

6) Модель организации внешней памяти. Хешированные файлы. Индексированные файлы. Временные характеристики операций.
Реляционные СУБД обладают рядом особенностей, влияющих на организацию внешней памяти. К наиболее важным особенностям можно отнести следующие:
Наличие двух уровней системы: уровня непосредственного управления данными во внешней памяти (а также обычно управления буферами оперативной памяти, управления транзакциями и журнализацией изменений БД) и языкового уровня (например, уровня, реализующего язык SQL). При такой организации подсистема нижнего уровня должна поддерживать во внешней памяти набор базовых структур, конкретная интерпретация которых входит в число функций подсистемы верхнего уровня.
Поддержание отношений-каталогов. Информация, связанная с именованием объектов базы данных и их конкретными свойствами (например, структура ключа индекса), поддерживается подсистемой языкового уровня. С точки зрения структур внешней памяти отношение-каталог ничем не отличается от обычного отношения базы данных.
Регулярность структур данных. Поскольку основным объектом реляционной модели данных является плоская таблица, главный набор объектов внешней памяти может иметь очень простую регулярную структуру.
При этом необходимо обеспечить возможность эффективного выполнения операторов языкового уровня как над одним отношением (простые селекция и проекция), так и над несколькими отношениями (наиболее распространено и трудоемко соединение нескольких отношений). Для этого во внешней памяти должны поддерживаться дополнительные "управляющие" структуры - индексы.
Наконец, для выполнения требования надежного хранения баз данных необходимо поддерживать избыточность хранения данных, что обычно реализуется в виде журнала изменений базы данных.
Соответственно возникают следующие разновидности объектов во внешней памяти базы данных:
строки отношений - основная часть базы данных, большей частью непосредственно видимая пользователям;
управляющие структуры - индексы, создаваемые по инициативе пользователя (администратора) или верхнего уровня системы из соображений повышения эффективности выполнения запросов и обычно автоматически поддерживаемые нижним уровнем системы;
журнальная информация, поддерживаемая для удовлетворения потребности в надежном хранении данных;
служебная информация, поддерживаемая для удовлетворения внутренних потребностей нижнего уровня системы (например, информация о свободной памяти).
Хешированный файл
Хеширование
- широко распространенный метод
обеспечения быстрого доступа к информации,
хранящейся во вторичной памяти. Записи
файла распределяются между так называемыми
сегментами, каждый из которых состоит
из связного списка одного или нескольких
блоков внешней памяти.
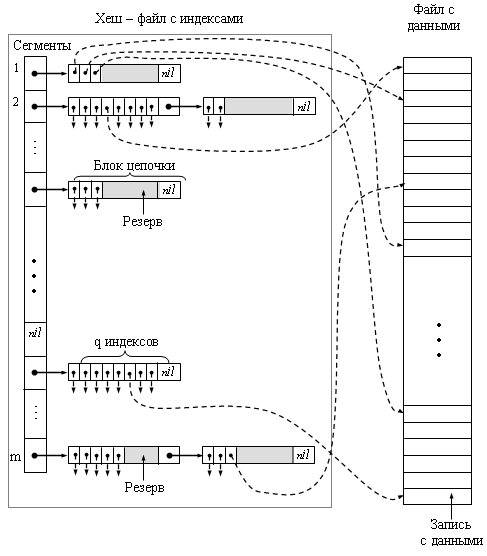
Основная идея хешированных файлов состоит в том, что файл разбивается на бакеты (участки). Каждая запись файла размещается в соответствующем бакете в зависимости от значения ключа записи. Ключ в данном случае не обязан быть уникальным. Для каждого файла, организованного таким способом, выбирается hash-функция h(v). Эта ф-ция в качестве параметра получает ключ записи. Выходом такой ф-ции явл-ся целое число в диапазоне от 0 до B-1, где B – желаемое число бакетов. Внутри бакета записи организованы также как в файле-куче, т.е. нет никакой упорядоченности.
В хешированных файлах нулевой блок содержит так называемый каталог бакетов. Каталог бакетов предст-ет собой массив указателей, индексированный от 0 до В-1.
Основная проблема построения ХФ это построение хеш-функции. Главное требование состоит в том, что хеш-функция должна принимать все значения с равной вероятностью. Работа простейшей хеш-функции состоит из двух шагов:1 -конвертирование ключа к целому типу; 2 - получение остатка от деления результата первого шага на число бакетов. Наиболее проста hash-ф-ция h(v)=v mod B
Поиск в таких файлах организуется след. образом. На основе ключа искомой записи рассчитывается hash-ф-ция. Т.о. получаем индекс эл-та в массиве (в каталоге бакетов) и находим 1ый блок необходимого бакета. Далее поиск производится внутри бакета как в файле, организованном в виде кучи, т.е. путем перебора всех записей из всех блоков бакета. Другие бакеты не просматриваются. Т.о. поиск в хешированных файлах в идеальном случае (т.е. количество записей в бакетах равномерно распределено) в В раз быстрее, чем в файлах, организованных в виде кучи.
