

. Аналіз часових рядів
П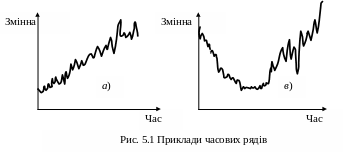 оняття
часового ряду є одним з головних у
сучасній прикладній статистиці. Часовий
ряд є сукупністю
спостережень або вимірів деякої змінної,
що відбувається послідовно з плином
часу. Приклади часових рядів наведені
на рис. 5.1.
оняття
часового ряду є одним з головних у
сучасній прикладній статистиці. Часовий
ряд є сукупністю
спостережень або вимірів деякої змінної,
що відбувається послідовно з плином
часу. Приклади часових рядів наведені
на рис. 5.1.
При дослідженні часових рядів за статистичними методами основну увагу приділяють опису або моделюванню їхньої структури. Подібні моделі застосовують для розв’язання таких задач:
- дослідження природи системи, що генерує часові ряди;
- прогнозування майбутніх значень часового ряду, екстраполяція, передбачення;
- розширення моделей, щоб вони описували динамічні зв’язки між окремими рядами багатовимірного часового ряду та дозволяли оцінювати передатні функції загальної системи
- вироблення стратегії оптимального управління, змін одних регульованих змінних, щоб мінімізувати збурення залежних від них інших змінних.
Можливість прогнозування, розуміння динамічних взаємозв’язків та оптимальне управління мають велике практичне значення. Наприклад, прогнозування збуту є основою розумного планування комерційних операцій; моделі передатних функцій необхідні для покращення проектування і контролю виробничих процесів; стратегії оптимального управління потрібні для регулювання важливіших змінних цих процесів; без прогнозування стану довкілля неможливо своєчасно запровадити ефективні заходи щодо захисту природи.
За класифікацією часові ряди ділять на ряди миттєвих змін та ряди накопичень. Перший клас містить дискретні часові ряди, які можна розглядати як значення неперервних часових рядів в деякі моменти часу. Наприклад, це ряди цін, фондів, обладнання, боргів, фінансових коштів. Другий клас включає ряди, що є сумою або накопиченням значень змінної протягом часу між спостереженнями. Наприклад, це кількість опадів в деякому місяці, вихід продукції за час циклу, викиди шкідливих речовин за рік роботи агрегату; в економіці – це національний доход і інше.
Часовий ряд х(t1), х(t2),…, х(tn) - це спостереження на деякому проміжку часу Т в дискретні моменти t1, t2,…, tn реалізації х(t) випадкового процесу Х(t), t T. Звичайно моменти часу є рівновіддаленими:
ti + 1 – ti = h; і = 1, 2, …; х(tk) = x(k).
Як найпростіші
вибіркові статистичні характеристики
стаціонарного процесу Х(t) за часовим
рядом {х(tk)}
вживають вибіркове середнє
та кореляційну функцію
![]() :
:
![]() ;
;
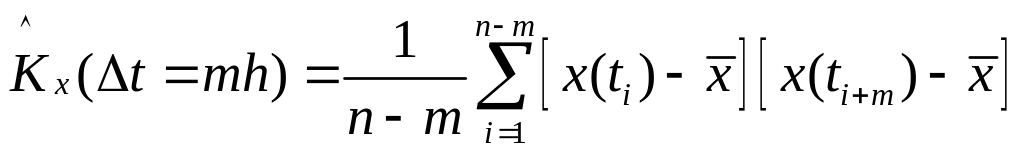 .
.
Якщо Х(t) нестаціонарний процес, то оцінки його характеристик будують за методом рухомого середнього:
![]() ;
;
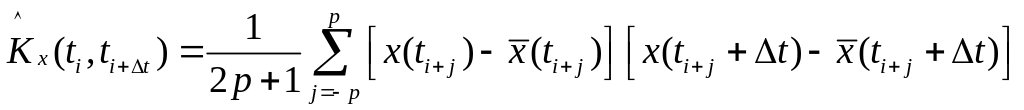 .
.
Важливими характеристиками часових рядів є тренди, сезонні зміни, циклічні компоненти та флуктуації.
Тренд є змінною, що визначає загальний напрямок розвитку, основну тенденцію часових рядів, які розглядаються як ряди динаміки певних процесів. Тренд середньої характеризує зміни середніх значень ряду при збереженні коливань флуктуацій значень ряду навколо середнього. Тренди середнього моделюються детермінованими функціями часу, серед яких найпоширенішими є лінійні х(t) = а + вt; ступеневі х(t) = аtв ; експоненціальні х(t) = аевt, де а і в – деякі параметри.
