

5.6 Экспертные системы нового поколения
В настоящее время специалисты различных отраслей (инженеры, конструкторы, технологи, врачи, адвокаты и т. д.) проявляют большой интерес к экспертным системам. Созданы десятки коммерческих экспертных систем, преимущественно в США и Западной Европе. Опыт их проектирования и эксплуатации позволил выявить ряд требований к экспертным системам нового поколения. К числу основных требований относятся:
— разработка эффективных средств для создания и поддержания больших баз знаний, ибо современные ЭС (при отсутствии таких средств) вынужденно ориентируются на узкие проблемные области (см. гл. 2);
— разработка систем объяснения, дающих объяснения в терминах общих принципов построения баз знаний, в частности метазнаний, т. е. знаний системы о себе и своих функциональных возможностях, в том числе и о том, чего она не может делать;
— автоматизация процесса извлечения знаний из эксперта с помощью реализации индуктивных и правдоподобных схем рассуждения;
— автоматизация процесса выбора стратегий в зависимости от решаемой задачи;
— работа в динамически меняющейся среде, т. е. построение динамических экспертных систем;
— создание гибридных (интегрированных) экспертных систем, объединяющих возможности традиционных экспертных систем, систем управления баз знаний (баз данных) и интеллектуальных пакетов прикладных программ;
— аппаратная реализация экспертных систем или ее подсистем, обеспечивающая значительное повышение их вычислительной мощности, быстродействия и надежности.
Реализация этих функций в экспертных системах нового поколения позволит вплотную подойти к достижению вычислительной машиной уровня высококвалифицированного специалиста данной предметной области. Это, в свою очередь, будет способствовать дальнейшему расширению сферы применения ЭВМ как в научных исследованиях, экономике, промышленности, так и в быту.
Лекция № 16. Решение плохо формализуемых задач экспертизы и диагностики.
Логическое программирование
Как отмечалось в гл. 1, в число основных компонентов интеллектуального интерфейса между пользователем и ЭВМ входят решатели задач, позволяющие конечным пользователям решать прикладные задачи при минимальном объеме знаний о программировании. Эти задачи, как правило, плохо формализуемы, т. е. отсутствуют строгие аналитические методы их решения, и человек обычно использует интуитивные представления, эмпирические правила и эвристические соображения.
Работы в области создания решателей, реализующих некоторую формализованную схему рассуждений при том или ином способе представления знаний, ведутся активно и в нашей стране, и за рубежом. Они особенно активизировались в связи с реализацией в различных странах проектов ЭВМ пятого поколения. Разработка решателей— одно из мало проработанных звеньев этих проектов.
В настоящей главе рассматриваются перспективные подходы к построению решателей задач конечного пользователя. К ним относятся подход, использующий дедуктивные схемы рассуждения, подход, использующий индуктивные схемы рассуждения, подход, реализующий метод программируемых доказательств, и интегральный подход, позволяющий использовать для решения одного и того же класса задач несколько методов одновременно.
К дедуктивным подходам относится прежде всего логическое программирование, в котором для представления знаний используется формальный аппарат исчисления предикатов первого порядка и его расширения [4]. Под исчислением (или дедуктивной системой) понимается система, в которой существует некоторое число исходных объектов (аксиом) и некоторое число правил построения (правил вывода) новых объектов из исходных и уже построенных. При этом в исчислениях (в отличие от алгоритмов) порядок применения правил вывода может быть произвольным. Можно считать, что исчисление предикатов является расширением классического исчисления высказываний, в котором высказывание рассматривается как единое целое, не обладающее внутренней структурой, а истинность или ложность высказывания фиксирована. В исчислении предикатов основным объектом является переменное высказывание (предикат), истинность или ложность которого зависит от значений входящих в него переменных. Так, истинность предиката «х был физиком» зависит от значения переменной х. Если х — это П. Капица, то предикат истинен, если х — М. Лермонтов, то он ложен.
Исчисление
предикатов включает в себя все формулы
исчисления высказываний, а также формулы,
содержащие кроме символов высказываний
предикатные символы с к![]() ванторами.
Например, утверждение читается так:
«для любого х если Р(х), то имеет место
и Q(x)».
Выделенное подмножество тождественно
истинных формул, истинность которых не
зависит от истинности входящих в них
высказываний, называется аксиомами.
В исчислении предикатов имеется множество
правил вывода. В качестве прим
ванторами.
Например, утверждение читается так:
«для любого х если Р(х), то имеет место
и Q(x)».
Выделенное подмножество тождественно
истинных формул, истинность которых не
зависит от истинности входящих в них
высказываний, называется аксиомами.
В исчислении предикатов имеется множество
правил вывода. В качестве прим![]() ера
приведем классическое правило modus
ponens:
которое читается так: «если
истинна формула А и истинно, что из А
следует В, то истинна формула В». Формулы,
находящиеся над чертой, называются
посылками вывода, а под чертой —
заключением. Это правило вывода
формализует основной закон дедуктивных
систем: из истинных посылок всегда
следуют истинные заключения. Аксиомы
и правила вывода исчисления предикатов
первого порядка задают основу формальной
дедуктивной системы, в которой происходит
формализация схемы рассуждения в
логическом программировании. Решаемая
задача представляется в виде утверждений
(аксиом) F\,
Ft,
..., Fn
исчисления предикатов первого порядка.
Цель задачи В также записывается в виде
утверждения, справедливость которого
следует установить или опровергнуть
на основании аксиом и правил вывода
формальной системы. Тогда решение задачи
(достижение цели задачи) сводится к
выяснению логического следования
(выводимости) целевой формулы В из
заданного множества формул (аксиом) Fi,
Ft,
..., Fn.
Такое выяснение равносильно доказательству
общезначности (тождественно-истинности)
формулы F1
& F2
&…& Fn
→ B
или не выполнимости (тождественно-ложности)
формулы F1
& F2
&…& Fn
& ┐ B.
ера
приведем классическое правило modus
ponens:
которое читается так: «если
истинна формула А и истинно, что из А
следует В, то истинна формула В». Формулы,
находящиеся над чертой, называются
посылками вывода, а под чертой —
заключением. Это правило вывода
формализует основной закон дедуктивных
систем: из истинных посылок всегда
следуют истинные заключения. Аксиомы
и правила вывода исчисления предикатов
первого порядка задают основу формальной
дедуктивной системы, в которой происходит
формализация схемы рассуждения в
логическом программировании. Решаемая
задача представляется в виде утверждений
(аксиом) F\,
Ft,
..., Fn
исчисления предикатов первого порядка.
