

III. Построение трендовых моделей и прогнозирование
Уровень динамического ряда может быть представлении как функция 4 компонент: y=f(T, S,C,E), где Т – трендовая компонента.
Трендовая компонента – результат влияния основных факторов, которые действуют в течение длительного периода времени и вырабатывают основную тенденцию временного ряда, т.е. тренд.
Основная задача при изучении рядов динамики - выявление и описание тренда. Тенденция может проявляться либо в увеличении уровней динамического ряда, либо в снижении, либо на разных отрезках времени могут прослеживаться разные тенденции.
Для выявления тренда используются приемы выравнивания динамических рядов:
механическое выравнивание;
метод укрупнения интервалов;
метод скользящей средней;
аналитическое выравнивание.
Применение в анализе рядов динамики методов укрупнения интервалов и скользящей средней позволяет выявить тренд для его описания, но получить обобщенную тенденцию, количественную статическую оценку тренда посредством этих методов невозможно. Решение этой более высокого порядка задачи – измерение тренда – достигается методом аналитического выравнивания.
Аналитическое выравнивание, т. е. выравнивание с помощью аналитических формул. В этом случае динамический ряд выражается в виде функции у (t), в которой в качестве основного фактора принимается время t, и изменения аргумента функции определяют расчетные значения уt.
Таким образом, аналитическое выравнивание позволяет выявить как тенденцию ряда, так и аналитическую формулу тренда, т.е. с помощью уравнения регрессии описать тренд динамического ряда.
В данной курсовой работе будут рассмотрено уравнение тренда, представленное следующими функциями:
линейная
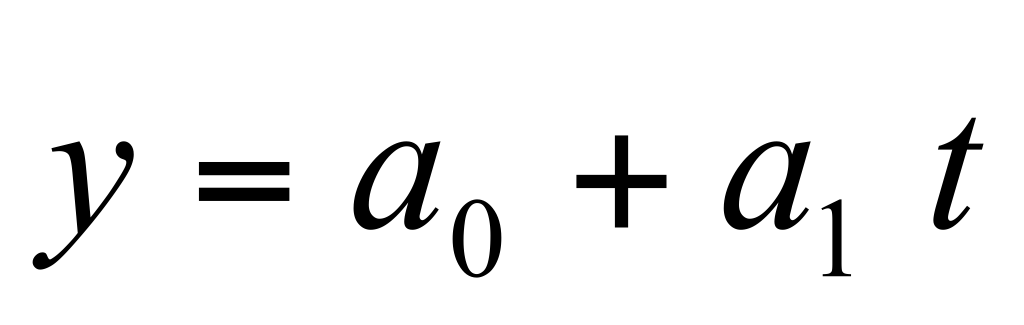 ;
;парабола
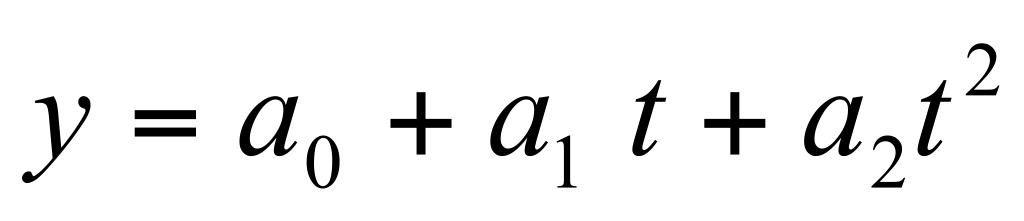 ;
;степенная

Процедура оценки качества включает 3 момента:
1. Оценка статистической значимости параметров уравнения ( по t ст-ке)
2. Оценка статистической значимости уравнения в целом и значимости коэффициента детерминации (по F-критерию Фишера)
3. осуществляется оценка остатков трендовой модели на наличие
автокорреляции.
Линейная модель
Для экспорта
Таблица 6

y= -2, 32218+1,21416t
![]() =
0,94298754
=
0,94298754
Таблица 7
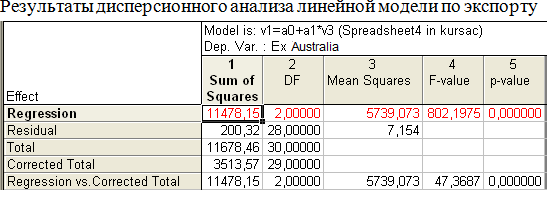
Таблица 8
Таблица наблюдаемых, прогнозных значений и остатков

Для импорта
Таблица 9
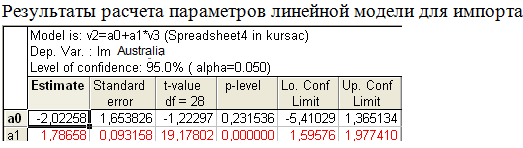
y= -2,02258+1,78658t
= 0,9292566
Таблица 10
Результаты дисперсионного анализа параболы по импорту

