

2 Выбор формы связи
Определяющая роль в выборе формы связи между явлениями принадлежит теоретическому анализу. Так, например, чем больше размер основного капитала предприятия (факторный признак), тем больше при прочих равных условиях оно выпускает продукции (результативный признак).
С ростом факторного признака здесь, как правило, равномерно растет и результативный, поэтому зависимость между ними может быть выражена уравнением прямой Y=a+b*x, которое называется линейным уравнением регрессии.
Параметр b называется коэффициентом регрессии и показывает, насколько в среднем отклоняется величина результативного признака у при отклонении величины факторного признаках на одну единицу. При x = 0 a = Y. Увеличение количества внесенных удобрений приводит, при прочих равных условиях, к росту урожайности, но чрезмерное внесение их без изменения других элементов к дальнейшему повышению урожайности не приводит, а, наоборот, снижает ее.
Такая зависимость может быть выражена уравнением параболы Y=a+b*x+c*x2.
Параметр c характеризует степень ускорения или замедления кривизны параболы, и при c>0 парабола имеет минимум, а при c<0 - максимум. Параметр b, характеризует угол наклона кривой, а параметр a - начало кривой.
Однако с помощью теоретического анализа не всегда удается установить форму связи. В таких случаях приходится только предполагать о наличии определенной формы связи. Проверить эти предположения можно при помощи графического анализа, который используется для выбора формы связи между явлениями, хотя графический метод изучения связи применяется и самостоятельно.
3 Аналитическое выражение связи
Применение методов корреляционного анализа дает возможность выражать связь между признаками аналитически - в виде уравнения - и придавать ей количественное выражение. Рассмотрим применение приемов корреляционного анализа на конкретном примере.
Допустим, что между стоимостью основного капитала и выпуском продукции существует прямолинейная связь, которая выражается уравнением прямой Y=a+b*x.
Необходимо найти параметры a и b, что позволит определить теоретические значения Y для разных значений x. Причем a и b должны быть такими, чтобы было достигнуто максимальное приближение к первоначальным (эмпирическим) значениям теоретических значений Y. Эта задача решается при помощи способа наименьших квадратов, основное условие которого сводится к определению параметров a и b, таким образом, чтобы
![]() .
.
Математически доказано, что условие минимума обеспечивается, если параметры a и b, определяются при помощи системы двух нормальных уравнений, отвечающих требованию метода наименьших квадратов:
![]()
Первое уравнение есть сумма всех первоначальных уравнений. Второе получается умножением обеих частей уравнения прямой на один и тот же множитель.
Математически
доказано, что условие
![]() соблюдается,
если в качестве такого множителя принять
значение факторного признака, т.е. если
уравнение прямой умножить на х. Кроме
рассмотренных функций связи в экономическом
анализе часто применяются степенная,
показательная и гиперболическая функции.
Степенная функция имеет вид Y=axb.
соблюдается,
если в качестве такого множителя принять
значение факторного признака, т.е. если
уравнение прямой умножить на х. Кроме
рассмотренных функций связи в экономическом
анализе часто применяются степенная,
показательная и гиперболическая функции.
Степенная функция имеет вид Y=axb.
Параметр b степенного уравнения называется показателем эластичности и указывает, на сколько процентов изменится у при возрастании х на 1 %. При х = 1 a = Y.
Для определения параметров степенной функции вначале ее приводят к линейному виду путем логарифмирования: lg y=lg a+ blg x, а затем строят систему нормальных уравнений:
![]()
Решив систему двух нормальных уравнений, находят логарифмы параметров логарифмической функции a и b, а затем и сами параметры a и b. При помощи степенной функции определяют, например, зависимость между фондом заработной платы и выпуском продукции, затратами труда и выпуском продукции и т.д.
Если факторный признака x растет в арифметической прогрессии, а результативный у - в геометрической, то такая зависимость выражается показательной функцией Y=a+bx. Для определения параметров показательной функции ее также вначале приводят к линейному виду путем логарифмирования: lg y=lg a+ xlg b, а затем строят систему нормальных уравнений:
![]()
Вычислив соответствующие данные и решив систему двух нормальных уравнений, находят параметры показательной функции a и b.