Цель задачи В также записывается в виде
утверждения, справедливость которого
следует установить или опровергнуть
на основании аксиом и правил вывода
формальной системы. Тогда решение задачи
(достижение цели задачи) сводится к
выяснению логического следования
(выводимости) целевой формулы В из
заданного множества формул (аксиом) Fi,
Ft,
..., Fn.
Такое выяснение равносильно доказательству
общезначности (тождественно-истинности)
формулы F1
& F2
&…& Fn
→ B
или не выполнимости (тождественно-ложности)
формулы F1
& F2
&…& Fn
& ┐ B.
Из практических соображений удобнее использовало доказательство от противного, т. е. доказывать невыполнимость формулы. На доказательстве от противного основано и ведущее правило вывода, используемое в логическом программировании, — принцип резолюции. При использовании его формулы исчисления предикатов с помощью несложных преобразований приводятся к так называемой дизъюнктивной форме, т. е. представляются в виде набора дизъюнктов. При этом под дизъюнктом понимается дизъюнкция литералов, каждый из которых является либо предикатом, либо отрицанием "r.onuK-ятя. Приведем пример дизъюнкта:
![]()

Дизъюнкты, используемые в логическом программировании, можно упростить следующим образом: кванторы всеобщности опустить, предикаты переписать в бесскобочном виде, а связку ┐ заменить на импликацию (←) или слово «если». Тогда выражение (3.2) примет такой вид:
х уважать Ключевский, если х знать историю,
ч![]() то
читается так: «каждый, кто знает историю,
уважает Ключевского». Кроме того,
дизъюнкты, все литералы которых
отрицательны, обычно переписываются в
эквивалентную форму отрицательной
конъюнкции. Например формула перепишется
в виде
то
читается так: «каждый, кто знает историю,
уважает Ключевского». Кроме того,
дизъюнкты, все литералы которых
отрицательны, обычно переписываются в
эквивалентную форму отрицательной
конъюнкции. Например формула перепишется
в виде
![]()
Если в формуле (3.3) принять, что предикат Р — это «знать», а константы Ci и С2 — это «физика» и «история» соответственно, то получим
![]()
Выражение (3.4) в упрощенном виде можно переписать как
![]()
и прочитать как запрос: «кто знает физику и историю одновременно?».
Таким образом, и условия решаемых задач (факты), и целевые утверждения задач (запросы) можно выразить в дизъюнктивной форме логики предикатов первого порядка.
Вернемся к принципу резолюции [5]. Главная идея этого правила вывода заключается в проверке того, содержит ли множество дизъюнктов R пустой (ложный) дизъюнкт ?i. При положительном ответе множество R (и соответствующая ему формула) невыполнимо (противоречиво). При отрицательном ответе выводятся новые дизъюнкты до тех пор, пока не будет получен пустой дизъюнкт, что всегда будет иметь место для противоречивого R. Таким образом, принцип резолюции можно рассматривать как правило вывода, с помощью которого порождаются новые дизъюнкты из R. В общем случае каждый шаг резолюции начинается с некоторой пары дизъюнктов (предков) такой, что некоторый литерал А в одном из дизъюнктов должен быть сделан дополнительным литералу В другого дизъюнкта из пары. Заметим, что дополнительными называются литералы А и ~\ А. Чтобы сделать литералы А и В дополнительными, необходимо провести их унификацию, т. е. сделать их идентичными с помощью некоторой подстановки 9, называемой унификатором'. А6 == В 9. Тогда говорят, что два выбранных литерала резольвируют. Затем с помощью правила резолюции выводится новый дизъюнкт — резольвента — следующим образом. Литералы дизъюнктов-предков, за исключением тех, которые резольвировали, объединяются и к результату применяется подстановка 6.

Правило резолюции обладает свойством полноты в том смысле, что с помощью него всегда можно найти пустой дизъюнкт, если исходное множество дизъюнктов R противоречиво. Однако вследствие неразрешимости логики предикатов первого порядка для выполнимого (непротиворечивого) множества дизъюнктов процедура, основанная на принципе резолюции, может работать бесконечно долго.
Обычно резолюция применяется в логическом программировании в совокупности с прямым или обратным методом рассуждения. Прямой метод (от посылок) из посылок А, А —>- В выводит заключение В (правило modus ponens). Основной недостаток прямого метода рассуждения состоит в его ненаправленности: повторные применения метода обычно приводят к резкому росту промежуточных заключений, не связанных с целевым заключением.
Обратный метод (от цели) является направленным: из желаемого заключения В и тех же посылок он выводит новое подцелевое заключение А. Каждый шаг вывода в этом случае всегда связан с первоначально поставленной целью. Для использования правила резолюции необходимо, чтобы доказательство того, что данная посылка А влечет желаемое (целевое) заключение С, было переформулировано в утверждение, что А несовместимо с~1С. Например, чтобы доказать утверждение Р из посылок Q, Q ->- Р, обратное рассуждение с помощью правила резолюции выводит ~|Q (из|Р и 0->-Р), а затем выводит пустой дизъюнкт (опровержение) (из~10 и Q).
Существенный недостаток принципа резолюции заключается в формировании на каждом шаге вывода множества резольвент — новых дизъюнктов, большинство из которых оказываются лишними. В связи с этим разработаны различные модификации принципа резолюции, использующие более эффективные стратегии поиска и различного рода ограничения на вид исходных дизъюнктов. В этом смысле наиболее удачной и популярной системой является система ПРОЛОГ, которая использует специальные виды дизъюнктов, называемые дизъюнктами Хорна. Кратко рассмотрим эту систему, тем более что под логическим программированием в узком смысле слова обычно понимают программирование на языке ПРОЛОГ (PROgramming in LOGic).