Таблица 11
Таблица наблюдаемых, прогнозных значений и остатков

Парабола
Для экспорта
Таблица 12

y=0,391984+0,705259t+0,016416![]()
= 0,9528473
Таблица 13

Таблица 14

Для импорта
Таблица 15
Результаты расчета параметров параболы для импорта

y=3,186851+0,809817t+0,031509
= 0,92722828
Таблица 16

Таблица 17

Степенная функции
Для экспортая

y=4,600160*1,074105t
= 0,94652151
Таблица 19

Таблица 20
Таблица наблюдаемых, прогнозных значений и остатков
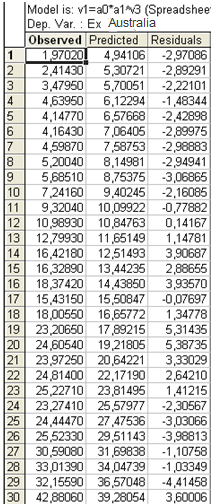
Для импорта
Таблица 21

y=7,453544*1,071712t
= 0,93209356
Таблица 22

Таблица 23

Таблица 24
Таблица параметров моделей и таблица дисперсионного анализа по экспорту
Вид тренда |
t |
t |
t |
F |
|
Линейная |
-2,31844 |
21,52024 |
X |
802,1975 |
0,94298754 |
парабола |
0,2711123 |
3,280413 |
2,439563 |
631,3548 |
0,9528473 |
Степенная функция |
8,6249 |
212,6304 |
X |
625,4439 |
0,94652151
|
линейная
 ;
;парабола ;
степенная
Таблица 25
Таблица параметров моделей и таблица дисперсионного анализа по импорту
Вид тренда |
t |
t |
t |
F |
|
Линейная |
-1,22297 |
19,17802 |
X |
690,6398 |
0,9292566 |
парабола |
1,389853 |
2,375066 |
2,952395 |
590,2230 |
0,92722828 |
Степенная |
9,4713 |
232,3369 |
X |
720,0779 |
0,93209356 |
Как видно из таблиц для экспорта и импорта подходит одна и та же модель – степенная. Поскольку в ней все параметры значимы, а также доля объясненной дисперсии больше, чем в других моделях, где все параметры также значимы.
Параметры обоих уравнений статистически значимы так, как значение t-статистики больше табличного (больше 2).
Далее необходимо проанализировать выбранные модели тренда с точки зрения их адекватности реальным тенденциям исследуемого временного ряда через оценку надежности по F-критерию Фишера. В данном случае расчетные значения критерия Фишера равны: по экспорту — 625,4439, а по импорту — 720,0779.
Оценка автокорреляции в остатках экспорта и импорта
Разность между фактическими уровнями динамического ряда и теоретическими, то есть выровненными (рассчитанными по уравнению тренда) называется остатками.
Целью оценки автокорреляции в остатках является оценка качества модели динамического ряда.
Автокорреляция остатков означает наличие тенденции в остатках.
Основной задачей при построении уравнения тренда является точное и полное описание основной тенденции изучаемого ряда, поэтому наличие автокорреляции в остатках будет означать, что уравнение тренда не полностью описывает основную тенденцию ряда.
Таким образом, при наличии автокорреляции остатков, уравнение не может быть использовано для прогнозирования.
0,649065/0,173805=3,734
0,504585/0,170783=2,954
0,373190/0,167705=2,225
0,192671/0,164570=1,170<2
0,074914/0,161374=0,464<2
рис.2
Автокорреляционная функция остатков степенной функции тренда экспорта

Поскольку коэффициенты значимы при лаге, равном 1,2,3, то это означает присутствие автокорреляции в остатках. А значит, уравнение нельзя использовать для прогнозирования
0,686712/0,173805=3,95
0,449113/0,170783=2,62
0,170629/0,167705=1,01<2
0,007772/0,164570=0,04<2
-0,088710/0,161374=-0,54<2
рис.3
Автокорреляционная функция остатков степенной модели тренда импорта

Аналогично для уравнения тренда по импорту, поскольку при лаге, равном 1,2, коэффициенты значимы, это означает присутствие автокорреляции в остатках. А значит, уравнение нельзя использовать для прогнозирования, поскольку данное уравнение не учитывает тенденцию, присутствующую в остатках.
Доверительные интервалы прогноза
Одна из основных задач, возникающих при прогнозировании , заключается в определении доверительных интервалов прогноза.
Доверительный интервал рассчитывается по следующей формуле:
![]() ,
где
,
где
![]()
Значение t берется из таблицы Стьюдента и зависит от выбранной доверительной вероятности (95%). S – стандартная ошибка.
в нашем случае построение доверительного интервала невозможно, поскольку модель недостоверна.