В ряде случаев обратная связь между факторным и результативным признаками может быть выражена уравнением гиперболы:
Y=a+b/x.
И здесь задача заключается в нахождении параметров a и b при помощи системы двух нормальных уравнений:
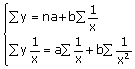
При помощи гиперболической функции изучают, например, связь между выпуском продукции и себестоимостью, уровнем издержек обращения (в процентах к товарооборот и товарооборотом в торговле, сроками уборки и урожайностью и т.д.).
Таким образом, применение различных функций в качестве уравнения связи сводится к определению параметров уравнения по способу наименьших квадратов при помощи системы нормальных уравнений.
В малых совокупностях значение коэффициента регрессии подвержено случайным колебаниям. Поэтому возникает необходимость в определении достоверности коэффициента регрессии. Достоверность коэффициента регрессии определяется так же, как и в выборочном наблюдении, т.е. устанавливаются средняя и предельная ошибки для выборочной средней и доли.
Средняя ошибка коэффициента регрессии определяется по формуле:
![]()
где σ20 - случайная дисперсия;
Корреляционная связь описывает следующие виды зависимостей:
причинную зависимость между значениями параметров. Примером такой зависимости является взаимосвязь пропускной способности канала передачи данных и соотношения сигнал/шум (на пропускную способность влияют и другие факторы – характер помех, амплитудно-частотные характеристики канала, способ кодирования сообщений и др.). Установить однозначную связь между конкретными значениями указанных параметров не удается. Но очевидно, что пропускная способность зависит от соотношения уровней сигнала и помех в канале. Иногда при этом причину и следствие особо не выделяют. В некоторых случаях такая корреляция является бессмысленной, например: если в качестве исходного фактора взять доходы разработчиков антивирусных программ, а за результат – количество вновь появляющихся вирусов, то можно сделать вывод, что разработчики антивирусов "стимулируют" создание вирусов;
"зависимость" между следствиями общей причины. Подобная зависимость характерна, в частности, для скорости и безошибочности набора текста оператором (указанные факторы зависят от квалификации оператора).
Корреляционная зависимость определяется различными параметрами, среди которых наибольшее распространение получили показатели, характеризующие взаимосвязь двух случайных величин (парные показатели): корреляционный момент, коэффициент корреляции.
42.
Дисперсионный анализ — это статистический метод оценки связи между факторными и результативным признаками в различных группах, отобранный случайным образом, основанный на определении различий (разнообразия) значений признаков. В основе дисперсионного анализа лежит анализ отклонений всех единиц исследуемой совокупности от среднего арифметического. В качестве меры отклонений берется дисперсия (В)— средний квадрат отклонений. Отклонения, вызываемые воздействием факторного признака (фактора) сравниваются с величиной отклонений, вызываемых случайными обстоятельствами. Если отклонения, вызываемые факторным признаком, более существенны, чем случайные отклонения, то считается, что фактор оказывает существенное влияние на результативный признак.
Для того, чтобы вычислить дисперсию значения отклонений каждой варианты (каждого зарегистрированного числового значения признака) от среднего арифметического возводят в квадрат. Тем самым избавляются от отрицательных знаков. Затем эти отклонения (разности) суммируют и делят на число наблюдений, т.е. усредняют отклонения. Таким образом, получают значения дисперсий.
Важным методическим значением для применения дисперсионного анализа является правильное формирование выборки. В зависимости от поставленной цели и задач выборочные группы могут формироваться случайным образом независимо друг от друга (контрольная и экспериментальная группы для изучения некоторого показателя, например, влияние высокого артериального давления на развитие инсульта). Такие выборки называются независимыми.
Нередко результаты воздействия факторов исследуются у одной и той же выборочной группы (например, у одних и тех же пациентов) до и после воздействия (лечение, профилактика, реабилитационные мероприятия), такие выборки называются зависимыми.
