

Глава 8
СИНТАКСИЧЕСКОЕ РАСПОЗНАВАНИЕ ОБРАЗОВ')
8.1. Введение
Предыдущие главы были посвящены математическому подходу к распознаванию образов. В настоящей главе мы исследуем относительно новый и многообещающий подход, использующий понятия теории формальных языков. Этот подход часто называют синтаксическим распознаванием образов, хотя в литературе часто встречаются и другие названия, например: лингвистическое распознавание, структурное распознавание, распознавание методами теории формальных грамматик.
Основным отличием синтаксического распознавания образов от всех рассмотренных ранее является непосредственное использование структуры образов в процессе распознавания. Все аналитические методы, с другой стороны, отличаются строго количественным подходом к образам, почти полностью игнорирующим взаимосвязи между компонентами образа. Несомненно, существование распознаваемой «структуры» необходимо для успешного применения синтаксических методов в распознавании, Именно поэтому исследования в области синтаксического распознавания образов до сих пор в основном сводились к распознаванию изображений, характеризующихся хорошо различимыми формами, в частности символов, хромосом, фотоснимков столкновении частиц,
Интерес к синтаксическому распознаванию образов зародился в начале 60-х годов, хотя исследования в этой области не набрали силы вплоть до конца этого десятилетия. Даже сегодня многие вопросы, связанные с синтезом синтаксических систем распознавания образов, решены лишь частично. До сих пор, например, не построены универсальные алгоритмы обучения для синтаксических систем.
После введения некоторых понятий теории формальных языков внимание в последующих параграфах будет сосредоточено на основных проблемах, возникающих в процессе применения таких понятий в синтаксическом распознавании образов. Большинство современных исследований в данной области имеет дело именно с этими проблемами,
-------------------------------
') Глава 8 переведена И. Г, Гуревич.—Прим. ред.
-------------------------------
8.2. Понятия теории формальных языков
Возникновение теории формальных языков в середине 50-х годов связано с разработкой Ноамом Хомским математических моделей грамматик при исследовании естественных языков. Одной из первоначальных задач лингвистов, работающих в данной области, было создание «вычислительных» грамматик, способных описывать естественные языки, например, английский. Была надежда на то, что если замысел удастся, не составит большого труда научить машину «понимать» естественные языки в целях машинного перевода и решения задач. И хотя, по всеобщему мнению, надежды пока не оправдались, побочные результаты этих исследований оказали важное влияние в других областях, например при разработке компиляторов, в языках программирования. теории автоматов и, совсем недавно, в распознавании образов, В этом разделе мы прослеживаем развитие основных идей теории формальных языков в связи с проблемами синтаксического распознавания образов и обучения ЭВМ.
8.2.1. Определения
Понятия, определяемые ниже, играют центральную роль в теории формальных языков. И хотя некоторые из этих понятий легко отождествляются с понятиями, применяемыми при изучении естественных языков, мы предостерегаем читателя от проведения слишком глубоких аналогий.
Алфавит—любое конечное множество символов.
Предложение в некотором алфавите—произвольная цепочка конечной длины, состоящая из символов этого алфавита. Например, для алфавита {0, 1} допустимыми являются следующие предложения: {О, 1. 00, 01, 10, ...}- Обычно для обозначения предложения используют также термины цепочка и слово.
Предложение, не содержащее ни одного символа, называется пустым предложением. В дальнейшем пустое предложение будет обозначаться So. Для произвольного алфавита V знак V будет использоваться для обозначения множества всех предложений, составленных из символов алфавита V. включая пустое предложение. Символ V+ будет обозначать множество предложений V*— so. Если, например, задан алфавит V = [a,. b}, то
V* = {so, а, Ь, аа, аЬ, Ьа, ...} и V+= {а, Ь, аа, аЬ, Ьа, . ..}.
Язык—произвольное множество (не обязательно конечное) предложений в некотором алфавите.
Так же как и в естественных языках, серьезное изучение теории формальных языков должно концентрироваться на грамматиках и их свойствах. Грамматикой мы называем четверку
G = (VN, Vt ,P, S). (8.2.1)

Предполагается, что S принадлежит множеству VN и что VN и VT — непересекающиеся множества. Алфавит V является объединением алфавитов VN и VT..