Другий тип трендів у часових рядах – тренд дисперсії, коли розмах коливань навколо середнього (яке теж може змінюватися) змінюється за розміром. Третій, більш тонкий тип тренду – зміна значущості однієї з компонент, наприклад, зменшення сезонних коливань, або зміна величини кореляції між значеннями ряду. Подібний тип змін важче помітити безпосередньо, але він є важливим при аналізі та прогнозуванні рядів.
Звичайно виразні тренди середнього та сезонність можливо моделювати детермінованими функціями часу. Наприклад, часовий ряд на рис. 5.1(а) можна зображувати у вигляді моделі:
х(t) = а + вt + ε(t),
де а + вt – лінійний тренд;
ε(t) – реалізація випадкового процесу з нульовим середнім.
При наявності циклічних компонент модель часового ряду може мати вигляд:
х(t)
= μ +
![]() [Ajsinωjt
+ Bjcosωjt]
+ ε(t).
[Ajsinωjt
+ Bjcosωjt]
+ ε(t).
Для виявлення трендів використовують різні способи вирівнювання (згладжування), методи регресії випадкових процесів.
Згладжування за методом ковзного усереднення полягає в послідовному усередненні ординат хі = х(tі); і = 1, 2, …, n на деякому інтервалі часу mh; m < n, де m – будь – яке ціле число; зручніше брати m парним. Операція усереднення виконується за формулою:
![]() ;
і = 1, 2, …, n – m,
;
і = 1, 2, …, n – m,
де
![]() - оцінка ординати функції х(t) при (і +
- оцінка ординати функції х(t) при (і +
![]() )
– тому спостереженні.
)
– тому спостереженні.
Раціональний
вибір значення m визначає якість
відділення високочастотного шуму від
більш низькочастотної функції х(t).
Заниження mh призводить до недостатнього
вирівнювання часового ряду, а завищення
– до викривлення х(t) і втрати частини
ординат х(ti)
з номерами і = 0, 1, 2, …,
![]() на початку ряду та і =
на початку ряду та і =
![]() в кінці ряду. Звичайно приймають m = 2 ÷
4.
в кінці ряду. Звичайно приймають m = 2 ÷
4.
Наприклад, при m = 4 для і = 0 та і = 1 отримуємо:
![]() ;
;
![]() .
.
Сутність методу згладжування четвертими різницями полягає в апроксимації за допомогою методу найменших квадратів кожних п’яти сусідніх значень хі параболою другого порядку. За цім методом обчислюється різниця (поправка) між параболою і значенням середньої з п’яти ординат хі , потім здійснюється зсув управо на один номер і знову визначається поправка для значення функції хі+1. Величина цієї поправки пропорційна центральній четвертій різниці функції хі , яку обчислюють за формулою:
δ4хі = хі – 2 – 4хі –1 + 6хі – 4хі + 1 + хі ; і = 2, 3, …, n – 2
Значення оцінки функції х(tі) визначають за формулою:
![]() .
.
Для запобігання
втрати чотирьох значень
![]() при і = 1, 2, n – 1, n використовують формули:
при і = 1, 2, n – 1, n використовують формули:
![]() ;
;
![]() ;
;
![]() ;
;
![]() ,
,
де
![]() - центральна третя різниця:
- центральна третя різниця:
![]() ; μ = 1, 2,…, n – 2.
; μ = 1, 2,…, n – 2.
Операцію згладжування х(t) можна виконувати декілька разів, при цьому ординати хі* , отримані в попередньому циклі, розглядають як вихідні значення хі .
Метод згладжування рядами Фур’є заснований на різній швидкості зменшення коефіцієнтів розкладення Фур’є для функцій з різними аналітичними властивостями. За цим методом зі значень функції х(tі) ; і = 0, 1, …, n відіймають значення лінійного двочлена α + βtі , тобто виконують операцію:
![]() х(tі)
- α - βtі
.
х(tі)
- α - βtі
.
Коефіцієнти двочлену α та β знаходять з системи рівнянь, згідно якої значення лінійного двочлена і функції х(t) на початку і в кінці часового ряду співпадають:
![]() х(0)
- α – β*0 = 0;
х(0)
- α – β*0 = 0;
![]() х(nh)
– α – βnh = 0 .
х(nh)
– α – βnh = 0 .