По определению, дизъюнктами Хорна являются дизъюнкты, имеющие не более одного положительного литерала. Они могут быть трех типов:
(1) допущениями без условий (или фактами)
В(t)

Для реализации очень важен тот факт, что дизыиммы Хорна обладают простой процедурной интерпретацией. Дизъюнкты типа (1) и (2) интерпретируются как процедуры, а типа (3) — как целевые утверждения. Так, дизъюнкт типа (2) интерпретируется как процедура с заголовком В (<), телом которой является вызов процедур Ai (t), Аг (t), ..., An (t), а дизъюнкт типа (3) — как последовательность вызовов процедур Ci (<), €2 (t),..., С* {t). Тогда каждый шаг обратного рассуждения есть управление вызовом процедуры, которое начинается с выделения вызова некоторой процедуры С, (<) из текущей цели. Затем выделяется некоторая процедура, заголовок которой (положительный литерал, например В(() в выражении (2)) унифицируется с помощью некоторой подстановки 9 с выбранным вызовом С; {t). Далее выделяется тело процедуры (в данном примере В (()), представляющее собой, в свою очередь, последовательность вызова других процедур (в данном примере Ai (t), A^^t), .,., An (()). Унификатор 9 применяется к результату. Процесс итеративно повторяется. Аргументы литералов (предикатов) соответствуют параметрам вызванных процедур. Унификация интерпретируется как связь данных между вызовами и процедурами.
Процесс доказательства (или вычисления) целевого утверждения S в общем случае можно представить следующим образом [6].
Пусть целевое утверждение S имеет вид-t- С>, ..., С,, ..., С); и в нем выделен литерал С, и пусть существует правило Г = В -«- Ai, Аг, ..., An. Тогда если 9 — унификатор для литералов С, и В, то говорят, что подцель S' ==-»- 9 (Ci, ..., C,-i, Ai, ..., An, В, Cj+i,..., Q) выводится из S с помощью правила Г и подстановки 9.
Получение S' из S является элементарным шагом в языке ПРОЛОГ. Он может завершиться и неудачей, так как может не существовать унификатора для С, и В.
Выводом (вычислением) целевого утверждения S назы-вается последовательность промежуточных подцелей Si, Sz, ..., Sm такая, что Si = S и S,+i выводима из S. Если из подцели Sm невыводима ни одна подцель, то вычисление считается конечным. При этом если Sm — не пустой дизъюнкт, то вывод является тупиковым, а если Sm — пустой дизъюнкт, то вывод является успешным и с ним связывается подстановка 9 == 9m-i, 9m-2, •••, 9z,9i, где 9, — подстановка, с помощью которой выводима подцель Si+i из S,-
Вывод цели удобно представлять в виде дерева И/ИЛИ с корнем в целевой вершине. Напомним, что под деревом понимается графовая структура (т. е. структура, которую можно изобразить в виде вершин и связей), любые вершины-потомки которой имеют не более одной вершины-предка. Вершине типа И дерева соответствует конъюнкция условий некоторого правила (т. е. Ai, Аг, ..., Ад), вершине типа ИЛИ соответствует вариант, когда к одному и тому же заключению (резольвенте) приводят различные правила.
В любой системе логического программирования, в том числе и в системе ПРОЛОГ, реализуется некоторая стратегия обхода дерева поиска, т. е. используется та или иная встроенная в систему стратегия поиска решения задачи. В основном эти стратегии имеют последовательный характер. В последнее время начинают появляться реализации стратегий параллельного типа. Они резко повышают эффективность систем логического программирования.
Наиболее распространенной стратегией последовательного типа является стратегия «сначала в глубину». При этом дерево поиска упорядочивается с помощью двух линейных порядков: «слева направо» для литералов цели типа (3) и «сверху вниз» для правил типа (1), (2). Тогда на каждом шаге поиска выделенным оказывается первый слева литерал цели и к нему применяется первое сверху правило. При этом запоминаются всевозможные разветвления. Если поиск заходит в тупик, то происходит возврат к месту последнего разветвления с помощью механизма backtracking. Одновременно отменяются результаты всех подстановок, сделанных после этого разветвления. Возврат осуществляется также и при успешном исходе для получения других ответов. Работа заканчивается, когда список разветвлений пуст. Основное достоинство этой стратегии — простота ее реализации, недостаток — большой перебор для некоторых классов подцелей. Кроме того, если дерево поиска содержит бесконечную ветвь, то попав в нее, система не выйдет оттуда и правильные ответы, находящиеся правее этой цели на дереве, не будут получены.
При стратегии «сначала в ширину» дерево поиска обходится ярус за ярусом сверху вниз. Она гарантирует нахождение решения, если оно существует. Однако стратегия требует значительно большего объема памяти и поэтому получила сравнительно небольшое распространение.
Одно из достоинств языков логического программирования состоит в том, что на их основе достаточно удобно I реализовать стратегии параллельного типа, причем порядок обхода дерева не столь важен; существен лишь тот факт, что должно быть обойдено все дерево. Именно последнее обстоятельство и дает принципиальную возможность вести поиск параллельно. Обычно различают два типа параллелизма: ИЛИ — параллелизм, означающий одновременное применение для выделенной подцели из цели всех правил из базы знаний, и И-параллелизм, означающий параллельную обработку одновременно всех литералов (подцелей) целевого утверждения. Кроме того, параллелизм возможен и необходим при унификации (так как эта операция применяется часто). Наибольшие перспективы имеют именно параллельные стратегии, но для их эффективной реализации необходимы соответствующие процессоры, использующие принципы параллельной архитектуры.
Концептуальное программирование
К дедуктивным подходам решения задач относится и концептуальное программирование [7\. Этот метод ориентирован в основном на решение так называемых вычислительных задач, т. е. задач, которые могут быть сформулированы в следующем виде.
При заданном описании условий задачи М по значениям переменных xi, хг, ..., Хт, удовлетворяющих М, вычислить значения переменных у1,у2, ••-,Уп, также удовлетворяющих М.
Основу концептуального программирования составляет метод структурного синтеза программ, использующий две эквивалентные формы представления знаний о задачах:
— формульное представление;
— графовое представление.
При формульном представлении основными этапами формирования программы решения искомой задачи являются:
1 — формализация описания условий решаемой
задачи;
2 — построение конструктивного доказательства существования решения задачи в некоторой формальной дедуктивной системе;
3 — извлечение программы из полученного доказательства.
Первый этап, выполняемый пользователем системы, состоит в представлении описаний условий задачи в виде так называемых предложений вычислимости, выполняющих роль аксиом и теорем специальной дедуктивной системы.
В методе структурного синтеза программ используются только предложения вычислимости (аксиомы) следующих трех видов:
(1) простейшие предложения вычислимости
![]()
где a, b — конечные множества переменных или отдельные переменные; f — функция вычислимости, по которой, зная переменные а, можно вычислить переменные b;
(2) предложения вычислимости с условием
![]()
где Р — формула, выражающая условия, при выполнении которых возможно вычисление b из а.
