

Еквівалентні, тому що їх обидві породжує мова:
L(G1) = L(G2) = {0n1n |n>0}.
Граматики G1 і G2 майже еквівалентні, якщо L(G1) {}=L(G2) {}.
Іншими словами, граматики майже еквівалентні, якщо мови, ними породжувані, відрізняються не більше ніж на {}.
Наприклад:
G1=({0,1}},{A, S}, P1, S) i G2=({0,1},{S}, P2, S),
де
P1: 0A1 P2:S 0S1|
0A 00A1
A
Майже еквівалентні, тому що:
L(G1)={0n1n
|n>0},
а L(G2)={0n1n
|n![]() 0},
0},
тобто L(G2) складається з усіх ланцюжків мови L(G1) і порожнього ланцюжка, що у L(G1) не входить.
Якщо мова, породжена граматикою G, не містить жодного скінченого ланцюжка то вона називається порожньою.
Для того, щоб мова L(G) не була порожньою, у множині Р має бути хоча б одне правило вигляду:
![]()
де
![]()
і має існувати висновок:
![]() .
.
Порожня мова. Типи формальних мов і граматик. Граматики типу 0. Граматики типу 1. Граматики типу 2. Граматики типу 3. Висновок у кс-граматиках і правила побудови дерева висновку
Класифікація мов за Хомським
Тип 0
Граматика G= (VT, VN, P, S) називається граматикою типу 0, якщо на правила висновку не накладається жодних обмежень (крім тих, які зазначені у визначенні граматики).
Будь-яке
правило
![]() може бути побудованим з використанням
довільних ланцюжків
може бути побудованим з використанням
довільних ланцюжків
![]() .
.
Тип 1
Граматика G= (VT, VN, P, S) називається граматикою, що не укорочує, якщо, кожне правило з множини Р має вигляд ,
де
![]() ,
,
![]() та
та
![]() .
.
Граматика G= (VT, VN, P, S) називається контекстно-залежною (КЗ), якщо кожне правило з множини Р має вигляд ,
де
![]()
![]() .
.
Граматику типу 1 можна визначити як неукорочуючу, так і як контексно-залежну. Вибір визначення не впливає на множину мов, породжуваних граматиками цього класу, оскільки доведено, що множина мов, породжуваних граматиками, що не укорочують, збігається з множиною мов, породжуваних КЗ-граматиками.
Граматика типу 1 значно зручніша на практиці, ніж граматика типу 0, оскільки в лівій частині правила замінюється завжди один нетермінальний символ, котрий можна пов‘язати з певним синтаксичним поняттям, в той час, як у граматиці типу 0 можна замінювати одразу кілька символів, у тому числі і термінальних.
Наприклад:
граматика G4:
VT={a,b,c,d}, VN{<I>, <A>, <B>}
R={<I> aA<I>,
A<I> AA<I>,
AAA A<B>A,
A b,
b<B>A bcdA,
b<I> ba}
є контекстно-залежною, оскільки друге та шосте правила мають непустий лівий контекст, а третє та п‘яте правило містять обидва контексти. Висновок у такій граматиці може мати вигляд:
<I> a<A><I> a<A><A><I> ab<A><I> abb<I> abba.
Тип 2
Граматика
G=(VT,
VN,
P,
S)
називається контекстно-вільною
(КВ),
якщо
кожне правило з множини Р
має вигляд
![]() ,
,
де
![]() ,
.
,
.
Граматика G=(VT, VN, P, S) називається укорочуючою контекстно-вільною (УКВ), якщо кожне правило з множини Р має вигляд ,
де
,
![]() .
.
Граматику типу 2 можна визначити як контекстно-вільну або укорочуючу контекстно-вільну.
Можливість вибору обумовлена тим, що для кожної УКВ-граматики існує майже еквівалентна КВ-граматика.
Тип 3
Граматика G=(VT,
VN, P,
S) називається
праволінійною, якщо кожне правило
з множини Р має вигляд
![]() або
або
![]() ,
,
де А VN, B VN, t VT.
Граматика G=(VT,
VN, P,
S) називається
ліволінійною, якщо кожне правило
з множини Р має вигляд
![]() або
,
або
,
де А VN, B VN, t VT.
Граматику типу 3 (регулярну, Р-граматику) можна визначити як праволінійну або ліволінійну.
Вибір визначення не впливає на множину мов, породжуваних граматиками цього класу, оскільки доведено, що множина мов, породжуваних праволінійними граматиками, збігається з множиною мов, породжуваних ліволінійними граматиками.
Приклади правосторонньої та лівосторонньої граматики:
![]() :
:
VT={a,b}, VN={<I>,<A>}, P={<I> a<I>,
<I> a<A>,
<A> b<A>,
<A> b<Z>,
<Z>
![]() }
}
![]() :
:
VT={a,b}, VN={<I>,<A>}, P={<I> <A>b,
<A> <A>b,
<A> <Z>a,
<Z> <Z>a,
<Z> }.
Співвідношення між типами граматик
Будь-яка регулярна граматика є КВ-граматикою;
Будь-яка регулярна граматика є УКВ-граматикою;
Будь-яка КВ-граматика є КЗ-граматикою;
Будь-яка КВ-граматика є граматикою, що не укорочує;
Будь-яка КЗ-граматика є граматикою типу 0;
Будь-яка граматика, що не укорочує, є граматикою типу 0.
Зауваження: УКВ-граматика, що містить правила виду А , не є КЗ-граматикою і не є граматикою, що не укорочує.
Мова L(G) є мовою типу k , якщо її можна описати граматикою типу k.
Співвідношення між типами мов
Кожна регулярна мова є КВ-мовою, але існують КВ-мови, що не є регулярними (наприклад, L={anbn | n>0}).
Кожна КВ-мова є КЗ-мовою, але існують КЗ-мови, що не є КВ-мовами (наприклад, L={anbncn | n>0});
Кожна КЗ-мова є мовою типу 0.
Зауваження: УКВ-мова, що містить порожній ланцюжок, не є КЗ-мовою.
Зауваження: варто підкреслити, якщо мова задана граматикою типу k, то це не означає, що не існує граматики типу k| (k|>k), що описує ту саму мову. Тому, коли говорять про мову типу k, звичайно мають на увазі максимально можливий номер k.
Наприклад: КЗ-граматика G1=({0,1},{A,S},P1,S) і КВ-граматика G2=({0,1},{S}, P2, S),
де
Р1: S 0A1
0A 00A1
A
P2: S 0S1 | 01
описують ту саму мову L=L(G1)=L(G2)={0n1n | n>0}.
Мову L називають КВ-мовою, тому, що існує КВ-граматика, що її описує. Але вона не є регулярною мовою тому, що не існує регулярної граматики, що описує цю мову.
Приклади граматик і мов
Зауваження: якщо при описі граматики зазначені тільки правила висновку Р, то будемо вважати, що великі латинські букви позначають нетермінальні символи, S – ціль граматики, всі інші символи термінальні.
1. Мова
типу
0:
![]()
G(L):
![]()
![]()
![]()
![]()

