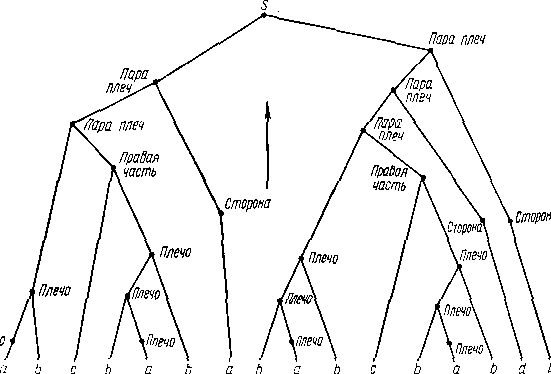
Распознавание образов / Lection_RECOGNITION / lecture7 / short_lecture
.docСИНТАКСИЧЕСКОЕ РАСПОЗНАВАНИЕ ОБРАЗОВ
синтаксическое распознаванием образов - лингвистическое распознавание, структурное распознавание, распознавание методами теории формальных грамматик.
Основным отличием синтаксического распознавания образов от всех рассмотренных ранее является непосредственное использование структуры образов в процессе распознавания
Определения
Алфавит—любое конечное множество символов.
Предложение в некотором алфавите—произвольная цепочка конечной длины, состоящая из символов этого алфавита. Например, для алфавита {0, 1} допустимыми являются следующие предложения: {О, 1. 00, 01, 10, ...}- Обычно для обозначения предложения используют также термины цепочка и слово.
Предложение, не содержащее ни одного символа, называется пустым предложением. В дальнейшем пустое предложение будет обозначаться So. Для произвольного алфавита V знак V* будет использоваться для обозначения множества всех предложений, составленных из символов алфавита V. включая пустое предложение. Символ V+ будет обозначать множество предложений V*— so. Если, например, задан алфавит V = [a,. b}, то
V* = {so, а, b, аа, аb, bа, ...} и V+= {а, b, аа, аb, bа, . ..}.
Язык—произвольное множество (не обязательно конечное) предложений в некотором алфавите.
Так же как и в естественных языках, серьезное изучение теории формальных языков должно концентрироваться на грамматиках и их свойствах.
Грамматикa
это четверка G = (VN, Vt ,P, S),
где
VN - множество нетерминальных символов (переменных)
Vt - множество терминальных символов (констант)
P- - множество грамматических правил или правил подстановки
S- начальный или корневой символ
Предполагается, что S принадлежит множеству VN и что VN и VT — непересекающиеся множества. Алфавит V является объединением алфавитов VN и VT..
Язык, порождаемый грамматикой G и обозначенный L(G),— это множество цепочек, удовлетворяющих двум условиям:
1) каждая цепочка составлена только из терминальных символов (т. е., является терминальным предложением), 2) каждая цепочка может быть выведена из S путем соответствующего применения правил подстановки из множества Р.
Множество
Р правил подстановки состоит из выражений
вида α→β, где α—цепочка
в словаре V+
н β—цепочка
в словаре
V*.
Иначе говоря, символ
→
означает замещение цепочки α цепочкой
β. Символ
![]() будет использован для обозначения
операций вида γαδ
будет использован для обозначения
операций вида γαδ![]() γβδ
в грамматике
G, т. е.
γβδ
в грамматике
G, т. е.
![]() указывает
на замещение а
на β в результате применения правила
подстановки α→β, при этом γ и δ
остаются неизменными. В тех случаях,
когда ясно, о какой грамматике идет
речь, G
опускается и используется символ
=>.
указывает
на замещение а
на β в результате применения правила
подстановки α→β, при этом γ и δ
остаются неизменными. В тех случаях,
когда ясно, о какой грамматике идет
речь, G
опускается и используется символ
=>.
Пример. Рассмотрим грамматику G=(VN, VT, P. S), где VN ={S}, VT = {а,b} и
Р= {S->aSb, S->ab}. Применяя первое правило m— 1 раз, получаем
S => aSb => aaSbb=>a3Sb3=> … =>am-1Sbm-1
Применение второго правила приводит к цепочке
am-1Sbm-1 => ambm
Типы грамматик
Неограниченная грамматика характеризуется правилами подстановки α→β, где α—цепочка алфавита V+ а β—цепочка алфавита V*.
Грамматика непосредственно составляющих (грамматика контекстная) характеризуется правилами подстановки вида α1Aα2 → α1βα2 ,где α1 и α2—элементы алфавита V*, β принадлежит V+, а А принадлежит VN. Эта грамматика допускает замещение нетерминального символа А цепочкой β только в том случае, если А появляется в контексте α1Aα2, составленном из цепочек α1 и α2.
Бесконтекстная грамматика (контекстно-свободная грамматика, КС-грамматика) характеризуется правилами подстановки вида А—>β, где А принадлежит множеству VN и β принадлежит множеству V+. Само название «бесконтекстная» указывает на то, что переменная A может замещаться цепочкой β независимо от контекста, в котором появляется А.
Регулярная (или автоматная) грамматика — это грамматика с правилами подстановки вида А —>aB или А—>a, где А и В—переменные из VN, а—терминальный символ из VT. Альтернативными допустимыми правилами подстановки являются А —>Bα и А—>а. Выбор одного из этих двух типов правил исключает, однако, применение правил другого типа.