Содержательно это означает, что из а можно вычислить b путем применения функции f, если Р истинно;
(3) предложения вычислимости с подзадачей
![]()
![]() -
квантор существования; и
-^>у -
подзадача; h
- функциональная
переменная.
-
квантор существования; и
-^>у -
подзадача; h
- функциональная
переменная.
Фактически это предложения вычислимости, когда условие вычислимости является задачей в той же дедуктивной системе.
Итак, в методе структурного синтеза программ условия каждой конкретной задачи задаются в виде специальной дедуктивной системы, в которой должна доказываться вычислимость только данной задачи. Это обстоя-| тельство наряду с тем, что в рассматриваемых специаль-1 ных теориях используются только приведенные выше ак-1 сиомы, по существу, одной ограниченной формы
![]()
где Г — условия применимости, приводит к существенному ограничению перебора при построении доказательства существования искомой задачи.
Второй этап, состоящий в доказательстве существования решения задачи, сводится к доказательству существования некоторой функции f, для которой справедливо выражение и —>- и, или в формальном виде
![]()
Для доказательства этого утверждения в данном методе вводятся следующие правила вывода:

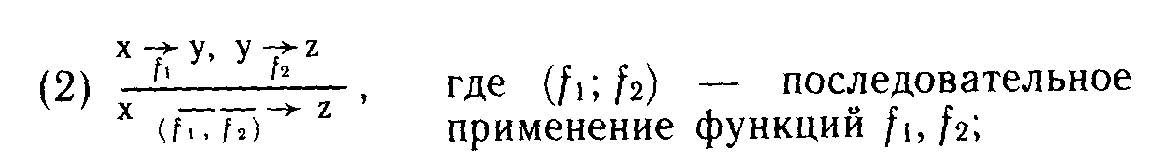
![]()
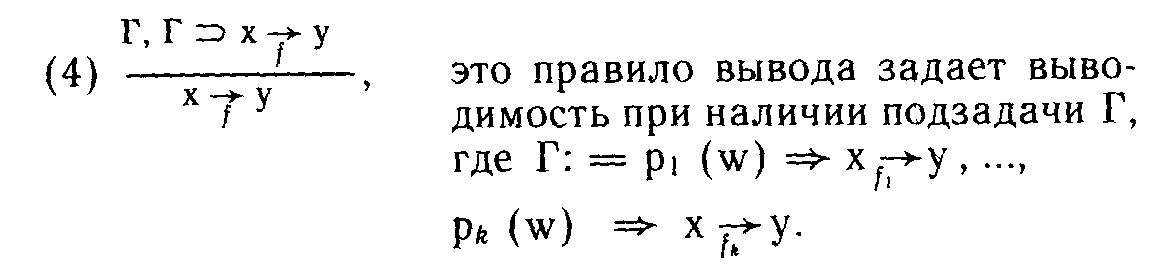
В приведенных правилах в соответствии с логическими соглашениями над чертой помещаются посылки, под чертой — логическое заключение.
Третий этап — извлечение программы из доказательства — при структурном синтезе оказывается достаточно простым, так как каждому правилу вывода ставится в соответствие некоторый оператор(ы) программы. А именно: первому правилу ставится в соответствие оператор у: = select(х), второму — операторы у: == fi(x); z: == f<t(y),' третьему — операторы у: == fi (х), г: == = му)' четвертому — оператор цикла ^pi (w)theny: = = fi(x)'eliL..eliipt(w)theny:== fk (x)elseiailureii.
Построенная в результате доказательства теоремы Я f(u->-v) функция f, связывающая и и v, вследствие существующих соответствий между правилами вывода и операторами программы представляет собой программу решения искомой задачи.
При графовом представлении задача представляется в виде частного класса семантических сетей — вычислительной сети. Под семантической сетью обычно понимается [8] сеть, вершинам которой сопоставляются понятия (объекты, свойства, процессы), а дугам — отношения, существующие между понятиями. При различных ограничениях на описание вершин и связей получаются сети различного вида — сценарии, фреймы, вычислительные сети, семантические сети общего вида.
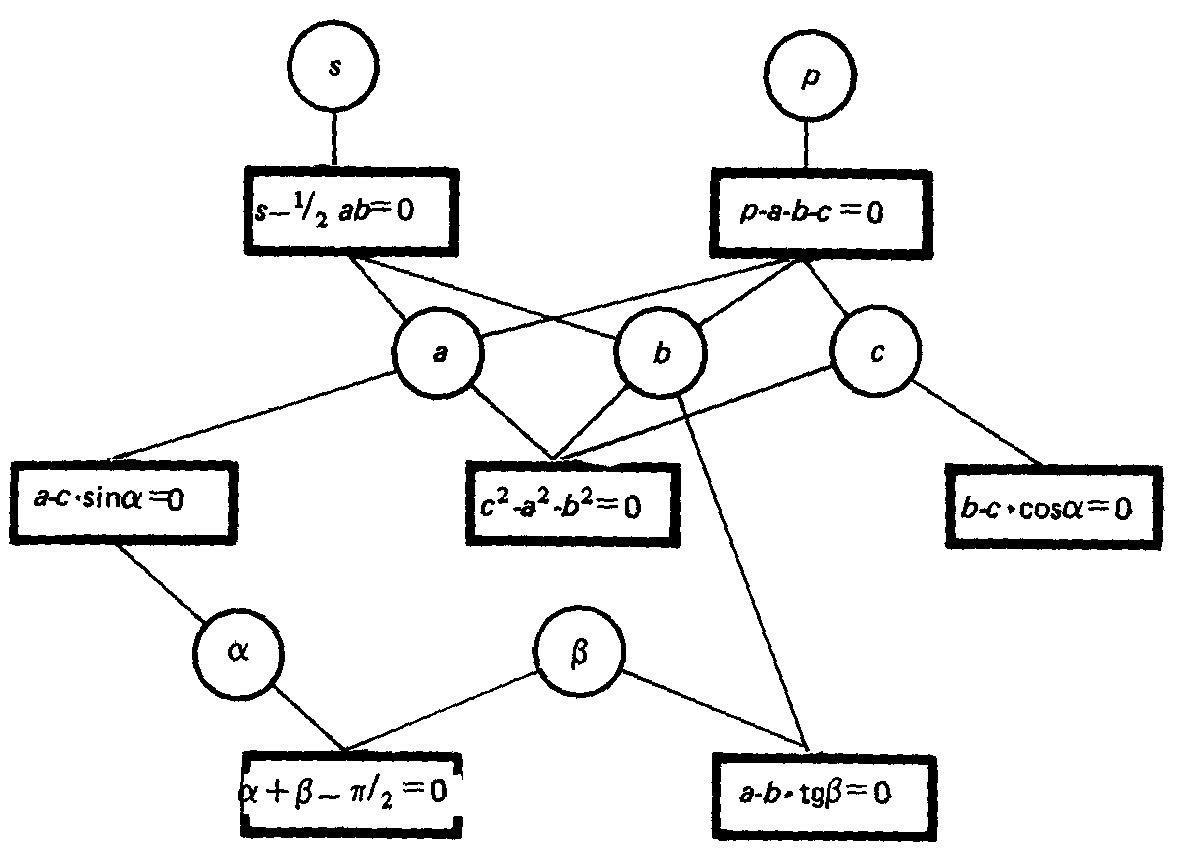
Рис. 3.1. Фрагмент вычислительной модели для прямоугольного треугольника:
р — периметр, S — площадь, а и Ь — катеты прямоугольного треугольника, а и р — углы между соответствующими катетами и гипотенузой
Вычислительные (функциональные) сети, используемые в концептуальном программировании, имеют вид двудольного графа, в котором существуют вершины двух видов: соответствующие функциям и соответствующие аргументам и значениям этих функций. Причем значения одних функций могут выступать как аргументы других функций и, наоборот, аргументы одной функции могут выступать как значения других функций. Тогда вывод на этой сети можно трактовать как нахождение такой ориентации дуг в вычислительной модели, которая определит путь, ведущий из исходных вершин в целевую.
