

Регрессионный анализ
С позиции регрессионного анализа критериальный показатель z рассматривается как «зависимая» переменная (как правило, ранговая или количественная), которая выражается функцией от «независимых» признаков xi,...,xp. Для оценки эффективности регрессионной диагностической модели вводится вектор остатков ε=(ε1,...,εn)', который отражает влияние на z совокупности неучтенных случайных факторов либо меру достижимой аппроксимации значений критериального показателя zi функциями типа у(хi). Линейная функция регрессии записывается следующим образом
zi = wo + w'xi + εi
w0 называется свободным членом, а элементы весового вектора w=(w1 ..., wр) называются коэффициентами регрессии. Различают два подхода в зависимости от происхождения матрицы данных. В первом считается, что признаки xj являются детерминированными и случайной величиной является только зависимая переменная (критериальный показатель) z. Эта модель используется наиболее часто и называется моделью с фиксированной матрицей данных. Во втором подходе считается, что признаки x1, ..., xр и z — случайные величины, имеющие совместное распределение. В такой ситуации оценка уравнения регрессии есть оценка условного математического ожидания случайной величины z в зависимости от случайных величин xi,..., xp /Андерсон Т., 1963/. Данная модель называется моделью со случайной матрицей данных /Енюков И. С., 1986/. Каждый из приведенных подходов имеет свои особенности. В то же время показано, что модели с фиксированной матрицей данных и со случайной матрицей данных отличаются только статистическими свойствами оценок параметров уравнения регрессии, тогда как вычислительные аспекты этих моделей совпадают /Демиденко Е. 3., 1981/. В уравнении линейной функции регрессии обычно полагают, что величины εi(i=1,N) независимы и случайно распределены с нулевым средним и дисперсией σ2ε, а оценка параметров w0 и w производится с помощью метода наименьших квадратов (МНК). Ищется минимум суммы квадратов невязок
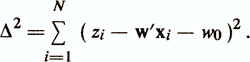
Это приводит к нормальной системе линейных уравнений:

где czx — вектор оценок ковариации между критериальным показателем z и признаками х1, ..., xp; mz — оценка среднего значения z; mx и S — вектор средних значений и матрица ковариации признаков xi, ..., xp. Основные показатели качества регрессионной диагностической модели следующие /Енюков И. С., 1986/: — остаточная сумма квадратов
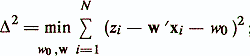
— несмещенная оценка дисперсии ошибки
![]()
— оценка дисперсии прогнозируемой переменной
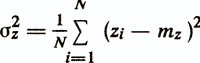
— коэффициент детерминации
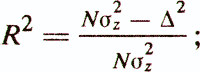
— оценка дисперсии коэффициентов регрессии
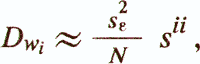
где sii — соответствующий элемент S-1;
![]()
Особого внимания заслуживает приведенный выше коэффициент детерминации R2. Он представляет собой квадрат коэффициента корреляции между значениями критериальной переменной z и значениями, рассчитываемыми с помощью модели у(х)=w'x+w0 (квадрат коэффициента множественной корреляции). Статистический смысл коэффициента детерминации заключается в том, что он показывает, какая доля зависимой переменной z объясняется построенной функцией регрессии у(х). Например, при коэффициенте детерминации 0,49 регрессионная модель объясняет 49% дисперсии критериального показателя, остальные же 51% считаются обусловленными факторами, не отраженными в модели. Еще одним важным показателем качества регрессионной модели является статистика
![]()
С помощью этой статистики проверяется гипотеза Н0: w1=w2= =...=wp=0, то есть гипотеза о том, что совокупность признаков xi,...,xp не улучшает описания критериального показателя по сравнению с тривиальным описанием zi=mz. Если FO>fp,N-p-1, где fp,N-p-1 — случайная величина, имеющая F-pacпределение c р и N-p-l степенями свободы, то Н0 отклоняется (критерий Фишера). В регрессионном анализе нередко проверяется другая гипотеза о равенстве нулю каждого из коэффициентов регрессии в отдельности Н0: wi=0. Для этого вычисляется Р-значение Р ( |tN-р| > ti}, где ti = wi/√Dwi, а величина tN-p имеет t-распределение с (N-р) степенями свободы. Здесь следует подчеркнуть, что принятие Hо (высокое Р-значение) еще не говорит о том, что рассматриваемый признак xi нужно исключить из модели. Этого делать нельзя, поскольку суждение о ценности данного признака может выноситься, исходя из анализа совокупного взаимодействия в модели всех признаков. Поэтому высокое p-значение служит только «сигналом» о возможной неинформативности того или иного признака. Описанная выше технология оценки параметров линейной диагностической модели относится к одной из классических схем проведения регрессионного анализа. Известно большое количество других вариантов такого анализа, опирающихся на различные допущения о структуре экспериментальных данных и свойствах линейной модели (например, Демиденко Е. 3., 1982; Дрейпер Н. и др., 1973; Мостеллер Ф. и др., 1982). Однако в практике конструирования психодиагностических тестов применение классических схем регрессионного анализа с развитым математическим аппаратом оценки параметров регрессионной модели часто вызывает большие сложности. Причин указанных сложностей немного, но они весьма весомы. Во-первых, сюда относится специфический характер исходных психодиагностических признаков и критериального показателя, которые, как правило, измеряются в дихотомических и ординальных шкалах. Меры связи таких признаков, как указывалось выше, имеют несколько отличную от коэффициента корреляции количественных признаков трактовку и сравнительно трудно сопоставимое поведение внутри интервала [0,1]. Поэтому расчетные формулы регрессионного анализа, полученные для количественных переменных, приобретают значительную степень приблизительности. Во-вторых, число исходных признаков, подвергающихся эмпирико-статистическому анализу в психодиагностических исследованиях, велико (может достигать несколько сотен) и между ними, как правило, встречаются объемные группы сильно связанных признаков. В этих условиях возникает явление мультиколлинеарности, приводящее к плохой обусловленности и в предельном случае вырожденности матрицы ковариации S. При плохой обусловленности S решение системы является неустойчивым — норма вектора оценок коэффициентов регрессии и отдельные компоненты w могут стать весьма большими, в то время как, например, знаки коэффициентов wi могут инвертироваться при малом изменении исходных данных /Демиденко Е. 3., 1982; Айвазян С. А. и др., 1985/. Указанные обстоятельства, ряд которых можно продолжить, обусловили приоритет в психодиагностике «грубых» методов построения регрессионных моделей. В основном проблема оценки параметров линейной психодиагностической модели сведена к задаче отбора существенных признаков. Известно много подходов к решению задачи определения группы информативных признаков: рассмотрение всех возможных комбинаций признаков; метод «k» лучших признаков /Барабаш Б. А., 1964; Загоруйко Н. Г., 1964/; методы последовательного уменьшения и увеличения группы признаков /Marill T. et al., 1963/; обобщенный алгоритм «плюс l минус r» /Kittrer J., 1978/; методы, основанные на стратегии максмина /Backer E. et al., 1911/; эволюционные алгоритмы, в частности, алгоритмы случайного поиска с адаптацией /Лбов Г. С., 1965/; метод ветвей и границ /Narendra P. M. et al., 1976/ и другие. Значительные вычислительные трудности, связанные с высокой размерностью пространства исходных признаков, привели к тому, что в практике конструирования психодиагностических тестов применяются наиболее простые алгоритмы определения состава линейной регрессионной модели.
49.