

. Кореляційний аналіз дослідних даних
Кореляційний аналіз є складовою частиною математичного апарату обробки експериментальних даних. За його допомогою оцінюють зв’язок між змінними, відсіюють зв’язки, що є незначущими, або несуттєві фактори.
Вибірковий коефіцієнт кореляції визначають за формулою:
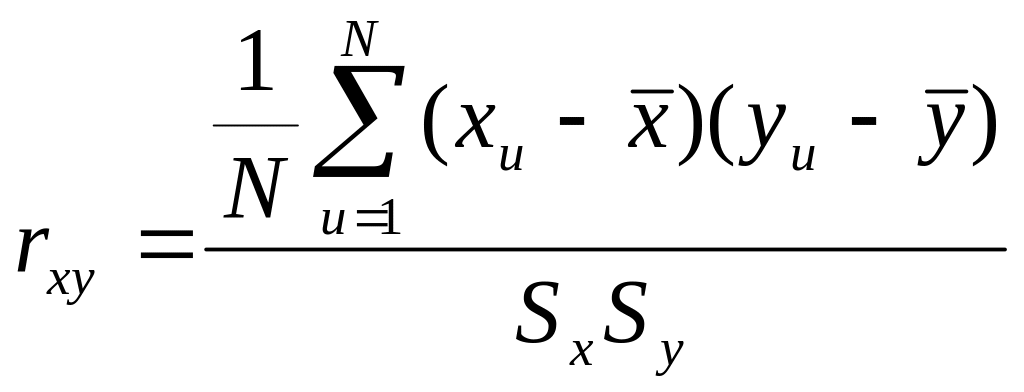 ,
,
де N – кількість дослідів;
![]() - оцінки математичного
сподівання змінних х
та у;
- оцінки математичного
сподівання змінних х
та у;
Sx , Sy – оцінки середньоквадратичних відхилень цих змінних.
Для перевірки значимості коефіцієнту кореляції використовують критерій Стьюдента, тобто, знаходять його розрахункове значення tр і порівнюють з табличним tт . Розрахунковий t – критерій:
tр
=
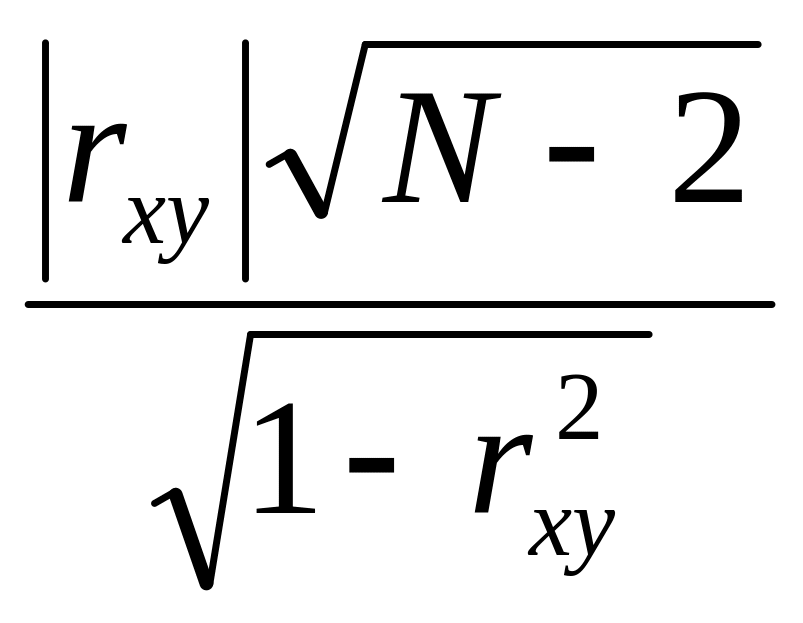 .
.
Табличне значення tт знаходять для числа ступенів свободи f = N – 2 і рівня значимості q = 0,05 (або заданого). У разі виконання умови: tр > tт лінійний зв’язок між х і у існує.
Приклад.
В результаті досліджень впливу питомої
витрати пари на розпил мазуту в форсунки
(х1,
![]() )
і продуктивності обертової печі для
обпалу вапняку (х2,
)
на питому витрату палива (у,
)
і продуктивності обертової печі для
обпалу вапняку (х2,
)
на питому витрату палива (у,
![]() )
отримані дані, які наведені в табл. 4.3.
Знайти коефіцієнти кореляції між
факторами х1
, х2
та змінною у,
а також оцінити їх значимість.
)
отримані дані, які наведені в табл. 4.3.
Знайти коефіцієнти кореляції між
факторами х1
, х2
та змінною у,
а також оцінити їх значимість.
Таблиця 4.3
Вихідні дані для розрахунку коефіцієнтів кореляції
№№ дослідів |
х1 |
х2 |
У |
1 |
0,69 |
29 |
50,5 |
2 |
0,66 |
91 |
30,9 |
3 |
0,45 |
82 |
37,4 |
4 |
0,49 |
99 |
37,8 |
5 |
0,48 |
148 |
19,7 |
6 |
0,48 |
165 |
15,5 |
7 |
0,41 |
133 |
49,0 |
Σ |
3,66 |
747 |
240,8 |
Рішення. З даних таблиці знаходимо:
- середні
значення параметрів
![]() = 0,523;
= 0,523;
![]() = 106,71;
= 106,71;
![]() = 34,4;
= 34,4;
- їх середньоквадратичні відхилення Sx1 = 0,1076; Sx2 = 46,096; Sу = 13,407;
- вибіркові коефіцієнти кореляції rx1 x2 = - 0,585; rx2 у = - 0,605; rx1 у = + 0,166;
- розрахункові значення критерію Стьюдента tp1 = 1,61; tp2 = 0,38; tp3 = 1,70.
Табличне значення t - критерію для числа ступенів свободи f = 7 – 2 =5 і рівня значимості q = 0,05 складає tт = 2,37. Оскільки для всіх випадків tpі < tт (і = 1, 2, 3), з імовірністю 95% можна зробити висновок, що лінійного зв’язку між змінними немає.
Апроксимація експериментальних даних
Шляхом апроксимації результатів експерименту можуть бути отримані різні функціональні залежності – поліноміальні, ступеневі, логарифмічні і т. д.
