

11. Общие полож.Risc-проц. Старнфордсая структура
При разработке ПО существует правило 80/20, т.е. каждым разработчиком при реализации данной проги используется 20% команд процессора и на их выполнение уходит 80% времени. Появилась задача изобретения ориентированного процессора.
Разработчики RISC-процов:
1) определяют область применения и круг решаемых задач
2) выделяются min необходимый перечень команд, выбранные команды реализуются аппаратно для получения max быстродействия, обычно одна команда выполн за 1 такт. При этом использ простые способы адресации и простые инструкции.
3) если дополнительные команды не требует существ аппаратных затрат, то они тоже реализуются на всякий случай.
4) для получения max быстродействия используются простые способы реализации.
Разр RISC-процессоров ориентируется на поддержку ЯВУ и на конвейерный тип выполнения команд. Условно выполнение любой команды можно разбить на фазы:

1 команда выполн 5 тактов, однако каждый след такт мы получаем рез-т. Все этапы выполн команды условно занимают одинаковый интервал времени. После заполнения конвейера за каждый такт на выходе имеем результат => высокая производительность.
Минус: команды должны быть одинаковы по времени.
Старнфортская архитектура.
Центральная идея – максимально повысить тактовую частоту за счет минимальных аппаратных затрат, максимальная конвейеризация. Конвейерные машины обладают максимальной производительностью при отсутствии "ломких" конвейеров. "Ломка" конвейера возникает:
по неготовности операнда (следующей команде нужен результат предыдущей). Для устранения "ломки" оптимизационный компилятор должен вставлять пустые такты JMP или команду NOP.
наличие условных и безусловных переходов. Для предотвращения компилятор должен менять последовательности команд (II) т.к. загр команда в конвейер все равно выполнится.
|
|
I |
II |
|
MOV A |
MOV A |
MOV A |
|
ADD |
NOP |
JMP |
|
JMP |
ADD |
ADD |
|
NC |
NOP |
|
|
|
NOP |
|
Для оптимизации работы аппаратных ресурсов разработчики компилятора использовали метод окрашенных графов (каждый РОН окрашивается своим цветом).

Достоинства: мин аппаратные затраты, макс тактовая частота.
Недостатки: сложность построения оптимизационного компилятор больше время на компиляцию; большое количество команд пересылок; частое обращение к внешней памяти.
-----------------------------------------------------------------------------------------------------
12. Кэш память.
Увеличение объема памяти приводит к уменьш быстродейств (время на дешифрацию) .Кроме этого обращение в внешн памяти (выход за пределы кристалла) снижает быстр примерно на порядок по сравн с быстр внутри кристалла (СРU≈2 ГГц, обращение к памяти 125-133 МГц). Подавляющее большинство программ носит циклический характер.
КЭШ память предназначена для хранения последних наиболее часто встречающихся команд. КЭШ-память располагается или внутри кристалла проц или максимально близко к нему и время обр к КЭШ-памяти не порядок быстрее чем к глобальному ДОЗУ.
|
|
Копия в КЭШ |
Инф | |
|
В КЭШ |
В гл ДОЗУ | ||
|
Чтение |
Есть Нет |
Чтение Запись+след слово |
- Чтение |
|
Запись |
Есть Нет |
-(обновл) - |
Запись Запись |

Модуль памяти предствляется в виде 32 разрядных слов при 16 разрядной ША. После каждого обращения к ДОЗУ в КЭШ записывается 32 разрядное слово (16 разрадов, которые просит проц и 16 разрядов следущих). Т.к. вероятность выборки следующего слова большая, это уменьшает число обращений к глобальному ДОЗУ.
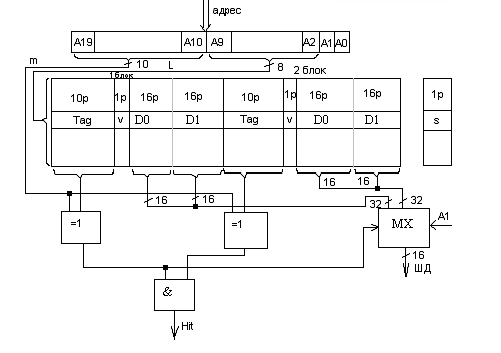
Адрес в контролере КЭШ трактуется следующим образом:
Младш часть адреса L выбирает одну из ячеек КЭШ-памяти (разрядность L определяется количеством ячеек в КЭШ).
Старш часть адр M сравнивается со старшей частью адреса, записанного в ячейку КЭШ (Tag). Если они совпадают, то это значит, что по данному адресу уже было обращение и в КЭШ есть быстрая копия, тогда формируется сигнал Hit, который сообщает системному контролеру, что цикл обращения быстрый, открывает MX, и с помощью сигнала A1 выбирается соответствующее 16 разрядное слово из КЭШ.
Если они не совпали, значит в КЭШ копии нет, Hit равен 1, идет обращение к глобальному ДОЗУ и одновременно в КЭШ в возбужденную ячейку (младшим адресом L) записывается старшая часть адреса на место Tag и данные на место D0 и D1.
О том, что в КЭШ памяти находятся данные сообщает признак истинности V (после системного сброса V устанавливается в 0, при записи в 1).
Т.к. L небольшая и она одинакова для различных значений M, для того чтобы можно было хранить хотя бы два различных слова с одинаковым L в КЭШ организуется два банка (они идентичны). Для того чтобы выбрать банк куда надо записывать последнюю копию используется признак старости S.
КЭШ дает выигрыш в быстродействии только в цикле чтения. Циклы записи имеют то же время.
-----------------------------------------------------------------------------------------------------