Дисперсионный анализ, в котором проверяется влияние одного фактора, называется однофакторным (одномерный анализ). При изучении влияния более чем одного фактора используют многофакторный дисперсионный анализ (многомерный анализ).
Факторные признаки — это те признаки, которые влияют на изучаемое явление. Результативные признаки — это те признаки, которые изменяются под влиянием факторных признаков.
Для проведения дисперсионного анализа могут использоваться как качественные (пол, профессия), так и количественные признаки (число инъекций, больных в палате, число койко-дней).
Методы дисперсионного анализа:
Метод по Фишеру (Fisher) — критерий F (значения F см. в приложении N 1); Метод применяется в однофакторном дисперсионном анализе, когда совокупная дисперсия всех наблюдаемых значений раскладывается на дисперсию внутри отдельных групп и дисперсию между группами.
Метод "общей линейной модели". В его основе лежит корреляционный или регрессионный анализ, применяемый в многофакторном анализе.
Обычно в медико-биологических исследованиях используются только однофакторные, максимум двухфакторные дисперсионные комплексы. Многофакторные комплексы можно исследовать, последовательно анализируя одно- или двухфакторные комплексы, выделяемые из всей наблюдаемой совокупности.
Условия применения дисперсионного анализа:
Задачей исследования является определение силы влияния одного (до 3) факторов на результат или определение силы совместного влияния различных факторов (пол и возраст, физическая активность и питание и т.д.).
Изучаемые факторы должны быть независимые (несвязанные) между собой. Например, нельзя изучать совместное влияние стажа работы и возраста, роста и веса детей и т.д. на заболеваемость населения.
Подбор групп для исследования проводится рандомизированно (случайный отбор). Организация дисперсионного комплекса с выполнением принципа случайности отбора вариантов называется рандомизацией (перев. с англ. — random), т.е. выбранные наугад.
Можно применять как количественные, так и качественные (атрибутивные) признаки.
При проведении однофакторного дисперсионного анализа рекомендуется (необходимое условие применения):
Нормальность распределения анализируемых групп или соответствие выборочных групп генеральным совокупностям с нормальным распределением.
Независимость (не связанность) распределения наблюдений в группах.
Наличие частоты (повторность) наблюдений.
Нормальность распределения определяется кривой Гаусса (Де Мавура), которую можно описать функцией у = f(х), так как она относится к числу законов распределения, используемых для приближенного описания явлений, которые носят случайный, вероятностный характер. Предмет медико-биологических исследований — явления вероятностного характера, нормальное распределение в таких исследованиях встречается весьма часто.
Принцип применения метода дисперсионного анализа
Сначала формулируется нулевая гипотеза, то есть предполагается, что исследуемые факторы не оказывают никакого влияния на значения результативного признака и полученные различия случайны.
Затем определяем, какова вероятность получить наблюдаемые (или более сильные) различия при условии справедливости нулевой гипотезы.
Если эта вероятность мала*, то мы отвергаем нулевую гипотезу и заключаем, что результаты исследования статистически значимы. Это еще не означает, что доказано действие именно изучаемых факторов (это вопрос, прежде всего, планирования исследования), но все же маловероятно, что результат обусловлен случайностью. __________________________________ * Максимальную приемлемую вероятность отвергнуть верную нулевую гипотезу называют уровнем значимости и обозначают α = 0,05.
При выполнении всех условий применения дисперсионного анализа, разложение общей дисперсии математически выглядит следующим образом:
Doбщ. = Dфакт + D ост.,
Doбщ. - общая дисперсия наблюдаемых значений (вариант), характеризуется разбросом вариант от общего среднего. Измеряет вариацию признака во всей совокупности под влиянием всех факторов, обусловивших эту вариацию. Общее разнообразие складывается из межгруппового и внутригруппового;
Dфакт - факторная (межгрупповая) дисперсия, характеризуется различием средних в каждой группе и зависит от влияния исследуемого фактора, по которому дифференцируется каждая группа. Например, в группах различных по этиологическому фактору клинического течения пневмонии средний уровень проведенного койко-дня неодинаков — наблюдается межгрупповое разнообразие.