Основним математичним апаратом для отримання апроксимаційних моделей є метод найменших квадратів. Регресивний аналіз звичайно проводять за результатами пасивного або неспланованого активного експерименту. Основними передумовами регресивного аналізу є наступні.
1. Вихідна змінна об’єкту дослідження є випадковою величиною з нормальним законом розподілу;
2. Кореляція між вхідними змінними відсутня;
3. Дисперсія вихідної змінної не залежить від її абсолютної величини, тобто, дисперсії вихідної змінної є однорідними в будь – який точці факторного простору;
4. Об’єкт дослідження позбавлений динамічних властивостей.
Рівняння лінійної вибіркової регресії має вигляд:
![]() =
вх,
=
вх,
де
![]() - відхилення розрахункового значення
вихідного параметра
- відхилення розрахункового значення
вихідного параметра
![]() від середнього за вибіркою
;
від середнього за вибіркою
;
![]() - відхилення вхідної змінної
Х від її середнього вибіркового значення
;
- відхилення вхідної змінної
Х від її середнього вибіркового значення
;
в – вибірковий коефіцієнт регресії, який визначають за формулою:
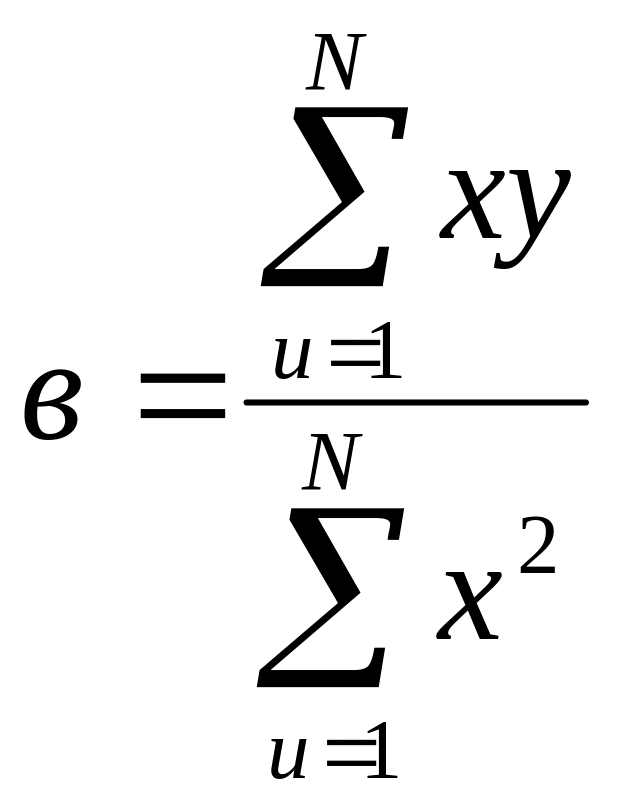 ,
,
де
![]() - відхилення вибіркового значення
вихідного параметру У від середнього
;
- відхилення вибіркового значення
вихідного параметру У від середнього
;
N – кількість дослідів (спостережень, вимірів).
Тобто, рівняння регресії можна записати у вигляді:
![]()
Для оцінки
ступеня згоди лінії регресії з дослідними
даними визначають відхилення від
регресії dху
=
![]() .
Величина
.
Величина
![]() є основою для оцінки помилки, яка виникає
при виборі лінії регресії. Оскільки в
розрахунку використовуються дві середні
величини (
та
),
то число ступенів свободи дорівнює (N –
2). Тоді середній квадрат відхилень від
регресії і вибіркове стандартне
відхилення коефіцієнту регресії:
є основою для оцінки помилки, яка виникає
при виборі лінії регресії. Оскільки в
розрахунку використовуються дві середні
величини (
та
),
то число ступенів свободи дорівнює (N –
2). Тоді середній квадрат відхилень від
регресії і вибіркове стандартне
відхилення коефіцієнту регресії:
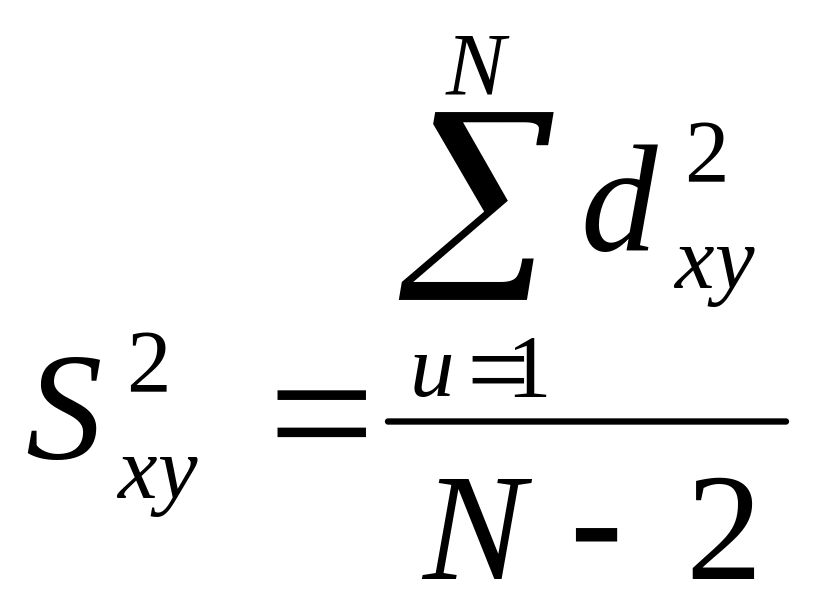 ;
;
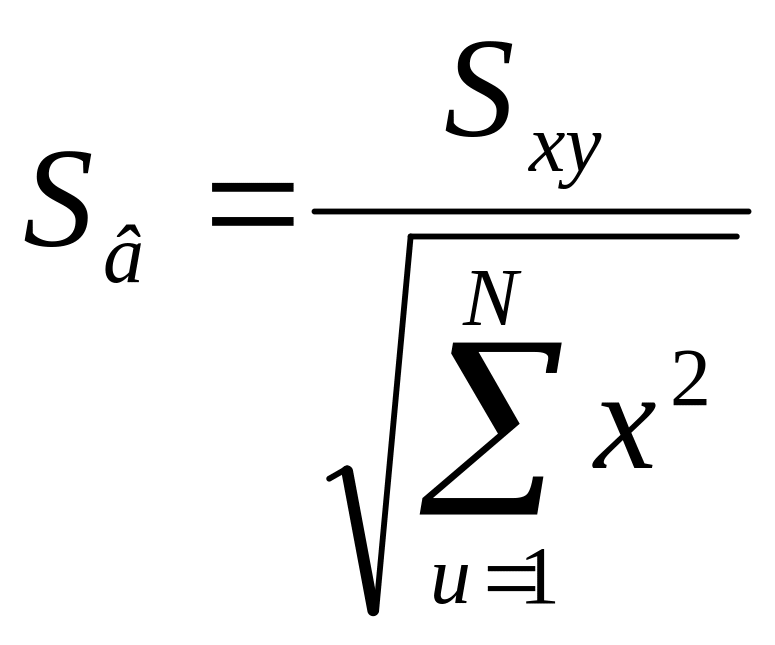 .