Отриману
функцію
![]() ; і = 0, 1, 2,…, n розкладають в ряд за синусами:
; і = 0, 1, 2,…, n розкладають в ряд за синусами:
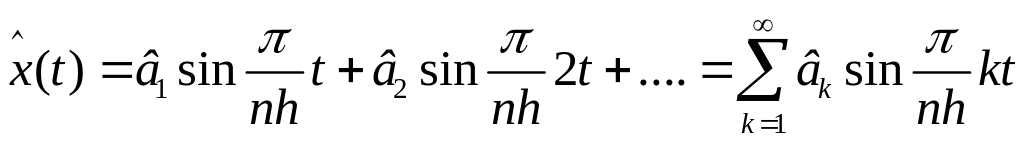 ,
,
де
 .
.
З аналізу величини і знаків коефіцієнтів вк визначають кількість членів ряду m і дають оцінку функції х(t):
![]() ; 0 ≤ t ≤ nh
; 0 ≤ t ≤ nh
За методикою згладжування поліномами Чебишева інтервал часу [ 0; nh ], в якому змінюється функція х(tі); і = 0, 1, 2,…, n центрується і нормується до відрізку [ - 1; + 1 ] за допомогою перетворення:
![]() ,
,
де n – парне
число; g = i -
![]() ; t0
=
; t0
=
![]() ;
;
![]() .
.
Потім
зі значень х(![]() відіймають лінійний двочлен α + β
відіймають лінійний двочлен α + β![]() :
:
![]() =
х(
- α - β
,
=
х(
- α - β
,
де α і β знаходять з рівнянь:
х(1) - α - β = 0;
х( - 1) - α + β = 0.
Отриману
функцію
розкладають в парну Ug
і непарну послідовності Vg
, значення Ug
та Vg
перемножують на відповідні елементи
матриці
![]() ;
ці добутки складають і знаходять
коефіцієнти розкладення Ск
з парними і непарними номерами к.
Як і для розкладення функції в ряд Фур’є,
перші, най більші за модулем значення
С0,
С1,
С2,…,
Сm
відносять до розкладення х(t), а коефіцієнти
Сm+1,
Cm+2,
… до розкладення шуму ε(t). Тому можна
записати:
;
ці добутки складають і знаходять
коефіцієнти розкладення Ск
з парними і непарними номерами к.
Як і для розкладення функції в ряд Фур’є,
перші, най більші за модулем значення
С0,
С1,
С2,…,
Сm
відносять до розкладення х(t), а коефіцієнти
Сm+1,
Cm+2,
… до розкладення шуму ε(t). Тому можна
записати:
 ;
;
![]() ,
,
або, якщо здійснити перехід до натурального аргументу t, після перетворень отримуємо:
х*(t) = а0 + a1t + a2t2 +…+amtm ; 0 ≤ t ≤ nh ,
де а0 , a1 , a2 ,…, am – коефіцієнти;
Тк+1![]() = cos k arccos
= cos k arccos
![]() ;
к = 0, 1, 2, 3,…. – поліноми Чебишева першого
роду, які знаходять за рекурентною
формулою:
;
к = 0, 1, 2, 3,…. – поліноми Чебишева першого
роду, які знаходять за рекурентною
формулою:
![]() ; к = 1, 2, 3,…..
; к = 1, 2, 3,…..
при початкових умовах:
![]() ;
;
![]() ;
;
Як вже
зазначалося, сутністю аналізу часових
рядів є використання наявних в момент
часу t спостережень часового ряду для
прогнозування його значень в деякий
момент часу t + τ в майбутньому. Величина
τ прогнозу на певний інтервал часу
наперед називається часом
упередження і вона
залежить від конкретної проблеми.
Функція
![]() ,
що дає в момент t прогноз величини х(t +
τ) з упередженням τ, називається прогнозною
функцією в момент t.
,
що дає в момент t прогноз величини х(t +
τ) з упередженням τ, називається прогнозною
функцією в момент t.
Ціллю прогнозування є побудова такої прогнозної функції, що мінімізує середньоквадратичну помилку прогнозування для заданого упередження τ:
![]() → min.
→ min.
Точність прогнозування характеризує ризик, який пов’язаний з рішеннями, прийнятими на основі цього прогнозування. Вона виражається імовірнісними межами, що лежать по обидва боки від прогнозного значення і відповідають певному заданому рівню імовірності, наприклад, 80% або 95%.
