

Алгоритм арифметического кодирования информации, пример.
Арифметическое кодирование — один из алгоритмов энтропийного сжатия. Обеспечивает почти оптимальную степень сжатия с точки зрения энтропийной оценки кодирования Шеннона.
Принцип действия
Пусть имеется некий алфавит, а также данные о частотности использования символов. Тогда рассмотрим на координатной прямой отрезок от 0 до 1. Назовём этот отрезок рабочим. Расположим на нём точки таким образом, что длины образованных отрезков будут равны частоте использования символа, и каждый такой отрезок будет соответствовать одному символу. Теперь возьмём символ из потока и найдём для него отрезок среди только что сформированных, теперь отрезок для этого символа стал рабочим. Разобьём его таким же образом, как разбили отрезок от 0 до 1. Выполним эту операцию для некоторого числа последовательных символов. Затем выберем любое число из рабочего отрезка. Биты этого числа вместе с длиной его битовой записи и есть результат арифметического кодирования использованных символов потока.
Пример. Закодируем сообщение «ЭТОТ_МЕТОД_ЛУЧШЕ_ХАФФМАНА» с помощью описанного метода.
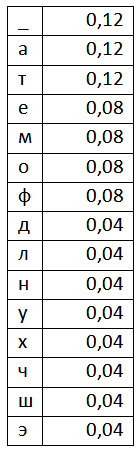
Составив таблицу частоты появления символов, мы можем приступать к кодированию. На первом этапе составим рабочий отрезок. Выглядеть он будет так:
![]()
Берём первый символ из потока, это символ «Э». Соответствующий ему отрезок – отрезок [0,96;1). Если бы мы хотели закодировать один символ, то результатом кодирования было бы любое число из этого отрезка. Но мы не остановимся на одном символе, а добавим ещё один. Символ «Т». Для этого составим новый рабочий отрезок с a=0,96 и b=1. Разбиваем этот отрезок точками точно так же как мы сделали это для исходного отрезка и считываем новый символ «Т». Символу «Т» соответствует диапазон [0,24;0,36), но наш рабочий отрезок уже сократился до отрезка [0,96;1). Т.е. границы нам необходимо пересчитать. Сделать это можно с помощью двух следующих формул: High=Lowold+(Highold-Lowold)*RangeHigh(x), Low=Lowold+(Highold-Lowold)*RangeLow(x), где Lowold – нижняя граница интервала, Highold – верхняя граница интервала RangeHigh и RangeLow – верхняя и нижняя границы кодируемого символа.
Пользуясь этими формулами, закодируем первое слово сообщения целиком:

Алгоритм арифметического декодирования информации, пример.
Пусть имеется сообщение РАДИОВИЗИР. Причем встречаемость каждого символа и соответствующие интервалы распределилась следующим образом.
-
Симв
Вер-ть
Инт-ал
А
0,1
0 – 0,1
Д
0,1
0,1 – 0,2
В
0,1
0,1 – 0,3
И
0,3
0,3 – 0,6
З
0,1
0,6 – 0,7
О
0,1
0,7 – 0,8
Р
0,2
0,8 – 1
Результат кодирования: интервал [0,8030349772 – 0,8030349880]. Именно этот интервал декодер получает как информацию о закодированном сообщении + знание вышеуказанной таблицы. Декодер первый символ определяет как Р, так как результат кодирования целиком лежит в интервале [0.8 - 1), выделенном моделью символу Р согласно таблице. Исключим из результата влияние известного символа Р, для этого вычтем из результата кодирования нижнюю границу диапазона, отведенного для Р, – 0,8030349772 – 0.8 = 0,0030349772 – и разделим полученный результат на ширину интервала, отведенного для Р, – 0.2. В результате получим 0,0030349772 / 0,2 = =0,015174886. Это число целиком вмещается в интервал, отведенный для буквы А, – [0 – 0,1) , следовательно, вторым символом декодированной последовательности будет А.
Поскольку теперь мы знаем уже две декодированные буквы - РА, исключим из
итогового интервала влияние буквы А. Для этого вычтем из остатка 0,015174886
нижнюю границу для буквы А 0,015174886 – 0.0 = 0,015174886 и разделим
результат на ширину интервала, отведенного для буквы А, то есть на 0,1. В
результате получим 0,015174886/0,1=0,15174886. Результат лежит в диапазоне,
отведенном для Д, следовательно, очередная буква будет Д. И так далее, пока не декодируем все символы.
Проблемы
Первая: декодеру нужно обязательно знать об окончании декодирования, поскольку остаток 0,0 может означать букву или последовательность. Решить эту проблему можно двумя способами: 1) кроме кода сохранять число = размер кодируемого массива. Процесс закончен, когда массив на выходе декодера станет такого размера. 2) – включить в модель источника символ конца блока
Вторая проблема: окончательный результат кодирования (интервал) станет известен только по окончании процесса кодирования. Нельзя начать передачу закодированного сообщения, пока не получена последняя буква и не определен окончательный интервал?
По мере того, как интервал (результат кодирования) сужается, старшие десятичные знаки перестают изменяться, следовательно, эти разряды (или биты) уже могут передаваться. Таким образом, передача закодированной последовательности осуществляется, хотя и с некоторой задержкой, но последняя незначительна и не зависит от размера кодируемого сообщения. И третья проблема – это вопрос точности представления (число десятичных разрядов, требуемое для его представления). Проблема решается использованием арифметики с конечной разрядностью и отслеживанием переполнения разрядности регистров. Применение сжатия контекстных последовательностей данных в последних стандартах сжатия видеоизображений JPEG2000, H.264 (MPEG-4 p.10, AVC) и тд.