Примеры грамматик
а) Неограниченная грамматика
G=(VN, Vt, P, S)
при
VN ={S, А, В}, Vt = { a, b, с}
Р: S —> аAbc
Аb —> bA
Ac —> Bbcc
bB —> Bb
аB —> ааA
аB —> s0
порождает предложения вида х= anbn+2c n+2, где п>=0 означает длину цепочки символов. Например, для порождения цепочки х = a0b2c2 = bbсс мы применяем первые четыре правила и затем последнее, т, е,
S => аAbc => аbAc => аb Bbcc => аBbbcc =>bbcc.
б) Грамматика непосредственно составляющих
G=(VN, Vt, P, S)
при
VN ={S, А, В}, Vt = { a, b, с}
Р: S —> аbc
S —> аAbc
Аb —> bA
Ac —> Bbcc
bB —> Bb
аB —> ааA
аB —> аа
порождает предложения вида х = а п с п где п>= I
(в) Бесконтекстная грамматика
G=(VN, Vt, P, S)
при
VN ={S }, Vt = { a, b }
Р: S —> аb
S —> аSb
порождает цепочки вида х = а пb п где п>= 1,
(г) Регулярная грамматика
G=(VN, Vt, P, S)
при
VN ={S }, Vt = { a, b }
Р: S —> а
S —> b
S —> аS
S —> bS
порождает цепочки, состоящие из символов а и b.
ПОСТАНОВКА ЗАДАЧИ СИНТАКСИЧЕСКОГО
РАСПОЗНАВАНИЯ ОБРАЗОВ
Предположим, у нас имеются два класса образов ω1 и ω2 и пусть образы этих классов могут быть построены из признаков, принадлежащих некоторому конечному множеству. Назовем эти признаки терминалами и обозначим множество терминалов символом VТ в соответствии с системой обозначений. В синтаксическом распознавании образов терминалы называются также непроизводными символами (элементами). Каждый образ может рассматриваться как цепочка или предложение, поскольку он составлен из терминалов множества VТ. Допустим, что существует грамматика G, такая, что порождаемый ею язык состоит из предложений (образов), принадлежащих исключительно одному из классов, скажем ω1 . Очевидно, что эта грамматика может быть использована в целях классификации образов, так как заданный образ неизвестной природы может быть отнесен к ω1, если он является предложением языка L{G}. В противном случае образ приписывается классу ω2. Например, бесконтекстная грамматика G=(VN, Vt, P, S) при VN ={S }, Vt={a,b} и множестве правил подстановки Р= {S —> аaSb, S —> aab} обладает способностью порождать лишь предложения, содержащие вдвое больше символов а, чем b. Если мы сформулируем гипотетическую задачу разбиения образов нa два класса, причем объекты класса ω1—это цепочки вида aab. aaaabb и т. д., а объекты класса ω2 содержат одинаковое число символов а и b (т. e. аb. аabb и т. д.), то очевидно, что классификация заданной цепочки производится простым определением того, может ли данная цепочка порождаться грамматикой G, рассмотренной выше. Если может, то объект принадлежит ω1 если нет — он автоматически приписывается классу ω2. Процедура, используемая для определения, является или не является цепочка предложением, грамматически правильным для данного языка, называется грамматическим разбором.
Бесконтекстная грамматика G, способная порождать квадраты,
задается набором G = (VN, VT, Р, S) при
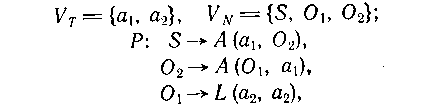
где А{х,у) и L(x,y) читаются соответственно
«.х расположен над у» и «х расположен слева от у».
![]()
это правило заменяет начальный символ непроизводным элементом a1,
расположенным над некоторым пока еще не определенным объектом O2.
Правило
![]()
заменяет неопределенный объект О2 другим объектом O1,
еще не определенным, расположенным над горизонтальным отрезком
O1 заменяется на два вертикальных непроизводных элемента
![]() посредством
применения правила
посредством
применения правила
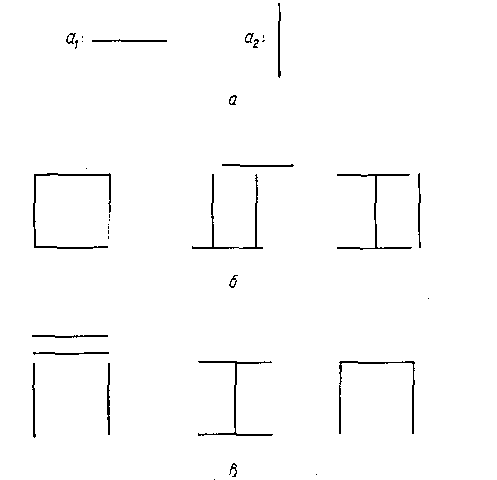
Образы, использованные для иллюстрации
синтаксически-ориентированного грамматического разбора,
a — непроизводные элементы образов;
б—образы, поддающиеся разбору с помощью описанной схемы;
в —образы, не поддающиеся разбору с помощью описанной схемы.
Бесконтекстная грамматика, способная классифицировать
V-образные и телоцентрические хромосомы

непроизводные элементы грамматики
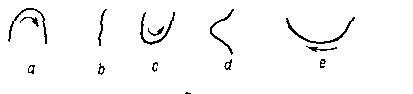
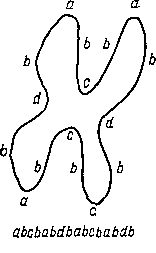
357

телоцентрическая хромосома V- образная хромосома
Восходящий грамматический разбор представляющей хромосому
цепочки abcbabdbabcbabdb.