Вставка записи. Для этого также вычисляем h(v) и находим нужный бакет. Пустое место для вставки записи будет иметь последний блок бакета, поэтому просматриваем все блоки бакета, пока не найдем блок с пустым указателем. Ситуации, когда не надо смотреть весь бакет:
1. если нам необходимо обеспечить уникальность записи, то перед вставкой мы просмотрели весь бакет и памяти уже находится последний блок.
2. Если нам не важна уникальность, то каталог бакетов можно усилить дополнительным массивом содержащим указатели на последние блоки бакетов.
После того, как необходимый блок найден, новая запись записывается в него, и блок записывается на диск. Если блок уже заполнен, то выделяется новый блок и в него заносим новую запись. Если заголовок бакета уже содержит пустой указатель, то выделяем новый блок и указатель на него помещаем в заголовок бакета. Перезаписываем новый блок и каталог бакетов.
Удаление. Производится поиск записи, а само удаление производится как в файле организованном в виде кучи.
Модификация. Если модификация не ключевого поля, то производится операция поиска, а затем выполняется 2 операции: чтение и запись. Если нужно ключевое поле, то после поиска выполняется операции удаления и вставки.
Индексированные файлы
Индекс – это структура данных, связанная с файлом БД, и предназначенная для повышения скорости поиска отдельных записей в файле, в соответствии с чем сокращается время выполнения запросов пользователей на поиск, модификацию и удаление записей.
Индекс аналогичен по своей структуре и назначению предметному указателю, приведенному в конце книги. Как и предметный указатель книги, индекс базы данных упорядочен, и каждый элемент индекса содержит признак искомого объекта (поле индексирования), а также один или несколько указателей на место его расположения. Файл, содержащий логические записи, называется файлом данных, а файл, содержащий индексные записи, — индексным файлом.
В отличие от хеширования: а) индексирование не требует физической упорядоченности записей в файле данных (при индексировании индексный файл «подгоняется» под файл данных, а при хешировании – файл данных под значения хеш - функции); б) индексирование сохраняет требуемую логическую упорядоченность записей в файле данных (становится возможным поиск по интервалам, поиск близких значений, доступ к данным в их логической последовательности).
Применение индексов в целом эффективнее рассмотренных выше способов хранения и обработки данных. Это достигается за счет обработки значительно меньшего объема данных (индексного файла вместо файла данных) в операциях поиска и сортировки, особенно, если используемый индекс целиком помещается в оперативную память. Основной проблемой применения индексов является потеря производительности при их обновлении после операций удаления, вставки или изменения значения индексируемого поля.
Если индексирование организовано по ключу таблицы, то индекс называется первичным (не содержит повторяющихся значений), иначе индекс называется вторичным (может содержать повторяющиеся значения).
Файл данных может иметь один первичный индекс и несколько вторичных индексов.
Индекс может быть разреженным (поле индексирования содержит индексные записи только для некоторых ключевых значений поиска в последовательно упорядоченном файле) или плотным (в индексе содержатся индексные записи для всех значений поиска в упорядоченном или неупорядоченном файле).
7. В-деревья. Файлы с плотным индексом. Временные характеристики операций. (стр. 90 методички)
Б-деревья - сбалансированные деревья, удобные для хранения информации на дисках. Характерным для Б-деревьев является их малая высота h. Представление информации во внешней памяти в виде Б-дерева стало стандартным способом в системах баз данных.
Пример: Б-дерево степени 5:

В Б-дереве узел может иметь много сыновей, на практике до тысячи. Количество сыновей (максимальное) определяет степень Б-дерева.
Узел х, хранящий n[x] ключей, имеет n[x]+1 сыновей. Хранящиеся в х ключи служат границами, разделяющими всех потомков узла на n[x]+1 групп. За каждую группу отвечает один из сыновей х. При поиске в Б-дереве искомый ключ сравнивается с границами в узле х и выбирает один из n[x]+1 путей для дальнейшего поиска.
Особенности структуры Б-дерева вытекают из особенностей обработки информации во внешней памяти. Обычно эта информация (множество) имеет весьма большой объем и насчитывает миллионы и миллиарды элементов. Хранить такой объем в ОП невозможно. При обработке в ОП хранится только часть элементов, обрабатываемых в данный момент.
Представление Б-дерева. Как и в других деревьях, дополнительная информация и ключи хранятся в узлах дерева. Обычно дополнительная информация представлена в виде ссылки на сектор диска, где она хранится. Вместе с ключом при его перемещении дополнительная информация перемещается вместе с ним.
В отличие от 2-3 дерева ключи и дополнительная информация размещается не только в листьях, но и во внутренних узлах дерева. Хотя возможна организация Б-деревьев, в которых дополнительная информация хранится только в листьях, а во внутренних узлах - ключи и указатели на сыновей. Это экономит память во внутренних узлах и позволяет увеличить их степень при том же размере сектора.