.
Критерій
суттєвості для коефіцієнту в
визначають за формулою: tp
=
![]() та порівнюють його з табличним значенням
t – критерію для числа ступенів свободи
f = N –2 і заданого рівня значимості q. За
умови tp
≥ tт
коефіцієнт в
є значимим.
та порівнюють його з табличним значенням
t – критерію для числа ступенів свободи
f = N –2 і заданого рівня значимості q. За
умови tp
≥ tт
коефіцієнт в
є значимим.
Приклад.
Досліджувався вплив продуктивності
агрегату Х,
![]() на викиди пилу з нього У,
на викиди пилу з нього У,
![]() ;
результати вимірів наведені в табл.
4.4. Знайти залежність між цими параметрами
у вигляді лінійної функції.
;
результати вимірів наведені в табл.
4.4. Знайти залежність між цими параметрами
у вигляді лінійної функції.
Таблиця 4.4
Результати вимірів
№№ вимірів |
1 |
2 |
3 |
4 |
5 |
Х |
35 |
45 |
55 |
65 |
75 |
У |
114 |
124 |
143 |
158 |
166 |
Рішення. Середні значення параметрів:
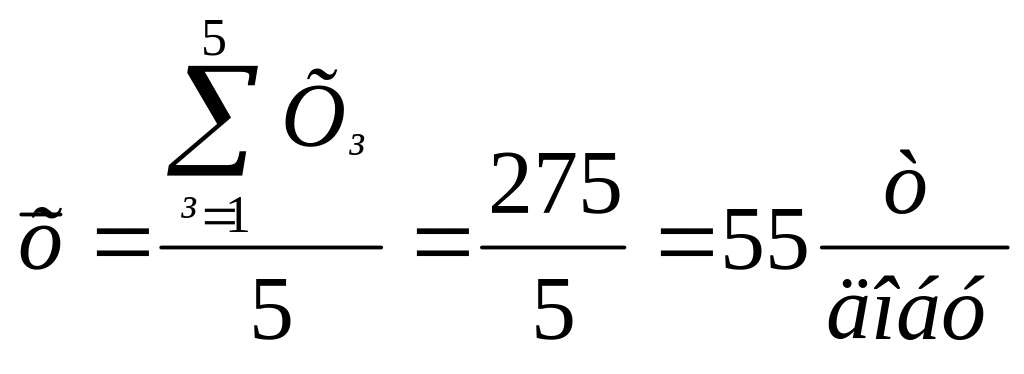 ;
;
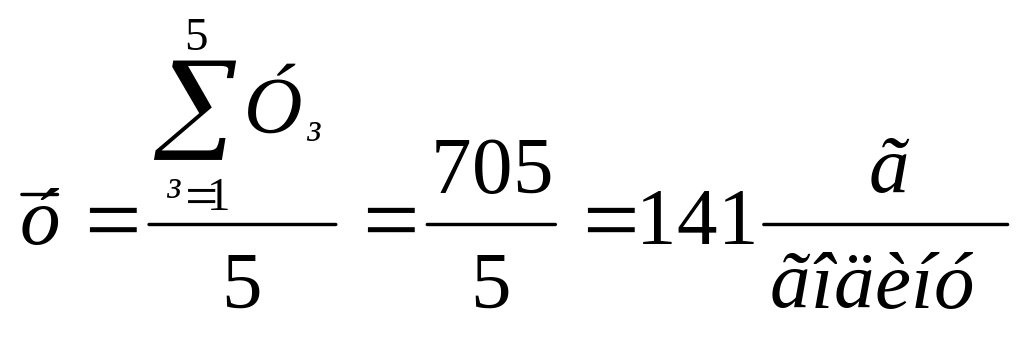 .
.
Результати проміжних розрахунків зводимо в табл. 4.5
Таблиця 4.5
Розрахункові параметри
№№ |
Х - |
У - |
(Х - )2 |
(У - )2 |
(Х- )* (У - ) |
|
|
(У- )2 |
1 |
- 20 |
- 27 |
400 |
729 |
540 |
113,4 |
0,6 |
0,36 |
2 |
- 10 |
- 17 |
100 |
289 |
170 |
127,2 |
- 3,2 |
10,24 |
3 |
0 |
2 |
0 |
4 |
0 |
141,0 |
2,0 |
4,0 |
4 |
10 |
17 |
100 |
289 |
170 |
154,8 |
3,2 |
10,24 |
5 |
20 |
25 |
400 |
625 |
500 |
168,6 |
- 2,6 |
6,76 |
Σ |
0 |
0 |
1000 |
1936 |
1380 |
|
0 |
31,60 |
Вибірковий
коефіцієнт регресії:
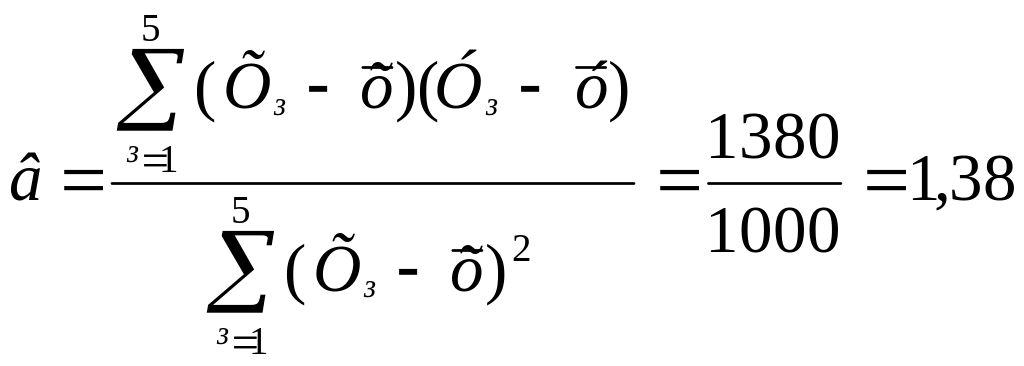 .