D ост. - остаточная (внутригрупповая) дисперсия, которая характеризует рассеяние вариант внутри групп. Отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неуточненных факторов и не зависящую от признака — фактора, положенного в основание группировки. Вариация изучаемого признака зависит от силы влияния каких-то неучтенных случайных факторов, как от организованных (заданных исследователем), так и от случайных (неизвестных) факторов.
Поэтому общая вариация (дисперсия) слагается из вариации, вызванной организованными (заданными) факторами, называемыми факториальной вариацией и неорганизованными факторами, т.е. остаточной вариацией (случайной, неизвестной).
Классический дисперсионный анализ проводится по следующим этапам:
Построение дисперсионного комплекса.
Вычисление средних квадратов отклонений.
Вычисление дисперсии.
Сравнение факторной и остаточной дисперсий.
Оценка результатов с помощью теоретических значений распределения Фишера-Снедекора (приложение N 1).
40.
F — критерий Фишера
Критерий Фишера позволяет сравнивать величины выборочных дисперсий двух независимых выборок. Для вычисления Fэмп нужно найти отношение дисперсий двух выборок, причем так, чтобы большая по величине дисперсия находилась бы в числителе, а меньшая – в знаменателе. Формула вычисления критерия Фишера такова:
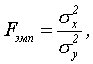 (8)
(8)
где
![]() -
дисперсии первой и второй выборки
соответственно.
-
дисперсии первой и второй выборки
соответственно.
Так как, согласно условию критерия, величина числителя должна быть больше или равна величине знаменателя, то значение Fэмп всегда будет больше или равно единице.
Число степеней свободы определяется также просто:
k1=nl - 1 для первой выборки (т.е. для той выборки, величина дисперсии которой больше) и k2=n2 - 1 для второй выборки.
В Приложении 1 критические значения критерия Фишера находятся по величинам k1 (верхняя строчка таблицы) и k2 (левый столбец таблицы).
Если tэмп>tкрит, то нулевая гипотеза принимается, в противном случае принимается альтернативная.
Пример 3. В двух третьих классах проводилось тестирование умственного развития по тесту ТУРМШ десяти учащихся.1[3] Полученные значения величин средних достоверно не различались, однако психолога интересует вопрос — есть ли различия в степени однородности показателей умственного развития между классами.
Решение. Для критерия Фишера необходимо сравнить дисперсии тестовых оценок в обоих классах. Результаты тестирования представлены в таблице:
Таблица 3.
№№ учащихся |
Первый класс |
Второй класс |
1 |
90 |
41 |
2 |
29 |
49 |
3 |
39 |
56 |
4 |
79 |
64 |
5 |
88 |
72 |
6 |
53 |
65 |
7 |
34 |
63 |
8 |
40 |
87 |
9 |
75 |
77 |
10 |
79 |
62 |
Суммы |
606 |
636 |
Среднее |
60,6 |
63,6 |
Рассчитав дисперсии для переменных X и Y, получаем:
sx2=572,83; sy2=174,04
Тогда по формуле (8) для расчета по F критерию Фишера находим:
![]()
По таблице из Приложения 1 для F критерия при степенях свободы в обоих случаях равных k=10 - 1 = 9 находим Fкрит=3,18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н1. Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
36.
Достоверность различия (сходства) — аналитико-статистическая процедура установления уровня значимости различий или сходств между выборками по изучаемым показателям (переменным).
Анализ Д. р. имеет практическое значение при оценке статистической значимости разности выборочных средних величин в сопоставляемых распределениях. Этот случай весьма распространен в эмпирических исследованиях. Предположим, перед психодиагностическим исследованием стоит задача проверки валидности текущей (диагностической) разрабатываемого теста методом контрастных групп. Если проверяемая методика является, к примеру, тестом общих способностей, валидизация может базироваться, в частности, на оценке степени устойчивости различий в тестовых оценках у детей со слабой и хорошей школьной успеваемостью. После проведения тестирования той и другой группы необходимо получить подтверждение истинности (а не случайности, например: за счет ошибки измерений) выявленных различий в средних оценках по тесту в сравниваемых выборках.
