

4.7.3. Вызов процедуры
Для построения таблиц сопряженности необходимо выполнить команды меню: Analyze/ Descriptive Statistics/ Crosstabs...(рис.4-8)
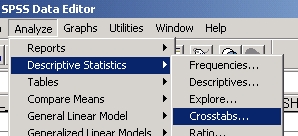
Рис.4-8. Вызов команды кросс-табуляции
На экране появится диалоговое окно Crosstabs, показанное на рисунке 4-9.
4.7.4. Задание параметров
Список слева состоит из всех показателей (столбцов таблицы данных), доступных для анализа. Из этого списка необходимо выбрать показатель, значения которого должны образовать строки таблицы сопряженности, и нажать верхнюю из обведенных на рисунке кнопок со стрелкой вправо. Выбранный показатель будет показан в списке Row(s).
Аналогично должны выбрать показатель, значения которого образуют колонки таблицы, и нажать нижнюю из обведенных кнопок. Название показателя отобразится в списке Column(s).
После этого достаточно нажать кнопку OK, и SPSS рассчитает и покажет таблицу сопряженности по двум показателям. В каждой ячейке таблицы показано число наблюдений (строк таблицы данных), у которых значения исследуемых показателей совпадают со значениями в заголовке строки и столбца таблицы сопряженности.
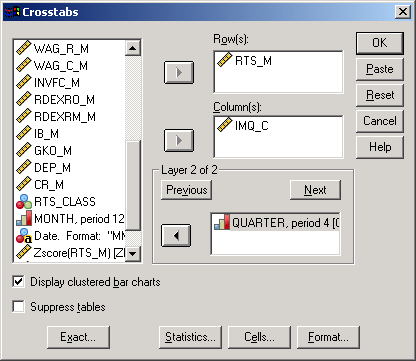
Рис.4-9. Вид окна Crosstabs
4. SPSS позволяет строить таблицы сопряженности по более чем двум показателям сразу. В списки Row(s) и Column(s) можно внести более чем по одному показателю. В результате будет выведено сразу несколько таблиц, отражающих распределение всех указанных показателей. Также можно указать показатель, определяющий уровень таблицы (нажав на самую нижнюю кнопку со стрелкой). Тогда мы получим трехмерную таблицу. Естественно, на двухмерном экране или листе бумаги разные уровни такой таблицы будут просто расположены рядом.
5. Вывод кластерной диаграммы. Если отметить флажок Display clustered bar charts, то вдобавок к таблице сопряженности мы получим график (столбиковую диаграмму), показывающий то же самое распределение в графическом виде.
6. Не выводить таблицы. Вдобавок к собственно таблице сопряженности SPSS может рассчитывать различные критерии для определения меры связи или независимости исследуемых показателей (см. далее). Если нас интересуют только значения этих критериев (статистик), то можно не выводить саму таблицу, отметив флажок Suppress tables.
7. Точные тесты. Иногда данных в выборке (таблице данных) недостаточно, чтобы получить приемлемые значения критериев обычным асимптотическим методом (методом приближения). Нажав кнопку Exact..., можно в открывшемся окне указать один из методов более точного вычисления: Monte Carlo и Exact (рис.4-10).
8. Вычисление критериев (статистик). При нажатии на кнопку Statistics... появляется диалоговое окно, в котором можно выбрать, какие статистики рассчитывать и отображать (рис.4-11).
Chi-sqare (Хи-квадрат). Это тест на независимость показателей в строках и столбцах таблицы.
Correlations (Корреляции). Будут выведены коэффициенты корреляции Пирсона (для обычных переменных) и Спирмена (для данных, объединенных в ранжированные группы).
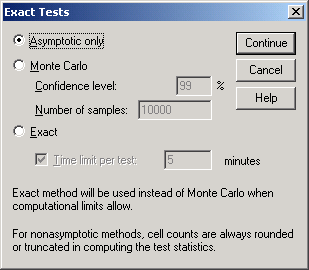
Рис.4-10. Окно методов вычисления
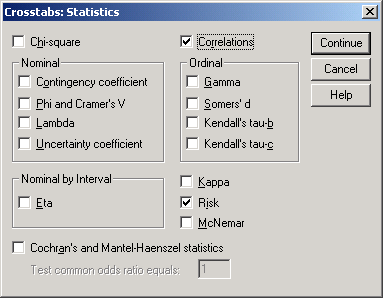
Рис.4-11. Диалоговое окно Crosstabs Statistics...
Nominal (Номинальные). Эта группа включает ненормированные (номинальные) показатели зависимости и связи между переменными. Разные формулы подсчета делают их более адекватными для различных видов данных. Эти критерии не могут быть использованы для сравнения степени связи между разнородными переменными (показателями).
Ordinal (Порядковые). Эта группа объединяет нормированные статистики. Их значения находятся в интервале от -1 до 1, а значит, их можно использовать для сравнения степени связи показателей. Какой именно критерий выбрать также зависит от конкретного вида данных.
Eta (Эта). Критерий для оценки связи показателей, один из которых представлен как набор интервалов чисел, а второй -- как набор категорий (описательных). Его значение находится в интервале от 0 до 1.
Kappa (Каппа). Критерий оценки степени договоренности между двумя оценщиками одного и того же объекта.
Risk (Риск). Мера степени связи между присутствием фактора и наступлением события.
McNemar (Тест МакНемара). Непараметрический тест для двух связанных логических переменных (допускающих одно из двух значений).
9. Значения в ячейках. При нажатии на кнопку Cells... открывается окно, в котором можно указать, что будет выводиться в каждую ячейку таблицы сопряженности (рис.4-12).
Counts (Количество).
Observed (Наблюдаемое) - реальное количество наблюдений с данными значениями показателей (переменных).
Expected (Ожидаемое) - количество, которое было бы при абсолютной независимости переменных.
Percentages (Проценты).
По строке (Row) -- процент наблюдений в ячейке от всех наблюдений в строке.
По столбцу (Column) -- от всех наблюдений в столбце.
Общий (Total) -- от общего количества наблюдений в таблице.
Residuals (Остатки).
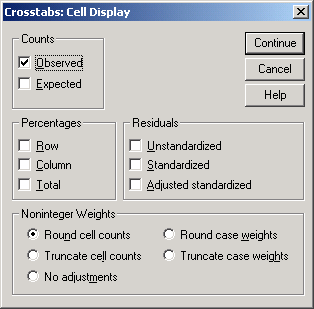
Рис.4-12. Диалоговое окно Crosstabs Cell display
Unstandardized (Нестандартизованные) -- разность реального и ожидаемого количества наблюдений. При анализе большой выборки это будет значением нормально распределенной случайной величины.
Standardized (Стандартизованные) -- значение остатка, разделенное на оценку его стандартной ошибки. Таким образом, получается значение стандартной нормальной случайной величины.
Adj. standardized (Выравненные стандартизованные) – отклонение стандартизованного остатка от среднего значения, выраженное в единицах стандартного отклонения.
10. При нажатии на кнопку Format (Формат) открывается соответствующее окно. В этом окне можно задать формат следования значений в столбцах и строках таблицы сопряженности: Ascending (Возрастающий) или Descending (Убывающий).