.
В початкових одиницях рівняння регресії має вигляд:
![]() -
-
![]() = в(Х -
= в(Х -
![]() );
-
141 = 1,38(Х - 55);
= 65,1 + 1,38Х,
);
-
141 = 1,38(Х - 55);
= 65,1 + 1,38Х,
![]() .
.
Для оцінки ступеня згоди лінії регресії з даними вимірів визначаємо , (У - ), (У - )2, значення яких наведені в табл. 4.5, число ступенів свободи f = 5 – 2 = 3, середній квадрат відхилень і стандартне відхилення від регресії:
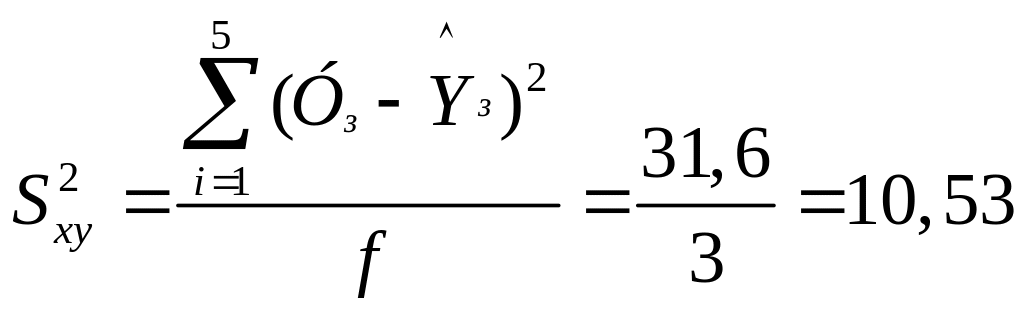 ;
Sxy =
3,24.
;
Sxy =
3,24.
Вибіркове стандартне відхилення коефіцієнта регресії та розрахунковий критерій Стьюдента для нього:
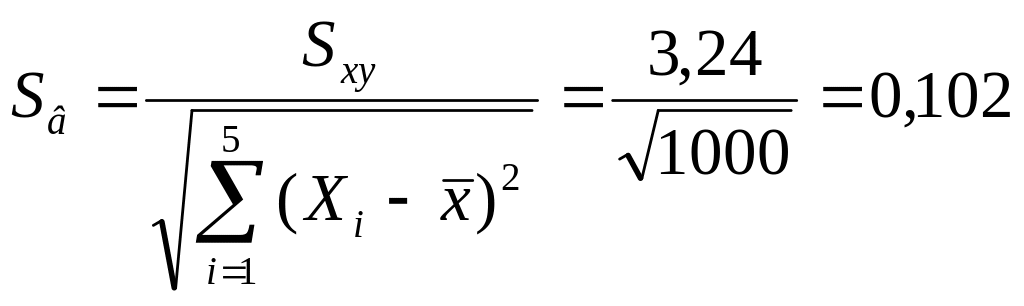 ;
;
![]() .
.
Табличний критерій Стьюдента для f = 3 i q = 5% складає tт = 3,18, що значно перевищує розрахункову величину. Тому коефіцієнт регресії є значимим.
Рівняння множинної регресії має вигляд:
![]() ,
,
де в1 , в2 ,…, вn – коефіцієнти часткової регресії, які визначають за методом найменших квадратів з системи нормальних рівнянь. Для двох вхідних факторів об’єкту вона має вигляд:
![]()
![]()
Рішення цієї системи відносно коефіцієнтів часткової регресії:

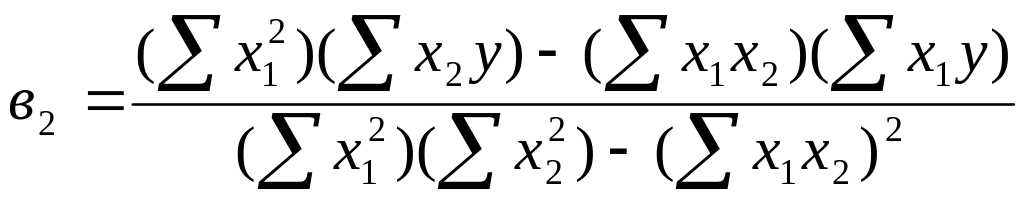
Перевірку значимості коефіцієнтів часткової регресії виконують в наступному порядку:
- обчислюють
відхилення вибіркових значень У від
розрахункових
:
dу =
У -
,
знаходять квадрати dy2
та суму квадратів цих відхилень від
лінії регресії
![]() ;
;
- оцінюють середній квадрат відхилень від регресії шляхом ділення на число ступенів свободи f ( в даному випадку – це кількість дослідів N мінус три ступіні на середні величини , , ) та визначають середньоквадратичне відхилення:
![]() ;
;
- розраховують вагові коефіцієнти:
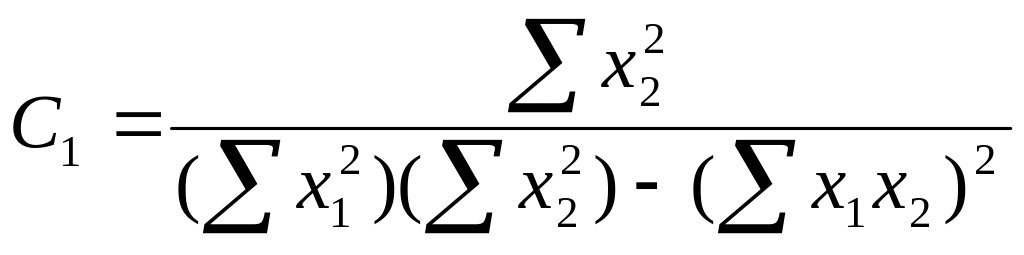 ;
;
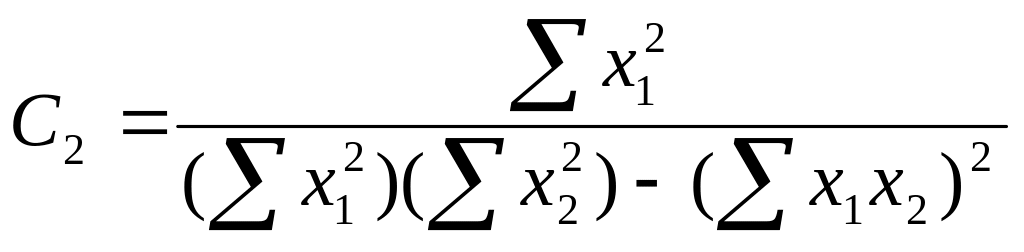
та вибіркові стандартні відхилення коефіцієнтів регресії:
![]() ;
;![]() ;
;
- визначають
розрахункові значення критерію Стьюдента
t1 =
![]() ;
t2 =
;
t2 =
![]() та порівнюють їх з табличними для числа
ступенів свободи (N – 3) і заданого рівня
значимості q. Якщо t1
(t2) >
tт ,
то відповідний коефіцієнт в1
(або в2)
є значимим.