При проверке нулевой гипотезы о случайности (неслучайности) сходства (различия), в сущности, используется оценка вероятности совместного перекрытия (или не перекрытия) доверительных интервалов, в которые с определенной, наперед заданной вероятностью могут попадать переменные в сопоставляемых выборках.
При оценке статистической значимости разности выборочных средних арифметических двух распределений первичных величин применяется t-критерий Стьюдента, эмпирическое значение которого вычисляется в этом случае по формуле:
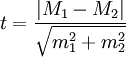
где M1,M2 — средние в сравниваемых выборках; m1,m2 — ошибки средних величин (см. Ошибка измерения), вычисленные по формуле:
m^2=\frac{\sigma^2}{n}
где n — объем выборки; σ — среднеквадратическое отклонение.
Разность средних считается статистически значимой, если t > tkp для доверительной вероятности α = 0,05 (см. Уровень значимости). Нулевая гипотеза о сходстве принимается при t≤tkp (α = 0,05) и отклоняется при t > tkp (α = 0,01). Критическое значение критерия Стьюдента (tkp) для каждой выборки определяется по таблицам (см. Основные статистические таблицы, таблица 2) с учетом ее объема и числа степеней свободы (n΄).
n' = n1 + n2 − 2
Значения tkp в таблице представлены для трех порогов доверительной вероятности (α = 0,05; 0,01; 0,001).
Предположим, в сопоставляемых контрастных группах учащихся получены следующие данные: M1 = 108,1;m1 = 10,44;M2 = 89,2;m2 = 9,07; число обследованных в первой выборке — 106, во второй — 94 n΄=106+94-2=198). Эмпирическое значение t-критерия:
![]()
Критическое значение по таблице — 1,97 (для α = 0,05); при t < tkp, гипотеза о различии результатов в сравниваемых группах отвергается.
Приведенный критерий используется и для оценки долей выборки (в тех случаях, когда доли находятся в пределах 0,2 < Р < 0,8); t-критерий для этого случая принимает вид:
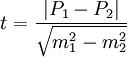
где P1,P2 — сравнительные доли выборки; m1,m2 — ошибки долей. Величину Р определяют с учетом числа объектов (A) с измеряемым признаком и объема выборки (n):
![]()
![]()
где q = 1 - P.
Дальнейшая процедура аналогична приведенному выше случаю со средними значениями выборок.
35.
УРОВЕНЬ ЗНАЧИМОСТИ вероятность ошибочно отвергнуть основную проверяемую гипотезу, когда она верна. В теории статистической проверки гипотез У. з. называется вероятностью ошибки первого рода. Понятие У. з. возникло в связи с задачей проверки согласованности теории с опытными данными. При выборе У. з. следует учитывать ущерб, неизбежно возникающий при использовании любого критерия значимости. Если У. з. чрезмерно велик, то основной ущерб будет происходить от ошибочного отклонения правильной гипотезы; если же У. з. мал, то ущерб будет, как правило, возникать от ошибочного принятия гипотезы, когда она ложна. Практически при обычных статистических расчетах в качестве У. з. выбирают вероятности в пределах от 0,01 до 0,1. Значения У. з. меньше 0,01 используются, напр., при статистических выявлениях токсичных медицинских препаратов, а также в др. случаях, когда первостепенное значение приобретает гарантия от ошибочного отклонения проверяемой гипотезы.
Уровень значимости статистического теста — допустимая для данной задачи вероятность ошибки первого рода (ложноположительного решения, false positive), то есть вероятность отклонить нулевую гипотезу, когда на самом деле она верна.
Другая интерпретация: уровень значимости — это такое (достаточно малое) значение вероятности события, при котором событие уже можно считать неслучайным.
Уровень
значимости обычно обозначают греческой
буквой ![]() (альфа).
(альфа).