(MSE) + N
2W lnN
NBIC=In(MSE)+ N,