Приведем пример простой вычислительной модели (рис. 3.1) из области решения задач планиметрии. На рис. 3.1 вершины-прямоугольники соответствуют математическим функциям из области планиметрии, а вершины-круги соответствуют именам параметров, которые \ входят в эти функции. Поиск пути в вычислительной ) модели происходит в соответствии со стратегией прямой i (от данных к цели) или обратной (от цели к данным) | волны.
Для представления вычислительных моделей в кон- | цептуальном программировании разработан специальный \ язык программирования УТОПИСТ, в состав которого кроме процедурных операторов (типа операторов присвоения, цикла, условных операторов) введен также оператор задачи, реализующий непроцедурные формы решения некоторых классов задач.
Оператор задачи имеет следующий вид:
на 'Z вычислить 'yi,...,y„, по 'х,Х2,...,х», (3,6) где Z — вычислительная модель; yi, у2, ..., Ут — выходные переменные задачи; xi, X2, ..., х<г — входные переменные задачи.
Чтобы решаемая задача могла быть представлена в виде оператора, должна быть построена соответствующая вычислительная модель, связывающая входные переменные с выходными. В более сложных задачах, где по тем или иным причинам отсутствует соответствующая вычислительная модель, решение осуществляется программированием на языке УТОПИСТ алгоритма решения с помощью операторов процедурного типа.
В состав языка УТОПИСТ входят следующие основные компоненты: объекты, отношения, операторы, директивы. Язык УТОПИСТ позволяет задавать условия задачи в виде совокупности описаний, каждое из которых задает абстрактный объект, представленный в ЭВМ вычислительной моделью. Примерами описаний объектов являются:

![]()
Основными типа отношений являются:
— программные (задаваемые с помощью заранее отлаженных модулей, хранящихся в библиотеке модулей);
— типа уравнений (задают отношения между вещественными числами);
— типа присваивания;
— условные. Примерами условных отношений могут служить следующие выражения языка УТОПИСТ:
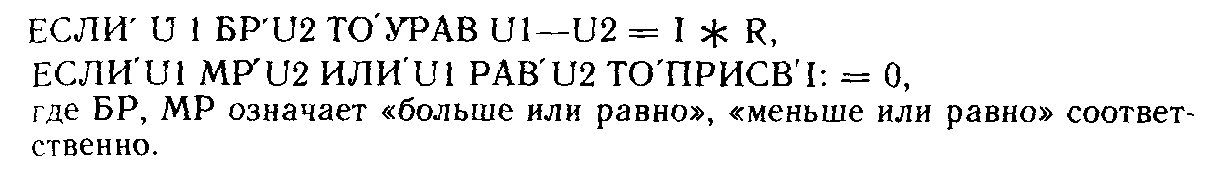
В качестве операторов в языке УТОПИСТ используются оператор задачи для решения некоторых классов задач без задания алгоритма решения и набор операторов, совпадающих по функциям с операторами алгоритмических языков программирования типа ПЛ/1, ФОРТРАН: операторы присваивания, цикла, вызова, условные операторы и т. д.
Директивы — это операторы, предназначенные для модификации вычислительных моделей. К ним относятся директивы: ВВЕСТИ, УДАЛИТЬ и ПО. Например,
ВВЕСТИ, 'РЕЗИСТОР В 'ЦЕПИ; УДАЛИТЬ 'ЦЕПИ;
Программа на языке УТОПИСТ состоит из фрагментов, которыми служат описания данных и действия. Описание данных начинается словом пугтк за которым следуют описания, представляющие условия задачи. Действия начинаются словом действия, за которым следуют операторы и управляющие предложения. Описания данных и действия в программе могут чередоваться. Начало и конец программы обозначены заголовком Программа (идентификатор ) и словом КОНЕЦ.
Покажем фрагмент программы на языке УТОПИСТ:

Концептуальное программирование и реализованная с 1 помощью этого подхода система ПРИЗ ЕС ориентированы в основном на прикладного программиста. Более того, технология использования ПРИЗ ЕС требует наличия в составе пользователей системного программиста, так как пользователь не освобождается от знания ОС ЕС. В частности, он должен быть знаком с языком управления заданий ОС ЕС.
Следует отметить также, что даже в том случае, если решаемая задача может быть представлена в виде оператора задачи, пользователь должен знать идентификаторы всех понятий, используемых в данной вычислительной модели, т. е. знать имена всех входных и выходных переменных модулей, используемых в данном пакете программ, так как они явным образом появляются в описании данных. Эти идентификаторы уникальны. При большом объеме используемых вычислительных моделей такое детализированное знание может стать источником ошибок.