На рис. 5.2 поданий прогноз значень часового ряду за результатами спостережень до моменту t на час упередження τ разом з 80% - ними імовірнісними межами.
До найпростіших моделей часових рядів належать моделі авторегресії та рухомого середнього.
Випадковий процес х(t) з дискретним часом називається процесом авторегресії порядку Р; р N, якщо він описується різницевим рівнянням:
х(t) + а1х(t - 1) +…+арх(t – р) = ε(t),
де ε(t) – білий шум, тобто чисто випадковий процес.

Якщо φ(В) – поліном вигляду:
φ(В) = 1 + а1В +…+арВр,
а В – оператор зсуву назад Вх(t) = х(t - 1), то наведена модель має вигляд:
φ(В)х(t) = ε(t).
Це можна отримати з наступних перетворень:
х(t) + а1х(t
- 1) +а2х(t
- 2) +а3х(t
- 3) +…+арх(t
– р) = х(t)![]() ,
або, зважаючи на те, що
,
або, зважаючи на те, що
![]() ,
отримуємо:
,
отримуємо:
х(t)( 1 + а1В +а2В2 +а3В3 +…+арВр) = φ(В)х(t) = ε(t).
Процес х(t) називається процесом рухомого середнього порядку q, якщо він описується моделлю:
х(t) = в0ε(t) + в1ε(t - 1) + в2ε(t -2) +…+ вqε(t -q) ,
де в0 , в1 , в2 ,…, вq – деякі числові параметри, тобто:
х(t) = ψ(В)ε(t),
де поліном ψ(В) має вигляд:
ψ(В) = в0 + в1В + в2В2 + …+ вqBq .
Оператор зсуву:
![]() .
.
Комбінація моделей авторегресії і рухомого середнього дає більш загальну модель процесу порядку (p, q), яка задається різницевим рівнянням:
х(t) + а1х(t - 1) +а2х(t - 2) +а3х(t - 3) +…+арх(t – р) =
в0ε(t) + в1ε(t - 1) + в2ε(t -2) +…+ вqε(t -q) ,
або рівнянням:
φ(В)х(t) = ψ(В)ε(t).
Значна кількість часових рядів, що зустрічаються у промисловості, виявляють нестаціонарний характер. Для їх дослідження застосовують нестаціонарні та нелінійні моделі часових рядів. Якщо властивості часового ряду у деякому розумінні є однорідними (наприклад, рівень, навколо якого відбуваються флуктуації є різним в різні моменти часу, але поведінка рядів із урахуванням різниці рівня схожа), то використовують модель часових рядів зі стаціонарними d – різницями, що описується такою різницевою схемою:
У(t)
=
![]() x(t)
; φ(В)У(t) = ψ(В)ε(t),
x(t)
; φ(В)У(t) = ψ(В)ε(t),
де - оператор різниці x(t) = x(t) – x(t –1);
φ nf ψ - поліноми ступенів р і q.
Розповсюдженість лінійних моделей часових рядів пов’язана з порівняльною простотою користування ними. Проте такі моделі не завжди адекватно описують випадкові механізми, що генерують часові ряди. Серед більш загальних моделей часових рядів перспективними є білінійні моделі.
Одновимірна білінійна модель процесу х(t) описується різницевим рівнянням вигляду:
![]() ,
,
де ε(t) – білий шум;
аj, вj, cij – параметри моделі;
p, q, r, s – числа, які визначають порядок моделі.
Узагальненням
цієї моделі є багатовимірна
білінійна модель, що
дозволяє вивчати векторні часові ряди
та структури зв’язків між окремими
компонентами. Ця модель задає n – вимірний
випадковий процес х(t)=![]() ,
компоненти якого описуються різницевими
рівняннями вигляду:
,
компоненти якого описуються різницевими
рівняннями вигляду:
![]() ,
,
де
![]() - векторний білий шум.
- векторний білий шум.
Загальна схема використання моделі часового ряду наступна.
Спочатку обирають клас моделей для досягнення мети. Оскільки цей клас досить великий, використовують спочатку більш грубі методи ідентифікації. Потім пробну модель припасовують до наявних даних шляхом оцінювання її параметрів різними методами, тобто, виконується налагоджування моделі до наявних даних. Після цього виконується діагностична перевірка адекватності моделі, виявляються можливі дефекти підгонки та їхні причини. Якщо дефекти не виявлені або незначні, модель готова до використання. В разі наявності суттєвих дефектів етапи повторюють з урахуванням отриманих результатів аналізу.