та порівнюють їх з табличними для числа
ступенів свободи (N – 3) і заданого рівня
значимості q. Якщо t1
(t2) >
tт ,
то відповідний коефіцієнт в1
(або в2)
є значимим.
Приклад. На печі по виробництву вапна досліджувався вплив вологості Х1,% та середнього розміру шматків Х2, мм вапняку на питому витрату палива У, . За даними табл. 4.6 отримати залежність між цими параметрами.
Таблиця 4.6
Результати дослідів
№№ дослідів |
Х1,% |
Х2, мм |
У, |
1 |
0,4 |
53 |
64 |
2 |
0,4 |
23 |
60 |
3 |
3,1 |
19 |
71 |
4 |
0,6 |
34 |
61 |
5 |
4,7 |
24 |
54 |
6 |
1,7 |
65 |
77 |
7 |
9,4 |
44 |
81 |
8 |
10,1 |
31 |
93 |
9 |
11,6 |
29 |
93 |
10 |
12,6 |
58 |
51 |
11 |
10,9 |
37 |
76 |
12 |
23,1 |
46 |
96 |
13 |
23,1 |
50 |
77 |
14 |
21,6 |
44 |
93 |
15 |
23,1 |
56 |
95 |
16 |
1,9 |
36 |
54 |
17 |
26,8 |
58 |
168 |
18 |
29,9 |
51 |
99 |
Рішення. Середні значення параметрів:
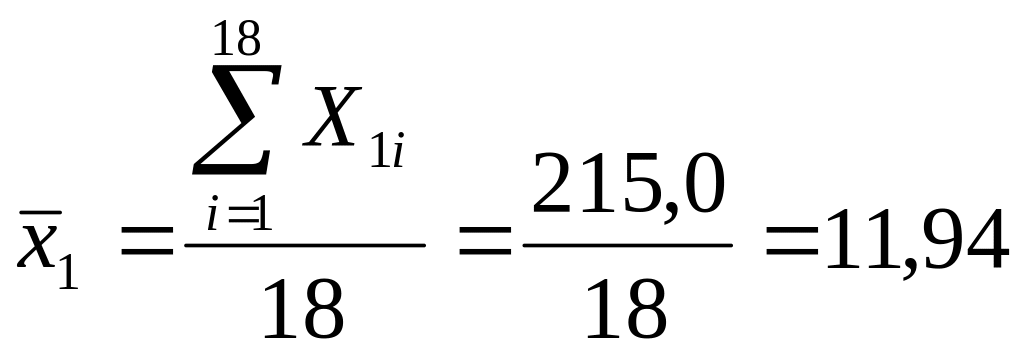 ;
;
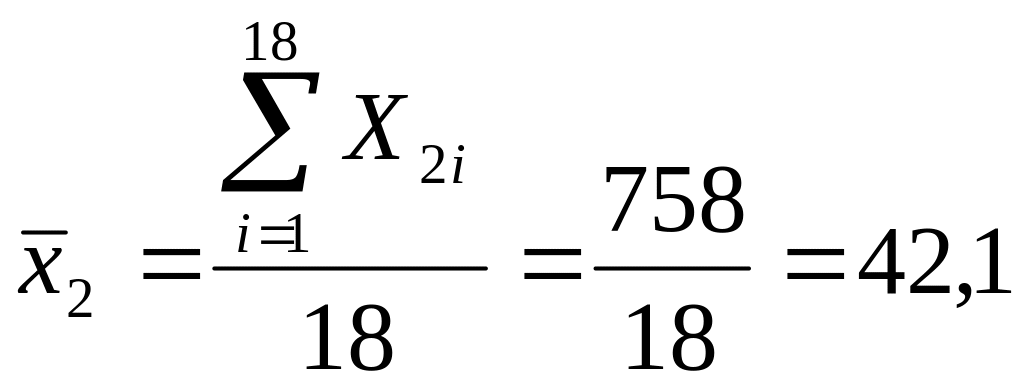 ;
;
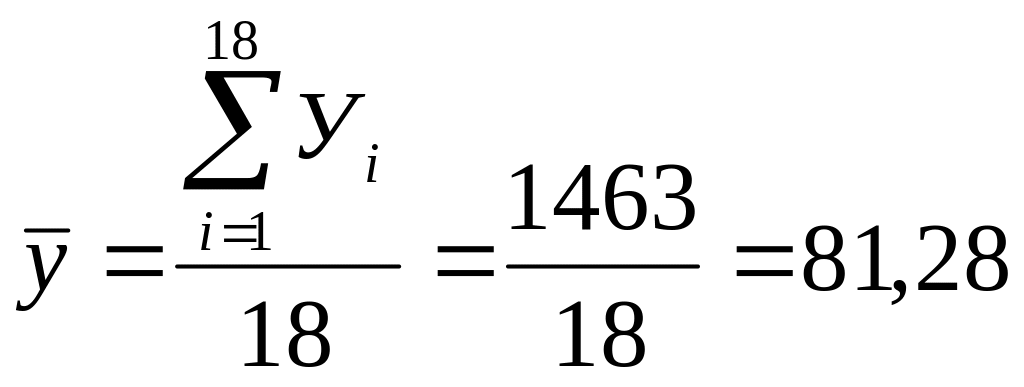