В последующих работах авторов концептуального программирования предприняты попытки преодоления отмеченных недостатков с помощью организации режима диалоговой отладки вычислительных моделей.
3.3 ДСМ-метод*
Кроме дедуктивных схем рассуждений человек при решении задач часто использует индуктивные или в более общем случае правдоподобные схемы рассуждений, которые позволяют ему, в частности, порождать индуктивные обобщения из имеющихся частных утверждений. Напомним, что под правдоподобными выводами понимаются обычно выводы из истинных посылок, заключения которых не обязательно являются истинными высказываниями, в отличие от дедуктивных выводов, где из истинных посылок получаются только истинные значения. Правдоподобные выводы разделяются на индуктивные (от частного к общему) и традуктивные (от частного к частному).
Правдоподобные схемы рассуждения реализуются пока только в экспериментальных вариантах решателей. Обычно различают два подхода к развитию механизмов правдоподобного вывода: вероятностный и детерминистский.
Среди вероятностных подходов следует отметить работу П. Гаека, Т. Гавранека [9], разработавших GU НА-метод автоматического порождения гипотез, сочетающий правила правдоподобных выводов с аппаратом математической статистики, а также исследования Р. Карнапа и Я. Хинтикки по вероятностной логике [10], в которой логическое следование трактуется как понятие индуктивной вероятности.
Среди детерминистских подходов к разработке правдоподобной схемы рассуждения следует прежде всего, отметить работы В. К. Финна и его коллег по созданию ДСМ-метода [11, 12].
• ДСМ-метод формализует и существенно развивает схемы индуктивных рассуждений, предложенные Д. С. Миллем: методы сходства, различия, остатков и сопутствующих изменений.
Постановка задачи в ДСМ-методе такова [12]. Пусть имеется открытое множество экспериментальных фактов (элементарных высказываний) и множество аксиом данной предметной области. Первое множество условно называется базой данных с неполной информацией (БДНИ), а второе — базой знаний (БЗ). Точнее, под БДНИ понимается база данных, где существуют высказывания, которым невозможно приписать логическое значение «истина» или «ложь». Для таких высказываний вводятся истинностные значения «эмпирическая противоречивость» и «неопределенность». Предполагается, что в простых случаях неполноту базы данных можно устранить с помощью высказываний, имеющихся в БЗ. Однако в более общем случае необходимо расширение (пополнение) БЗ путем обработки имеющихся экспериментальных фактов. Данная задача решается с помощью специально разработанных правил правдоподобного вывода, которые формулируются так, что для каждого вывода одновременно строится неколичественная оценка его качества — степень правдоподобия. В качестве БДНИ используется один из вариантов реляционной модели БД (см. гл. 2), в которой отношения определены лишь частично.
Схему функционирования решателя можно представлять следующим образом. Первоначально с помощью правил правдоподобного вывода достраивается БДНИ. Далее построенная БДНИ корректируется путем проверки на непротиворечивость с заданными фрагментами БЗь При этом предполагается, что в составе бз] содержатся как аксиомы, определяющие структуры данных (БЗю), так и аксиомы, описывающие декларативные знания о данной предметной области (B3in). И наконец, путем дополнения индуктивными обобщениями об эмпирических зависимостях и закономерностях достраивается часть базы знаний — БЗгд.
Приведенная схема описывает один шаг работы ДСМ-решателя. Полученное на данном шаге расширение БДНИ, а также пополнение базы знаний используется на последующих шагах правдоподобного вывода наряду с первоначально заданными экспериментальными фактами и знаниями.
Чтобы выводы в ДСМ-методе имели детерминистский характер, на данные наложены определенные ограничения. Эти ограничения приводят к тому, что основным при построении правдоподобного вывода является нахождение существенного в структуре объектов, т. е. причин явлений, а не частотность возникновения тех или иных свойств используемого явления. К этим ограничениям относятся:
1) данные должны быть нечисловыми и хорошо структурированными, т. е. исходные объекты должны обладать некоторой структурой;
2) информация о данных должна быть неполной, т. е. не полно множество аксиом, характеризующих предметную область;
3) база фактов должна иметь скрытые экспериментальные зависимости, характеризующиеся так называемой квазисимметрией, как положительной, так и отрицательной. Это означает, что в массиве фактов существуют эмпирические корреляции событий, причем существуют как причины наличия корреляций (положительные причины), так и причины отсутствия корреляций (отрицательные причины).
Перечисленным ограничениям удовлетворяет ряд задач таких естественных наук, как биология, медицина, фармакология, биохимия, геология, а также некоторый класс задач технической диагностики и управления.
В ДСМ-методе были разработаны:
1) язык, представляющий собой расширение языка исчисления предикатов первого порядка;
2) множество правил правдоподбного вывода (ППВ), на которых задана некоторая организация;
3) способы управления применениями правил правдоподобного вывода — стратегии.
1. Расширение языка исчисления предикатов первого порядка состоит:
— во введении многозначности вследствие неполноты исходной информации, а именно: кроме значений 1 — «истина», — 1 — «ложь» вводятся еще истинностные значения 0 — «эмпирическая противоречивость» и т — «неопределенность»;
— во введении формул с кванторами по кортежам переменной длины. Под кванторами понимаются кванторы существования и всеобщности.
Состояние базы данных с неполной информацией задается матрицами Mf"' и М^"> частично определенных отношений =?-i^: и =>2^, которым соответствуют предикаты =>-i и =>2, имеющие интерпретации «обладать множеством свойств» и «быть причиной наличия (или отсутствия) множеств свойств» соответственно. Тогда выражение Х0' =>i Y*^ читается как «объект X0' обладает множеством свойств Y*2'», а выражение X(1)=?-2Y(2) — как «объект Хс> есть причина наличия (отсутствия) множеств свойств Y^».
Для матрицы Mf"* общим членом является Vi, = = <v,„n>,v,, 6 (1, th—1} и v,, = (т, п). Для матрицы Ма общим членом является pi, = <|а.,,п>, \h, С {1,0,—!} или (а,, = (т, п), где п — номер шага (число применений правил правдоподобного вывода); 1,0, —1, т — истинностные значения. Величины v,, и p.i, полагаются равными 1, —1, 0, т в соответствии с истинностью, ложностью, эмпирической противоречивостью или неопределенностью атомарных высказываний Ci => A„ h == 1, 2, где С„ А, — имена некоторой строки и столбца матрицы соответственно.