Операции для Б-дерева (особенности). Считаем, что корень дерева всегда находится в ОП и операция Disk_Read для корня не выполняется. Но когда корень изменяется, его нужно сохранять на диске. Все узлы, передаваемые операциям, как входные параметры, уже считаны с диска.
Поиск в Б-дереве. Рассмотрим рекурсивную операцию B_Tree_Search, параметрами которой является указатель х на корень поддерева и ключ k искомого элемента. Операция вызывается первоначально для корня дерева B_Tree_Search(root[T], k). При нахождении в дереве элемента с заданным ключом операция возвращает пару (y, i), где у - узел Б-дерева, i - порядковый номер указателя, для которого keyi[y]=k. Иначе операция возвращает nil.
B_Tree_Search(x, k)
1. i <- 1
2. while
i ![]() n[x]
and k > keyi[x]
n[x]
and k > keyi[x]
3. dv i <- i+1
4. if i n[x] and k=keyi[x]
5. then return (x, i)
6. if leaf [x]
7. then return nil
8. else Disk_Read (pi[x])
9. return B_Tree_Search (pi[x], k)
При проходе по Б-дереву число обращений к диску 0(h). Цикл while занимает основное время вычислений и занимает время 0(th).
Файлы с плотным индексом
Плотный индекc (dense index) — индекс в базах данных, файл с последовательностью пар ключей и указателей на запись в файле данных. Каждый ключ в плотном индексе ассоциируется с определённым указателем на запись в сортированном файле данных. Идея использования индексов пришла от того, что современные базы данных слишком массивны и не помещаются в основную память. Мы обычно делим данные на блоки и размещаем данные в памяти поблочно. Однако поиск записи в БД может занять много времени. С другой стороны, файл индексов или блок индексов намного меньше блока данных и может поместиться в буфере основной памяти что увеличивает скорость поиска записи. Поскольку, ключи отсортированы можно воспользоваться бинарным поиском. В кластерных индексах с дублированными ключами плотный индекс указывает на первую запись с указанным ключом.
В файле с плотным индексом хранят пары (v, p), где v - ключ записи, а p - указатель (адрес, смещение) на запись в главном файле.
Пары (v, p) несложно упорядочить по ключу и искать пару с заданным ключом методом двоичного поиска (методом дихотомии). Поэтому файл с плотным индексом позволяет достичь максимального быстродействия при выполнении любой операции над записями.
При удалении записи указатель p устанавливают в значение NULL (“пусто”) и в главном файле возникают “дыры”; поэтому следует время от времени переписывать по-возможности главный и индексный файлы.
Недостатком файла с плотным индексом является то, что обычно из-за большого размера он не может быть скопирован полностью в оперативную память, а при считывании по частям теряется его теоретическое преимущество по быстродействию.
Проблему большого объема файла с плотным индексом решают путем введения нового уровня индексов, а именно создают файл с индексом индексных пар. В этом файле хранят пары (w, n), где w - значение v ключа для первой пары (v, p) из n - ой части файла с плотным индексом.
Файл с индексом индексных пар копируют в оперативную память. В результате поиска по ключу находят индекс n. Затем читают соответствующую часть файла с плотным индексом и находят в нем пару (v, p) с адресом p нужной записи в главном файле.
При организации записей с плотным индексом не возникает проблем с новыми записями: они заносятся либо в конец главного файла, либо в специальную зону пополнения.
формула для вычисления максимального времени доступа в количестве обращений к диску выглядит следующим образом:
Tn = log2Nбл. инд. + 1.
ПРИМЕР:
Допустим, что мы имеем следующие исходные данные: Длина записи файла ( LZ ) — 128 байт. Длина первичного ключа ( LK ) — 12 байт. Количество записей в файле ( KZ ) — 100000. Размер блока ( LB ) — 1024 байт. Рассчитаем размер индексной записи. Для представления целого числа в пределах 100000 нам потребуется 3 байта, можем считать, что у нас допустима только четная адресация, поэтому нам надо отвести 4 байта для хранения номера записи, тогда длина индексной записи будет равна сумме размера ключа и ссылки на номер записи, то есть:
LI = LK + 4 = I2 + 4 = 16 байт.
Определим количество индексных блоков, которое требуется для обеспечения ссылок на заданное количество записей. Для этого сначала определим, сколько индексных записей может храниться в одном блоке:
KIZB = LB/LI = 1024/16 = 64 индексных записи в одном блоке.
Теперь определим необходимое количество индексных блоков:
KIB = KZ/KZIB = 100000/64 = 1563 блока.
Мы округлили в большую сторону, потому что пространство выделяется целыми блоками, и последний блок у нас будет заполнен не полностью.
А теперь мы уже можем вычислить максимальное количество обращений к диску при поиске произвольной записи:
Tпоиска = log2KIB + 1 = log21563 + 1 = 11 + 1 = 12 обращений к диску.
Количество блоков, которое необходимо для хранения всех 100 000 записей, мы определим по следующей формуле:
KBO = KZ/(LB/LZ) = 100000/(1024/128) = 12500 блоков.
И это означает, что максимальное время доступа равно 12500 обращений к диску.