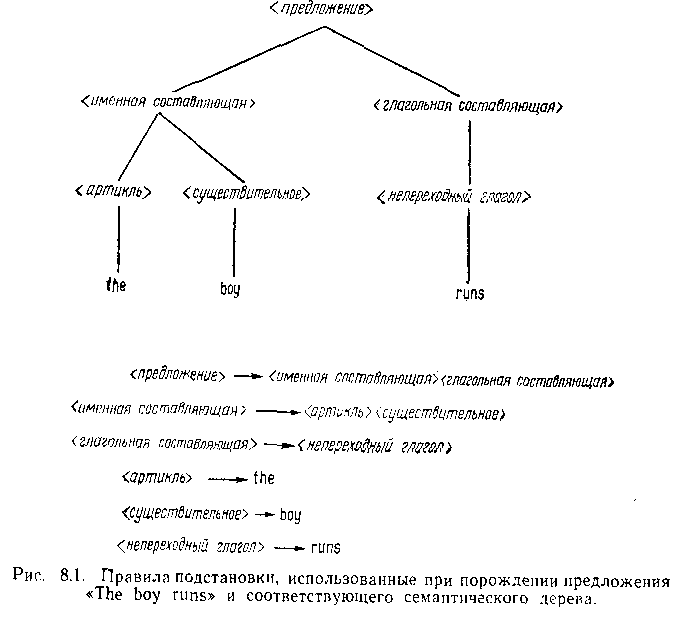
В данном случае будет полезно сравнить приведенное выше определение формальной грамматики со стандартными понятиями грамматики английского языка. Это поможет читателю лучше понять обозначения и терминологию. Рассмотрим простое предложение The boy runs (мальчик бежит). На рис. 8.1 показана запись этого предложения в виде дерева. Порождение данного предложения происходит следующим образом. Мы начинаем с абстрактного понятия, которое называем (предложение). На этом этапе (предложение)—не более чем синтаксическое понятие, представляющее see правильные предложения английского языка. Затем мы заменяем (предложение) на (именная составляющая) плюс (глагольная составляющая). В теории формальных языков мы всегда начинаем с описанного выше символа S. Правила подстановки грамматики G вида (8.2.1) соответствуют в английском языке следующему, например, замещению: (предложение) заменяется на (именная составляющая) и (глагольная составляющая). Как видно из рис.8.1, в результате дальнейшего применения грамматических правил или правил подстановки (именная составляющая ) сводится к (артикль) плюс (существительное), а (глагольная составляющая) к (непереходный глагол). Наконец, применение правил подстановки, отображающих (артикль) в «the», (существительное) в «boy», а (непереходный глагол) в «runs», приводит к искомому предложению. Нетерминальные символы грамматики G соответствуют синтаксическим категориям (именная составляющая), (глагольная составляющая), (артикль), (существительное ) и т д., тогда как терминальные символы соответствуют словам естественного языка «the», «boy», «runs». Другими словами, нетерминальные символы играют роль переменных, терминальные—- констант,
Язык, порождаемый грамматикой G и обозначенный L(G),— это множество цепочек, удовлетворяющих двум условиям:
1) каждая цепочка составлена только из терминальных символов (т. е., является терминальным предложением), 2) каждая цепочка может быть выведена из S путем соответствующего применения правил подстановки из множества Р.
В этой главе используются следующие обозначения. Нетерминальные символы обозначаются прописными буквами S, А, В, С, ... . Строчные буквы из первой половины латинского алфавита а, Ь, с. ... используются для терминальных символов. Цепочки терминальных символов обозначаются строчными буквами из конца латинского алфавита v, w. x. .... Смешанные цепочки терминальных и нетерминальных символов представлены строчными буквами греческого алфавита α, β, γ, δ, ... .
Множество
Р правил подстановки состоит из выражений
вида α→β, где α—цепочка
в словаре V+
н β—цепочка
в словаре
V*.
Иначе говоря, символ
→ означает
замещение цепочки α цепочкой β. Символ
![]() будет использован для обозначения
операций вида γαδ
будет использован для обозначения
операций вида γαδ![]() γβδ
в грамматике
G, т. е.
γβδ
в грамматике
G, т. е.
![]() указывает
на замещение а
на β в результате применения правила
подстановки
α→β,
при этом γ и δ остаются неизменными. В
тех случаях, когда ясно, о какой грамматике
идет речь, G
опускается и используется символ
=>.
указывает
на замещение а
на β в результате применения правила
подстановки
α→β,
при этом γ и δ остаются неизменными. В
тех случаях, когда ясно, о какой грамматике
идет речь, G
опускается и используется символ
=>.
Пример. Рассмотрим грамматику G=(VN, VT, P. S), где VN ={S}, VT = {а.Ь} и
Р= {S->aSb, S->ab}. Применяя первое правило m— 1 раз, получаем
S => aSb => aaSbb=>a3Sb3=> … =>am-1Sbm-1
Применение второго правила приводит к цепочке
am-1Sbm-1 => ambm
Язык, порождаемый этой грамматикой, состоит, как мы видим, исключительно из цепочек подобного вида, причем длина конкретной цепочки зависит от т. Язык L(G) можно представить в виде L(G)= { ambm| m>=1}. Стоит отметить, что простая грамматика, описанная в этом примере, обладает способностью порождать язык с бесконечным числом цепочек или предложений. В следующих разделах будет видно, как это свойство создает трудности при использовании этих понятий в распознавании образов.