

§7.3 Параметрический дискриминантный анализ, в случае нормальных классов
![]() плотность
многомерного нормального распределения:
плотность
многомерного нормального распределения:
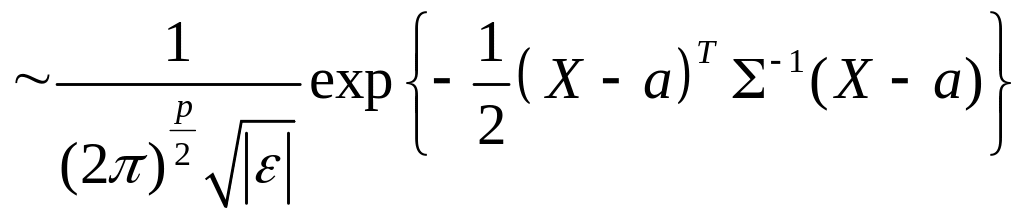
В этом случае j-ый класс идентифицируется p-мерной нормальной плотностью с вектором средних aj и ковариационной матрицей Σ, общей для всех классов:
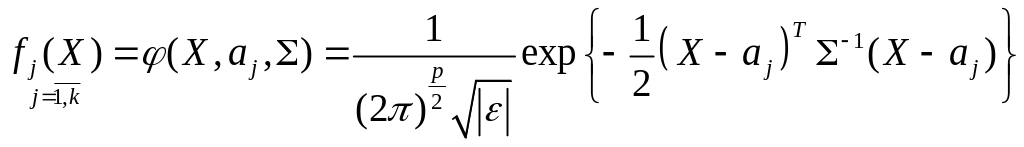 (7.7)
(7.7)
![]()
В качестве оценки для fj(X) используются функции:
![]() ,
где
,
где
![]() оценка для p-мерных
векторов средних aj.
оценка для p-мерных
векторов средних aj.
![]() оценка для ковариационной матрицы.
оценка для ковариационной матрицы.
Эти оценки получены с помощью метода максимального правдоподобия по обучающим выборкам:
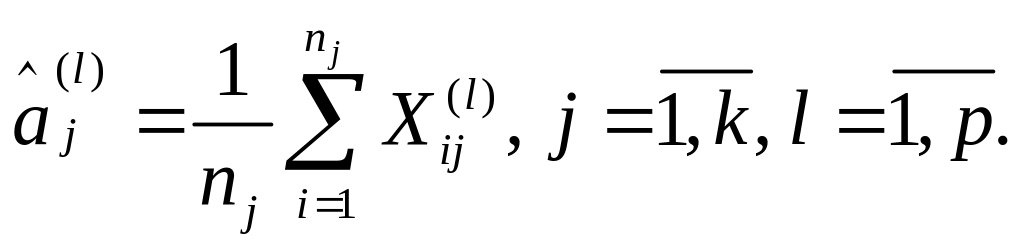
![]() (7.8)
(7.8)
из
(7.6) следует что
![]()
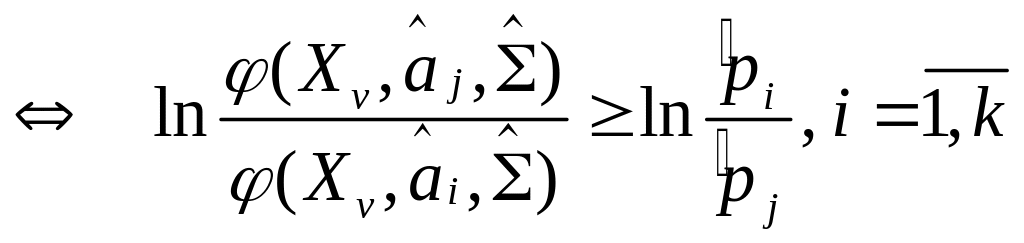 (7.9)
(7.9)
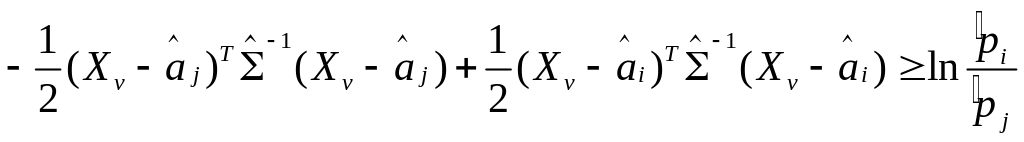
![]()
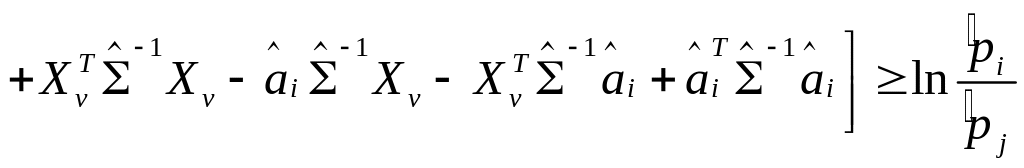
![]() ,
,
![]()