Процесс пополнения базы данных является итеративным и осуществляется через заполнение матриц М,'"', (=1,2. К начальной матрице М^* применяются ППВ I рода, результатом чего является означивание атомарных высказываний С/=^2 А,', для которых оценка p,i, == = (т, 0), т. е. для которых существует оценка «эмпирическая противоречивость». Тем самым получается состояние матрицы М2. Затем к матрице М2 применяются ППВ II рода для доопределения значений Vi, = (т, п) Иными словами, с помощью матрицы Mi*"* и ППВ I рода конструируется матрица М^"4'1', а, в свою очередь, с помощью матрицы Ма"4"1' и ППВ II рода конструируется матрица Mi1"'1'^, т. е. истинностные значения v;, и [а;) порождаются процедурно с помощью специальных ППВ I и II рода.
2. Как отмечалось выше, одним из требований к данным, существующим в ДСМ-методе, является обязательность присутствия в данных в скрытой форме причин как наличия экспериментальных зависимостей, так и их отсутствия. В соответствии с этим множество методов поиска экспериментальных зависимостей делится на два класса М4' и М~. Методы М'1' предназначены для поиска причин наличия свойств Y^ у объектов и поиска объектов Xе0, обладающих свойствами \w. Методы М~ предназначены для поиска объектов, являющихся причиной отсутствия свойств Y00, и для построения объектов | Xе0, не обладающих свойствами Y09.
Правила правдоподобного вывода I рода, доопреде- '; ляющие отношение =>ч, предназначены для поиска и извлечения экспериментальных зависимостей, заложенных в БДНИ. Они представляют собой, по существу, различные модификации отрицательных и положительных методов сходства, родственных методу сходства-различий Д. С. Милля. Правила правдоподобного вывода II рода, доопределяющие отношение =>\, предназначены для переноса обнаруженных экспериментальных зависимостей на случаи недоопределенности и основаны на формализации некоторых форм аналогий.
3. Так как в рассматриваемом методе существует набор различных ППВ, то конкретная процедура установления связи X01 =>h Y^, /i == 1, 2, или ее опровержения зависит от последовательности использования этих ППВ. Каждая такая последовательность образует некоторую стратегию метода. В качестве стратегий, в частности, используются:
1) монотонные и немонотонные стратегии. Под монотонной понимается стратегия, обладающая свойством сохранения истинностных оценок. Если на некотором шаге процедуры пара ^Х0^21^ получает истинностную оценку (е, п) и на последующих шагах она не пересматривается, то стратегия монотонна. В противном случае она немонотонна;
2) прямые и обратные стратегии: от причин к следствию и от следствия к причинам.
Одной из важных задач, стоящей в настоящее время перед разработчиками ДСМ-метода, является апробация метода на представительных классах задач.
Метод программируемых доказательств
Метод основан на представлении процесса поиска решение задачи в терминах пространства поиска, когда решение задачи ищется в виде некоторого пути в пространстве поиска, удовлетворяющего определенным условиям [13]. Поясним понятие пространства поиска через известное понятие исчисления (см. § 3.1). Пусть имеется некоторое множество исходных объектов Q\ и множество правил построения новых объектов из исходных и уже построенных Й2. Тогда под пространством поиска (ПП) понимается множество возможных построений новых объектов, задаваемых множествами q| и Qz. Характерными особенностями ПП являются большая-размерность и относительная равномерность. Последнее означает, что любая точка ПП с одинаковой вероятностью принадлежит решению задачи.
Для эффективного решения задач необходимо редуцировать ПП к некоторому определенному фрагменту, во-первых, содержащему решение и, во-вторых, обладающему небольшой размерностью, сравнимой с размерностью решения.
Описываемый метод предполагает, что пользователь может изменять аксиоматику (множество правил построения) ПП. Кроме того, предполагается, что пользователь может выделять различные фрагменты ПП, которые, по его представлению содержат решение.
Описываемый подход для поиска решения задач не требует априорного понимания решения в целом — достаточно представлять лишь некоторый начальный фрагмент пространства поиска, который заведомо содержит часть решения. По мере накопления знаний уточняется как все ПП, так и фрагмент, содержащий решение.
Правилами построения новых объектов в методе (аксиомами) являются продукции вида:
ЕСЛИ < условно, Т0<действие>. (3.7)
а решение задачи состоит в том, чтобы построить такую структуру из этих продукций, что примененная к начальным условиям, она порождает окончательное решение.
Основная трудность при решении задач и состоит в том, чтобы построить искомую структуру. Задача специалиста, решающего задачи подобного типа, состоит в мысленном проведении экспериментов по синтезу структуры из аксиом (3.7), в процессе которых происходит перестройка аксиом решения, добавление новых элементов, устранение лишних, переформулирование и переоценка промежуточных шагов решения (подцелей). Таким образом, задача специалиста сводится к эффективной редукции глобального перебора к некоторому набору локальных с использованием результатов промежуточных шагов. В описываемом подходе локальный перебор реализуется решателем с помощью некоторых переборных процедур, например вглубь, вширь и т. д. Взаимодействие и чередование переборных процедур задаются стратегиями поиска решения, например резолюционными стратегиями поиска опровержения (см. § 3.1), позволяющими ограничивать перебор ПП и сводить его к анализу некоторого фрагмента. ;
Так как решение каждой задачи сводится к дости- ' жению некоторых ключевых промежуточных подцелей и для каждой из них требуется своя форма перебора, воз- | никает необходимость в процессе одного решения варьи- 1 ровать различные стратегии поиска. При этом априорно ! не всегда ясно, какую стратегию использовать для достижения той или иной промежуточной цели. Таким обра- J зом, естественно требовать, чтобы последовательность используемых стратегий задавалась в качестве входного параметра как некая последовательность команд специального языка управления решением - (ЯУР), имеющего следующие основные особенности:
— наличие средств для реализации различных способов перебора;
— возможность описания разнообразных стратегий поиска решения;
— возможность обеспечения прерывания в процессе поиска для анализа полученного решения.
