

8.8. Автоматы как распознающие устройства
Грамматики, изученные в предыдущих разделах, были в основном схемами, порождающими цепочки. В этом параграфе мы кратко коснемся теории автоматов и введем понятие автомата как системы распознавания цепочек. Связь между этой теорией и распознаванием образов очевидна, поскольку, как это было показано в предыдущих разделах, образы часто можно выразить в виде терминальных цепочек. Хотя исчерпывающий анализ автоматов лежит за пределами нашего обсуждения, мы рассмотрим несколько подробнее один специфический тип автоматов — конечные автоматы — и покажем, что конечный автомат способен распознавать автоматные языки (языки типа 3).

Пример. Рассмотрим автомат, заданный набором (8.8.1), где

Если, например, автомат находится в состоянии q0 и на вход поступает символ 0, то автомат переходит в состояние q2. Если
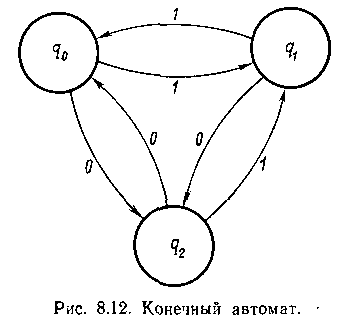
Диаграмма состояний этого автомата, приведенная на рис. 8.12, состоит из вершин, соответствующих каждому из возможных состоянии, и ориентированных ребер, соединяющих взаимно достижимые состояния. В данном примере, если состояние q1 было бы недостижимо из состояния q2
и обратно, на диаграмме не существовало бы ребра между этими двумя состояниями. Каждое ребро диаграммы обозначается соответствующим символом из множества Σ, обусловливающим переход автомата в указанное состояние.
Предположим, что автомат находится в состоянии q0 и на вход подается цепочка х=00110011. Автомат просматривает цепочку слева направо по одному символу за такт. Встретив первый 0, автомат переходит в состояние q2. Следующий 0 заставляет его вернуться в состояние q0. Точно так же следующий символ, которым является 1, меняет состояние автомата на q1. а вторая 1 возвращает его в исходное состояние q0. Завершение этой процедуры не требует разъяснений. Совершенно очевидно, что после прочтения цепочки х автомат будет находиться в состоянии qo.
Если в результате просмотра цепочки или предложения х автомат находится в одном из возможных заключительных состоя