![]()
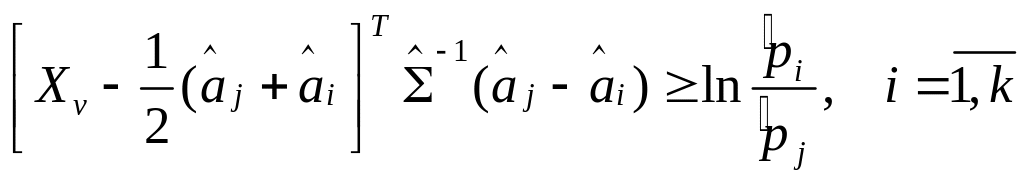 (7.10)
(7.10)
В
частности для k=2
и
![]()
![]() (7.11)
(7.11)
![]() в
остальных случаях.
в
остальных случаях.
Для
одномерного случая
![]() .
.
Пример:
Склонность фирм к утаиванию своих доходов (а значит и уклонению от уплаты налогов) определяется двумя показателями
X(1) –соотношение ” быстрых активов ” и текущих пассивов.
X(2) –соотношение прибыли и процентных ставок.
Показатели оцениваются по особой методике в шкале от 300 до 900 баллов.
По данным налоговой инспекции получены две обучающие выборки:
![]() -
фирма уклоняется от налогов.
-
фирма уклоняется от налогов.
![]() -
фирма не имеет замечаний по уплате
налогов
-
фирма не имеет замечаний по уплате
налогов
![]() фирма
не прошла проверку.
фирма
не прошла проверку.
|
|
|
|
|
1 |
740 |
680 |
750 |
590 |
2 |
670 |
600 |
360 |
600 |
3 |
560 |
550 |
720 |
750 |
4 |
540 |
520 |
540 |
710 |
5 |
590 |
540 |
570 |
700 |
6 |
590 |
700 |
520 |
670 |
7 |
470 |
600 |
590 |
790 |
8 |
560 |
540 |
670 |
700 |
9 |
540 |
630 |
620 |
730 |
10 |
500 |
600 |
690 |
840 |
11 |
|
|
610 |
680 |
12 |
|
|
550 |
730 |
13 |
|
|
590 |
750 |
|
|
|
|
|
![]()
![]()
![]()
![]()
![]()
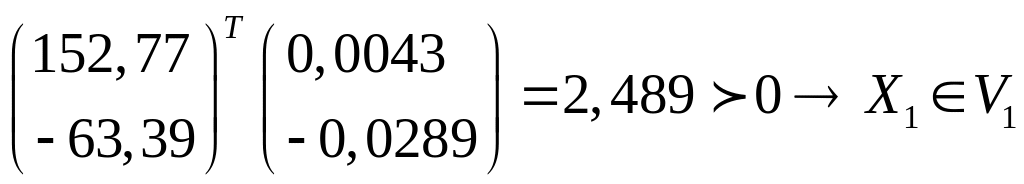 фирма
уклоняется от налогов.
фирма
уклоняется от налогов.
Пункт 8. Расщепление смеси вероятностных распределений
В начале раздела будет кратко изложена задача расщепления смеси вероятностных распределений в рамках классификации без обучения (параметрический случай)
Пример:
Два станка 1 и 2, выпускающих одно и тоже изделие. Распределение размеров деталей 1 станка (a1,σ1), 2 станка (a2,σ2). Производство второго станка выше первого в 1,5 раза.

Если
![]() размеры выпускаемых изделий.
размеры выпускаемых изделий.
В более общей формулировке: имеется выборка из общей генеральной совокупности
![]()
fj(X) унимодальное распределение. Обучающих выборок нет. Требуется определить для каждого Xv из какой генеральной совокупности оно взято.
В
параметрическом случае
![]() ,
,
![]() -многомерный
параметр.
-многомерный
параметр.
По
выборке
следует построить оценки к:
![]() ,
,
![]() .
.
В
некоторых случаях априорные сведения
дают исследователю точные значения
числа компонент k
и вероятности
.
После нахождения
![]() ,
,
![]() ,
,
![]() задача сводится к изложенной выше схеме
параметрического дискриминантного
анализа.
задача сводится к изложенной выше схеме
параметрического дискриминантного
анализа.
В заключение напомним, в случае когда у исследователя нет оснований интерпретировать классифицируемые наблюдения , в качестве выборки из какой-либо генеральной совокупности следует пользоваться изложенным ранее методами кластерного анализа.