

Параметры линейной парной регрессии для наиболее подходящего фактора X.
Из корреляционного анализа было видно, что самый сильный фактор,
оказывающий влияние на Y (Прибыль), фактор Х3 Основные средства. По этому фактору строим Регрессию с помощью инструмента Регрессия в Анализе данных (рис. 8):


Рисунок 9. Получение табличного значения F-критерия
Оценка качества построенной модели
Для оценки качества модели определим коэффициент детерминации. Значение коэффициента детерминации можно найти в таблице Регрессионный анализ (см. рис. 8).
R2 = 0,827.
Коэффициент детерминации показывает долю вариации результативного признака под воздействием изучаемых факторов. Следовательно, около 88% вариации зависимой переменной учтено в модели и обусловлено влиянием факторов, включенных в модель.
Точность модели оценим с помощью средней ошибки аппроксимации:
А
= 1/n
 (рис. 10)
(рис. 10)

Рисунок 10. Определение точности модели.
Проверку значимости уравнения регрессии оценим с помощью F-критерия Фишера:
F
=

Значение F-критерия Фишера можно найти в таблице Дисперсионный анализ протокола Excel (см. рис. 8). F =230,99.
Поскольку Fрасч > Fтабл, уравнение регрессии следует признать значимым, то есть его можно использовать для анализа и прогнозирования.

Рисунок 11. Графики остатков по каждому из факторов
Из графиков, представленных на рисунке 11 видно, что дисперсия остатков более всего нарушена по отношению к фактору Краткосрочные обязательства.
Ранжирование компаний по степени эффективности.
Используя
результаты регрессионного анализа,
выполним ранжирование компаний по
степени эффективности. Для этого
воспользуемся функцией Анализ данных
– регрессия – за входной интервал Y
мы возьмем все значения по Y,
а за входной интервал Х мы возьмем все
значения по факторам Х2, Х3 и Х6 – выведем
остатки – ок. Далее сортируем столбцы
«Наблюдение»,
«Предсказанное Y»
и «Остатки» по
остаткам (рис. 12).
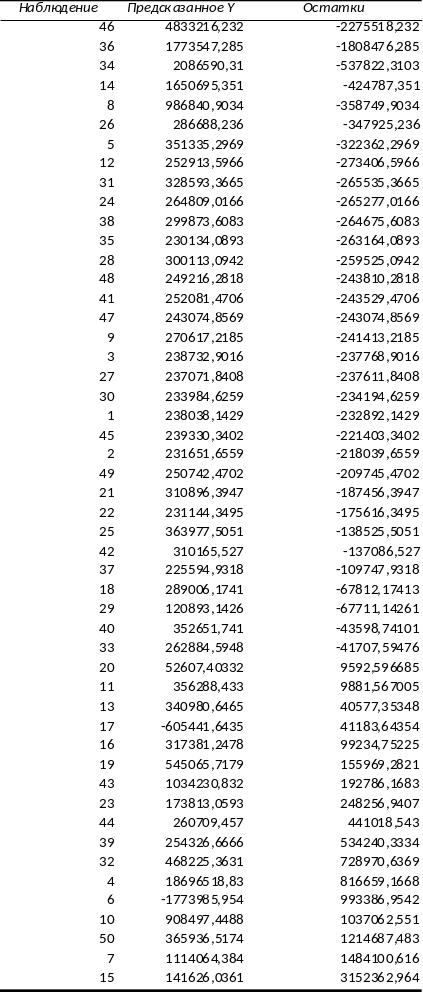
Рисунок 12. Ранжирование компаний по эффективности
Вывод: Самый отрицательный остаток у компании ОАО Нефтегазовая компания "Славнефть" - самая неэффективная компания.
9. Составление уравнений нелинейной регрессии:
А. гиперболической;
Б. степенной;
В. Показательной.
Для построения уравнений нелинейной регрессии нам нужно выполнить следующие действия (выполняем по фактору Х3, рис. 13):

Рисунок 13. Данные фактора Х3
Выделяем значения факторов Y и Х3 – сортировка – по Y.
Выделяем другим цветом убыточные предприятия и копируем рядом прибыльные – сортировка – по Х3 (рис. 14).
 Рисунок
14. Сортировка по фактору Y
и выделение отдельно
Рисунок
14. Сортировка по фактору Y
и выделение отдельно
прибыльных компаний по фактору Х3.
с.Далее в новом столбце считаем 1/Х, LNX и LNY (рис. 15).

Рисунок 15. Данные для построения уравнений нелинейных регрессий
Теперь можно строить гиперболическую, степенную и показательную модели нелинейной регрессии.
Гиперболическая:
Анализ данных – регрессия – входной интервал Y - весь Y, входной
интервал X- 1/Х – ок. R-квадрат = 0,72–означает, что прогноз по данной модели делать нельзя (рис. 16).
Нелинейная степенная.(рис.16)

Нелинейная показательная.(рис 17)


Вывод: нелинейную гиперболическую модель нельзя использовать при прогнозировании. Прогноз можно осуществить либо по нелинейной степенной модели, т.к. R-квадрат (степ.) > R-квадрат (показ.), либо по двухфакторной модели с факторами Х3 и Х4.