Характеристики відхилень від середніх:
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
Коефіцієнти часткової регресії:
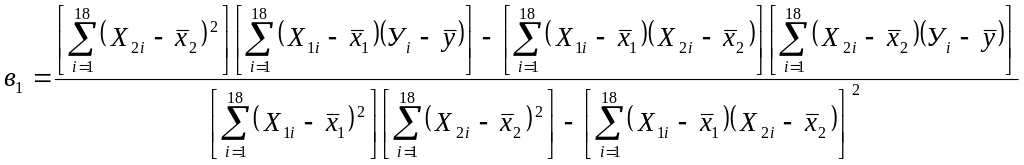 =
=
![]() ;
;
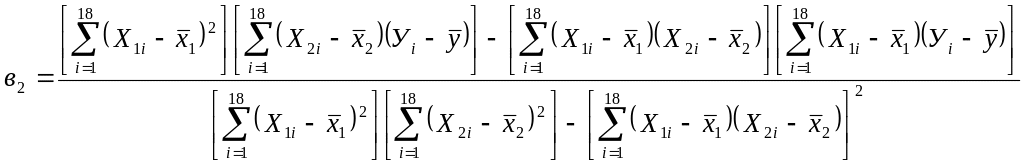 =
=
![]()
Рівняння регресії:
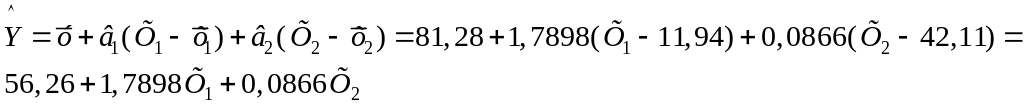
Для перевірки
значимості коефіцієнтів розраховуємо
![]() ,
(Уі
-
)
(табл. 4.7).
,
(Уі
-
)
(табл. 4.7).
Таблиця 4.7
Прогнозована питома витрата палива та відхилення дослідних даних
№№ дослідів |
|
(Уі - ) |
1 |
61,6 |
2,4 |
2 |
59,0 |
1,0 |
3 |
63,4 |
7,6 |
4 |
60,3 |
0,7 |
5 |
66,7 |
- 12,7 |
6 |
64,9 |
12,1 |
7 |
76,9 |
4,1 |
8 |
77,0 |
16,0 |
9 |
79,6 |
13,4 |
10 |
83,8 |
- 32,8 |
11 |
79,0 |
- 3,0 |
12 |
101,6 |
- 5,6 |
13 |
101,9 |
- 24,9 |
14 |
98,7 |
- 5,7 |
15 |
102,4 |
- 7,4 |
16 |
62,8 |
- 8,8 |
17 |
109,2 |
58,8 |
18 |
114,2 |
- 15,2 |
Сума квадратів відхилень від регресії складає:
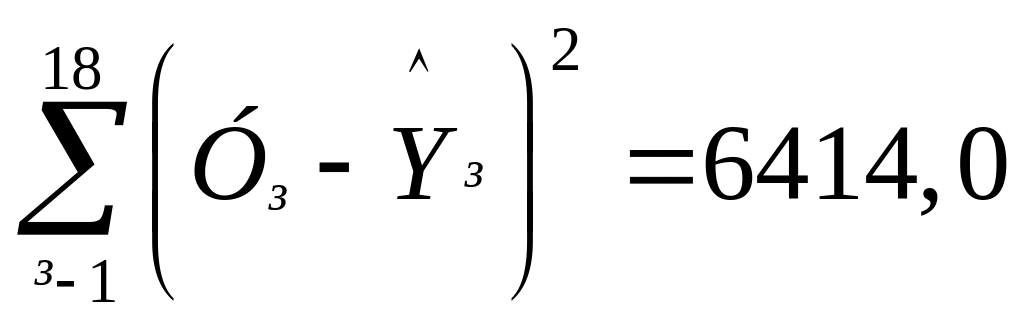 .
.
Середній квадрат відхилень:
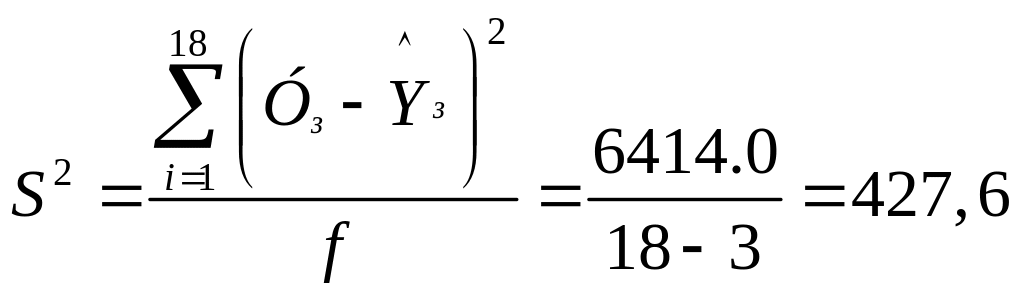 .
.