Решение задач должно получаться в результате активного диалога пользователя с ЭВМ, поэтому в составе решателя, реализующего метод, необходимо наличие средств отображения и анализа промежуточного и окончательного решений. При этом отображение решения должно происходить в тех же или близких терминах, .& которых формулировалась задача, а анализ позволял бы делать выводы об интересующих пользователя свойствах этого решения. Кроме того, уместно требовать, чтобы всю возможную пояснительную работу ЭВМ брала на себя. Например, если происходит поиск доказательства в некоторой теории, то полученное частичное доказательство в виде набора строк на формальном языке малоинформативно для пользователя, если не снабдить его пояснением того, из каких посылок получено каждое утверждение, и не привести естественно-языковую интерпретацию каждой формальной конструкции.
Рассмотрим кратко метод поиска решения, предлагаемый в описываемой концепции. Согласно принятой концепции, поиск решения интерпретируется как построение вывода в некотором прикладном исчислении предикатов (ПИП) (см. § 3.1). К особенностям ПИП следует отнести различные формы задания функций и предикатов — процедурные и декларативные — и несколько более развитый аппарат работы с объектами.
Процесс доказательства осуществляется с использованием фиксированных правил вывода под управлением программы на ЯУР, которая выполняется в режиме интерпретации. В качестве основных приемов, используемых при поиске доказательства, можно выделить унификацию и вычисление значений вычисляемых функций и предикатов.
На вход логического решателя, реализующего описываемый метод, поступает информация, состоящая из начальных условий, аксиоматики и набора стратегий поиска. Под начальными условиями понимается информация, описывающая исходную ситуацию задачи. Аксиоматика описывает пространство поиска и задается выражениями типа (3.7) и правилами, аналогичными правилам контекстно-свободных грамматик:
![]()
где а, Р — слова в определенном алфавите.
В процессе реализации той или иной стратегии поиска с помощью фиксированных правил строится некоторый вывод из начальных условий с использованием аксиоматики. Все его промежуточные шаги представляют собой фрагмент пространства поиска, который формируется в соответствии со входом. Вывод заносится в динамическую базу данных (ДБД), представляющих собой БД реляционного типа. Состояние ДБД является адекватным отображением наброска решения или полного решения, полученного к определенному моменту.
Пространство поиска или ДБД, которая в каждый момент содержит некоторый фрагмент пространства поиска, реализуется многоместными таблицами. Суть перебора в ПП заключается в проверке условий в продукциях (3.7) и в случае их выполнения — реализации соответствующих действий или в замене одного или нескольких подслов другими словами в случае использования правил (3.8).
Для использования метода программируемых доказательств разработаны два языка: язык LANGIN для представления аксиоматики, начальных условий и правил вывода и язык управления решением (ЯУР) для представления и управления стратегиями поиска решения.
Язык LANGIN — язык отношений, функций, индивидных констант и переменных. Основой его является язык расширенного исчисления предикатов первого порядка (РИП). Синтаксис языка LANGIN включает в себя следующие средства описания: объектов (т. е. индивидных констант), переменных (индивидных), функций, предикатов.
Кратко опишем синтаксис и семантику правильных конструкций языка LANGIN.
Под объектами понимаются индивидные константы, однозначно определяемые сортом и именем. Имя — это произвольная последовательность символов. Под сортом понимается имя класса объектов. Индивидные переменные используются для обозначения аргументов в предикатах, функциях и других правильных конструкциях языка.
Объекты имеют формат
(С «имя сорта)/(имя объекта»), а переменные — формат
«имя сорта >/< имя переменной».
Например, константу «сопротивление R1»' можно представить в виде (C(RES/R1)), а переменную для обозначения сопротивлений—в виде (RES/X).
Функции делятся на вычисляемые и символические. Вычисляемые функции обладают свойством получать новые значения по значениям аргументов. Поэтому каждая вычисляемая функция определяет имя некоторой процедуры, которая по значениям ее аргументов вычисляет новое значение, являющееся значением функции.
Назначение символических функций состоит в том, чтобы единообразно представлять сложные объекты (деревья, стеки и т. д.), возникающие в процессе поиска решения, т. е. так или иначе отображать пространство поиска.
Функции имеют формат
(Р«имя функции» <арг. 1><арг. 2>...<арг. п».
Предикаты соответственно функциям также делятся на вычисляемые и символические. По реализации вычисляемые предикаты не отличаются от вычисляемых функций. Каждому вычисляемому предикату соответствует единственная процедура. Символические предикаты используются не для представления объектов пространства поиска, а для фиксирования отношений между ними. Они задаются многоместными таблицами. Все таблицы, реализующие символические предикаты, включаются в ДБД. Символические предикаты не определяются полностью, и процесс поиска решения состоит в таком их доопределении, при котором можно установить интересующие пользователя свойства пространства поиска.
Формат предикатов:
(Р«имя предиката» <apr. iy<apr. 2)...<арг. п».
Логические формулы строятся из конструкций, разрешенных в языке РИП с использованием обычных логических связок и кванторов.
В терминах языка LANGIN каждая аксиома исчисления имеет вид продукции:
F.Fi-^b, (3.9)
где r=PiVP2V--VP", Pi, ?2, ..., Рп — символические предикаты; Fi — произвольная логическая формула, состоящая только из вычисляемых предикатов; Fz — логическая формула, содержащая предикаты обоих типов.
Выражение Г задает условия применимости аксиомы. Процесс вывода сводится к унификации части формулы Г с условиями задачи (или с полученной частью решения) и к вычислению логического значения формулы Fi. Если Fi — «истина», то F2 записывается в ДБД.
Начальные условия задачи задаются символическими предикатами.
Язык управления решениями является основой механизма управления стратегиями поиска решений, который представляет собой метасредство по отношению к формализму выбранного исчисления. Фиксируя исчисление, т. е. аксиомы и правила вывода, на эффективность решения задач можно воздействовать изменяя стратегии поиска и управляя тем самым процессом перебора. В рассматриваемом подходе управление процессом перебора осуществляется пользователем, компонующим из фрагментов целостное решение.
Все операторы языка управления решениями делятся на директивные, переборные и управляющие. Директивные операторы преобразуют содержимое ДБД, т. е. осуществляют ввод новой информации, модифицируют или удаляют уже имеющуюся информацию. Переборные операторы предназначены для порождения фрагментов пространства поиска путем генерации части пространства, содержащей решение искомой задачи. В каждом переборном операторе содержится указание на то, какие аксиомы исчисления им используются для порождения новых точек пространства поиска. С помощью переборных операторов пользователь может менять аксиомы и стратегии, в процессе поиска постепенно «нащупывая» путь решения. Управляющие операторы — это операторы условного, безусловного переходов и операторы модификации условий.