Eсли цепочками {X} представлены образы, то нам удобно рассматривать конечный автомат как устройство, обеспечивающее разделение на два класса; цепочка приписывается к классу w1, если она допускается, и к классу w2, если она не допускается автоматом.
Можно показать, что если задана автоматная грамматика G = { vN, vt, Р, S), то существует конечный автомат A = (K,VT , δ, S, F), такой, что T(A)==L(G}. И обратно, если задан конечный автомат A, то существует автоматная грамматика G такая, что L{G}= T(A).
Исследования в теории автоматов показывают, что неограниченная грамматика, грамматика непосредственно составляющих и бесконтекстная грамматика могут распознаваться другими типами автоматов. Неограниченные языки допускаются машинами Тьюринга: языки непосредственно составляющих— линейно ограниченными автоматами; бесконтекстные языки— магазинными автоматами. Кроме того, теория автоматов легко допускает статистические постановки, как показано в работе Фу [1970]. Стохастические автоматы могут использоваться для распознавания стохастических языков. Можно также задать такой автомат, который будет допускать не цепочечные, а древовидные структуры. Читателю, заинтересованному углублении своих познаний по этому вопросу, можно порекомендовать, например, работы Фу и Бхаргавы [1973), Тэтчера [1973], Гон-салеса и Томасона [1974а].
8.9. ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
Материал данной главы иллюстрирует на примерах основные идеи использования лингвистических понятий в распознавании образов. Ставятся и обсуждаются некоторые ключевые проблемы. Задача выбора непроизводных элементов непосредственно связана с задачей выбора структурных признаков, подробно обсуждаемой в гл. 7. Тем не менее непроизводные элементы в этой главе рассматриваются как терминалы некоторой грамматики. Это позволяет интерпретировать образы как предложения соответствующего языка.
Выбор соответствующей двумерной грамматики осложняется изменчивостью, неизбежно возникающей при соединении двумерных структур. Эту сложность можно и какой-то степени обойти, каким-либо предварительно установленным образом ограничивая правила соединения. В п. 8,5,2 приводятся примеры эффективного сведения двумерных объектов к терминальным цепочкам. Другой метод обработки многомерных образов заключается в использовании грамматик деревьев, как было указано в п. 8.5.3.
Было показано, как при помощи грамматического разбора можно проводить распознавание синтаксических структур. В процессе распознавания можно применять нисходящие и восходящие схемы грамматического разбора. Эффективность разбора существенно возрастет, если вместе с анализируемым предложением использовать синтаксис грамматики.
Статистический аппарат привлекается в сферу синтаксического распознавания при помощи стохастических грамматик. Правила подстановки в этих грамматиках подчиняются вероятностным факторам. Следовательно, основной проблемой использования стохастических грамматик является получение вероятностей правил подстановки с помощью обучения. Метод, рассмотренный в п. 8.6.2, показывает, что эти вероятности могут быть получены с помощью обучающей выборки.
Задача вывода грамматики является лингвистическим эквивалентом алгоритмов обучения, изложенных в предыдущих главах. Однако, как отмечалось ранее, известные схемы вывода грамматики все еще имеют ограниченную область приложения, Алгоритмы из § 8.7 типичны для подходов, которые могут применяться при получении грамматики с помощью обучающей выборки предложений.
Синтаксическое распознавание образов может быть связано с некоторыми аспектами теории автоматов- Эта связь кратко освещена в § 8.8, где конечные автоматы выступают в роли эффективного распознающего устройства для автоматных языков, В этом параграфе также отмечено, что другие виды автоматов могут быть использованы для распознавания неограниченных. бесконтекстных языков и языков непосредственно составляющих.
Библиография
Исчерпывающее введение в формальные языки можно найти в книге Хопкрофта и Ульмана [I969]. С середины 60-х годов быстрыми темпами растет поток литературы по синтаксическому распознаванию образов. Первые достижения в этой области принадлежат Идену [1961]. Нарасимхану [19S9], Киршу [1964], Ледли [1964, 1965] и Ханклн и Ту [196В]. Представление об основных тенденциях в синтаксическом распознавании образов можно получить при изучении обзорных статей Миллера и Шоу [1968]. Фу и Суэина [1971] и Гонсалеса [1972].
Язык описания изображений, приведенный в п. 8.5,2,—результат работы Шоу [1970], а грамматика распознавания хромосом создана Ледли [1964, 1965], Исчерпывающее изложение методов грамматического разбора можно найти в книге Ахо и Ульмана [1978]. Великолепным справочником по древовидным системам является монография Кнута [1976]. Дополнительный материал по грамматикам деревьев можно найти в работах Фу и Бхаргавы J1973], Тэтчера [1973] и Гонсалеса и Томасона [1974э]. Сведения о стохастических грамматиках—в работах Фу [1971а], Ли и Фу [1971. 1972] и Бута [I969]. Алгоритм для цепочечных грамматик, представленный ч п. 8,7.1. является адаптацией результатов Фельдмана [1967, 1969), а алгоритмом, приведенным в п, 8.7.2, мы обязаны Эвансу [1971]. Дополнительная информация о выводе грамматик — работы Фельдмана, Джипса, Хорнинга и Ридера [I969], Фу [1972], Голда [1967]. Хорнинга [I969]. Пае [1969] и Креспи-Ретцци [1971]. Введение в проблему вывода грамматик деревьев может быть найдено в книге Гонсалеса и Томасона [19746]. В качестве справочного материала к § 8.8 рекомендуются работы Хопкрофта и Ульмана [1969] и Фу [1970].
Задачи
8.1. Опишите бесконтекстную грамматику с терминальным множеством Vr = [а, Ь], язык которой представляет собой цепочки, составленные из чередующихся элементов a и b и из чередующихся элементов Ь и а, т, е, L{G) == (ай. Ьа, аЬа, ЬаЬ, abab, ЬаЬа, ,..},
8.2. Можно ли породить язык, описанный в задаче 8.1. при помощи автоматной грамматики?
8.3 Используя непроизводные элементы, подобные изображенным на рис, 8.7, постройте грамматику PDL, способную порождать цифры от 0 до 5. Полезно было бы рассмотреть общий исходный символ и определить один или несколько пустых символов,
8.4. Проведите процесс распознавания образов, заданных в задаче 8.3. используя синтаксически ориентированную схему грамматического разборa сверху вниз.
8.5 Выполните задачу 8.4 при помощи синтаксически ориентированного восходящего грамматического анализатора.
8.6 К какому классу хромосом — V-образных или телоцентрических — отнесет цепочку acabdabcabd хромосомный анализатор Ледли?
8.7 Опишите грамматику деревьев для единичного куба, В качестве непроизводных элементов возьмите ребра куба.
88. Покажите, что множество Q в примере из п. 8.6.1 совместно.

|
Цепочка Х1 : аассас |
Числа появлений цепочки 50 |
|
Х2: ааасса |
40 |
|
Х3 : ааbcbс |
20 |
|
x4 : cbccbc |
50 |
|
X5 : bbbсbс |
40 |
![]()
8.10, Используя алгоритм из п. 8.7.1, определите посредством обучения автоматную грамматику, способную порождать следующие цепочки: [ааасс, ааасЬ, аасс, ЬасЬ, ааа, аЬс. ЬЬ, cc},
8,11- Применяя алгоритм Эванса, определите посредством обучения двумерную грамматику для образа

Используйте непроизводные элементы и символы, изображенные на рис. 8.11.
8.12, Опишите конечный автомат, который будет допускать только цепочки, составленные из четного числа символов a и/или четного числа символов Ь.