Вагові коефіцієнти:
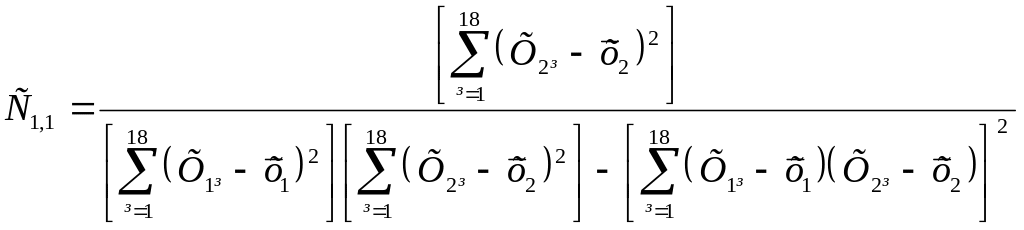 =
=
![]() ;
;
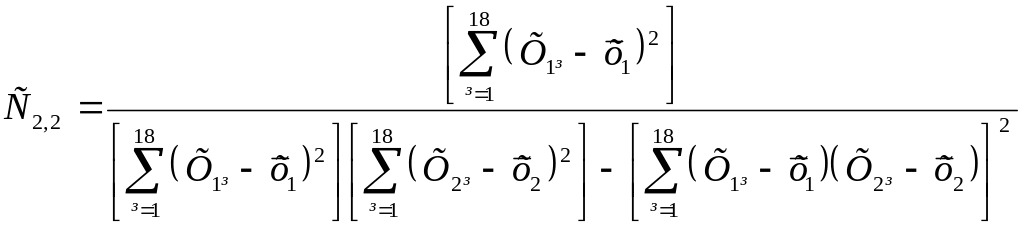 =
=
![]() .
.
Вибіркові стандартні відхилення коефіцієнтів регресії:
Sв12 = С11S2 = 0,0007249*427,6 = 0,310; Sв1 = 0,557;
Sв22 = С22S2 = 0,0004027*427,6 = 0,1722; Sв2 = 0,415.
Розрахункове значення t – критерію для коефіцієнтів:
![]() ;
;
![]() .
.
Оскільки табличне значення критерію Стьюдента для f = 18 – 3 = 15 і q = 5% складає tт = 2,13, то коефіцієнт в1 є значимим, а в2 – незначущим.
Таким чином, вологість сировини суттєво впливає на питому витрату палива, а впливу її гранулометричного складу на енерговитрати за дослідними даними не виявлено.
Збільшення числа змінних призводить лише до ускладнення обчислювання. Наприклад, для трьох незалежних змінних Х1, Х2, Х3 і однієї залежної У рівняння регресії має вигляд:
![]()
і коефіцієнти регресії визначають з системи рівнянь:
![]() ;
;
![]() ;
;
![]() .
.
Для створення криволінійної регресивної моделі використовують два підходи. При першому будують графіки дослідних даних спочатку з застосуванням рівномірних шкал по осях координат. Якщо на графіку не отримана лінійна залежність, починають послідовно вибирати функціональні шкали по одній або по двох осях координат. Для цього використовують логарифмічні шкали. Наприклад, якщо має місце експонентна залежність вигляду: W = ABХ, то шляхом логарифмування цього рівняння можна отримати рівняння прямої лінії:
LnW = lnA + ХlnB або У = а + вХ.
Цей спосіб
використання логарифму замість самої
величини називають способом
спрямлення. Інколи для
спрямлення використовують інші функції,
наприклад,
![]() ;
;
![]() і т. д.
і т. д.
Приклад. В табл. 4.8 наведені результати експериментальних досліджень впливу ступеня збагачення повітря киснем на концентрацію оксидів азоту в продуктах згоряння палива. Знайти залежність між вмістом кисню в окислювачі Х, % і концентрацією NOx в продуктах згоряння У, .
Таблиця 4.8
Результати експериментів
№№ дослідів |
Х,% |
У,
|
1 |
21 |
3 |
2 |
23 |
8 |
3 |
25 |
18 |
4 |
27 |
43 |
5 |
29 |
110 |
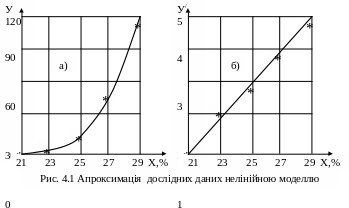
Рішення. Для вибору виду апроксимаційної моделі будуємо графік У = f(Х) в рівномірних шкалах по осях координат (рис. 4.1а). Оскільки отримана залежність має відверто нелінійний характер, приймемо в якості апроксимуючої моделі рівняння:
У = аевХ.
Логарифмуванням цього рівняння отримуємо:
lnУ = lna + вХ; У/ = а/ + вХ.
Перетворені дані зводимо до табл. 4.9 і на рис. 4.1б будуємо залежність У/ = f(X), яка виявилася близькою до лінійної. Тому виконуємо розрахунки для лінійної регресії.
Таблиця 4.9
Розрахункові дані до апроксимації нелінійною моделлю
№ |
Х |
У/ |
Х- |
У/
-
|
(Х- )* (У/ - ) |
(Х- )2 |
|
|
1 |
21 |
1,0986 |
-4 |
-1,80742 |
7,22968 |
16 |
1,1289 |
9,18 |
2 |
23 |
2,0794 |
-2 |
-0,82662 |
1,65324 |
4 |
2,01746 |
38,365 |
3 |
25 |
2,8904 |
0 |
-0,01562 |
0 |
0 |
2,90602 |
2,439 |
4 |
27 |
3,7612 |
2 |
0,85518 |
1,71036 |
4 |
3,79458 |
11,142 |
5 |
29 |
4,7005 |
4 |
1,79448 |
7,17792 |
16 |
4,68314 |
3,013 |
Σ |
125 |
14,5301 |
0 |
0 |
17,7712 |
40 |
|
64,138 |
Середні значення параметрів:
![]() ;
;
![]()
Вибірковий коефіцієнт регресії:
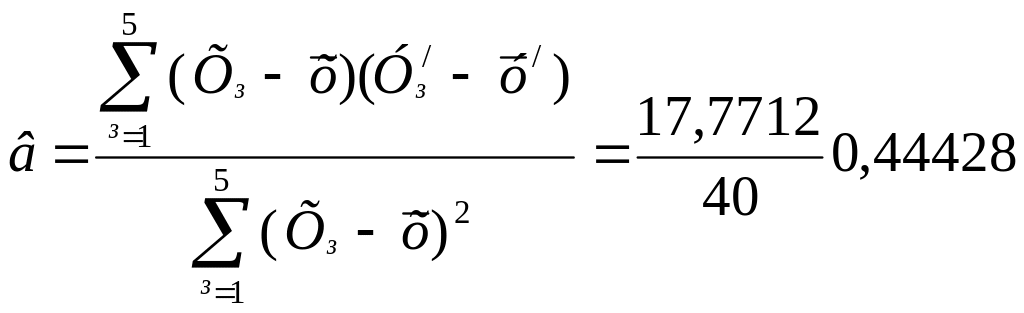
Рівняння регресії:
![]() ;
-
2,90602 = 0,44428(Х – 25);
;
-
2,90602 = 0,44428(Х – 25);
= 0,44428Х – 8,20098
Середній квадрат відхилень та середньоквадратичне відхилення:
 ;
S = 0,0462374
;
S = 0,0462374
Вибіркове стандартне відхилення коефіцієнта регресії та розрахункове значення t – критерію для нього:
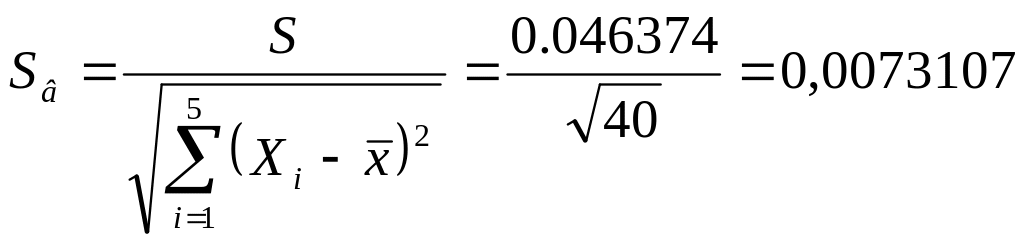 ;
;
![]()
Отримане значення tр значно більше tт = 3,18 для f = 3 i q = 5%, тобто в є значимим.
Шляхом потенціювання отримуємо модель в натуральному масштабі:
lnУ
= 0,44428Х – 8,20098;
![]()
Другий підхід полягає у використанні полінома другого порядку:
У = а + вХ + сХ2.
Тут замість
спрямлення даних виконується додавання
третьої змінної – квадрату Х. Тим самим
задача зводиться до використання
множинної регресії. Процес обчислення
є однаковим, але тут в якості незалежних
змінних фігурують Х та Х2.
Замість Х2
можуть бути взяті
![]() ,
lnX,
,
lnX,
![]() і т. д.
і т. д.
В регресивному аналізі дослідного масиву може бути використаний також метод Брандона. За цим методом шукають рівняння у вигляді:
 ,
,
де і = 1, 2, …, К – номер незалежної змінної об’єкту досліджень;
К – їх кількість.
Для двох змінних рівняння має вигляд:
![]() .
.
Обробка масиву виконується послідовно по кожному параметру. Спочатку визначають параметри рівняння регресії:
f1(X1)
=
![]() =
=
![]() ,
,
де та - середні значення У та Х1 за вибіркою;
![]() - коефіцієнт регресії Х1
на У;
- коефіцієнт регресії Х1
на У;
х1 = Х1 - ; у = У - - відхилення параметрів від середніх значень.
Потім оцінюють
різницю між експериментальними та
розрахунковими даними dx1
y = У -
,
визначають суму їх квадратів
![]() ,
середньоквадратичне відхилення
,
середньоквадратичне відхилення
![]() ,
стандартну помилку коефіцієнта
,
стандартну помилку коефіцієнта
![]() і розрахункове значення критерію
Стьюдента
і розрахункове значення критерію
Стьюдента
![]() .
.
Якщо t1 > tт для числа ступенів свободи (N – 1), то складають вибірку нової величини:
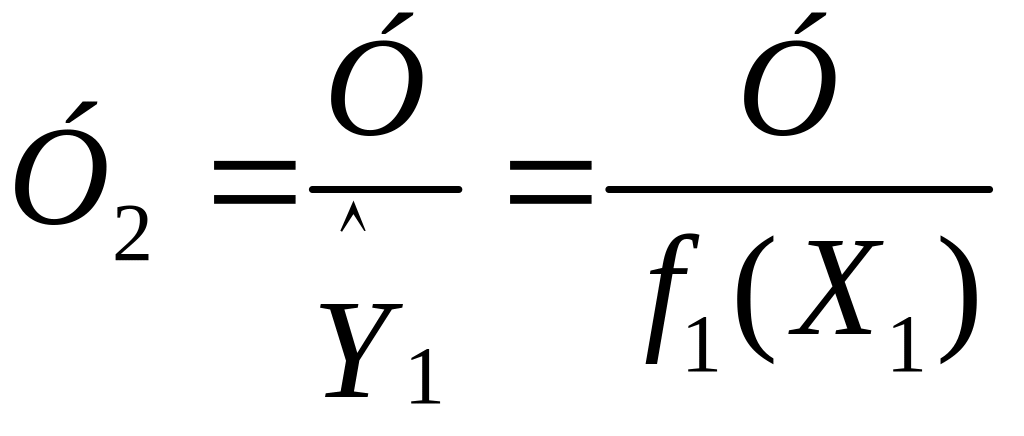 .
.
В разі невиконання вказаної умови приймають У2 = У, оскільки коефіцієнт регресії в1 є не значимим і повинен відсіюватися.
Вважаючи
залежність
![]() лінійною, знаходять величини:
лінійною, знаходять величини:
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]()
і складають рівняння регресії:
![]() .
.
Аналогічно, як і для в1, перевіряють значимість коефіцієнта в2 послідовним визначенням величин:
dx2
y2 = У2
-
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Якщо коефіцієнт
в1
був на першому етапі відсіяний, то в
знаменнику формули для визначення
![]() треба взяти величину (N –1).
треба взяти величину (N –1).
Умовою значимості в2 є співвідношення: t2 > tт .
Потім оцінюють
відхилення від регресії за кожним u –
тим дослідом
![]() ,
визначають середнє його значення:
,
визначають середнє його значення:
 та записують рівняння в кінцевому
вигляді:
та записують рівняння в кінцевому
вигляді:
![]() з урахуванням відсіяних коефіцієнтів.
з урахуванням відсіяних коефіцієнтів.
За означеною процедурою виконується складання рівняння множинної регресії і для більшої кількості змінних об’єкту.