2. Мова типу 2: L={ланцюжок з 0 і 1 з однаковим числом 0 і 1}
G(L):
![]()

3. Мова
типу
2:
![]()
G(L):
![]()
![]()
4. Мова
типу
3:
![]() ,
де немає двох
,
де немає двох
![]() ,
що знаходяться поруч}
,
що знаходяться поруч}
G(L):
![]()
![]()
Синтаксичний розбір. Лівий і правий висновок. Неоднозначні та еквівалентні граматики. Способи завдання схем граматик. Рекомендації з побудови граматик. Опис списків. Приклад побудови граматик
Розбір ланцюжків
Ланцюжок належить мові, породженою граматикою, тільки у тому випадку, якщо існує її висновок з мети цієї граматики. Процес побудови такого висновку (а, отже, і визначення належності ланцюжка мові), називається розбором.
З практичної точки зору найбільший інтерес представляє розбір за контекстно-вільними граматиками (КВ чи УКВ). Їхньої породжуючої потужності досить для опису більшої частини синтаксичної структури мов програмування, для різних підкласів КВ-граматик є добре розроблені практично прийнятні способи рішення задачі розбору.
Розглянемо основні визначення, пов‘язані з розбором за КВ-граматикою.
Висновок
ланцюжка
![]() з
у КВ-граматиці G=(VT,
VN,
P,
S),
називається лівим
(лівостороннім), якщо у цьому висновку
кожна чергова сентенціальна форма
виходить з попередньої заміною самого
лівого нетермінала.
з
у КВ-граматиці G=(VT,
VN,
P,
S),
називається лівим
(лівостороннім), якщо у цьому висновку
кожна чергова сентенціальна форма
виходить з попередньої заміною самого
лівого нетермінала.
Визначення
Ланцюжок
![]() ,
для якої
,
для якої
![]() називається сентенціальною формою в
граматиці G=(VT,
VN,
P,
S).
називається сентенціальною формою в
граматиці G=(VT,
VN,
P,
S).
Висновок ланцюжка з у КС-граматиці G=(VT, VN, P, S), називається правим (правобічним), якщо у цьому висновку кожна чергова сентенціальна форма виходить з попередньої заміною самого правого нетермінала.
У граматиці, для одного і того самого ланцюжка може бути кілька висновків, еквівалентних у тому розумінні, що в них у тих самих місцях застосовуються ті самі правила висновку, але в різному порядку.
Наприклад: для ланцюжка a+b+c у граматиці
G=({a,b},{S,T}, {S TT+S; T ab},S) можна побудувати висновки:
1) S T+S T+T+S T+T+T a+T+T a+b+T a+b+a
2) S T+S a+S a+T+S a+b+S a+b+T a+b+a
3) S T+S T+T+S T+T+T T+T+a T+b+a a+b+a
Тут 2 – лівосторонній висновок, 3 – правобічний, а 1 не є ні лівостороннім, ні правобічним, але всі ці висновки є еквівалентними в зазначеному вищі розумінні.
Для КВ-граматик можна ввести зручне графічне представлення висновку, назване деревом висновку, причому для всіх еквівалентних висновків дерева висновки збігаються.
Дерево називається деревом висновку (чи деревом розбору) у КВ-граматиці G=(VT, VN, P, S), якщо виконані наступні умови:
кожна вершина дерева позначена символом з множини
 ,
при цьому корінь дерева позначений
символом S;
гілки – символами з
,
при цьому корінь дерева позначений
символом S;
гілки – символами з
 ;
;якщо вершина дерева позначена символом
 ,
а її безпосередні нащадки – символами
a1,
… an,
де кожне
,
а її безпосередні нащадки – символами
a1,
… an,
де кожне
 ,
то
,
то
 –
правило висновку у цій граматиці;
–
правило висновку у цій граматиці;якщо вершина дерева позначена символом , а її єдиний безпосередній нащадок позначений символом , то
 – правило у цій граматиці.
– правило у цій граматиці.
Приклад дерева висновку для ланцюжка a+b+a у граматиці G показано на рис.3.1.

Рис.3.1. Дерево висновку для ланцюжка a+b+a у граматиці G
КВ-граматика
G
називається неоднозначною,
якщо існує хоча б один ланцюжок
![]() ,
для якого може бути побудовано два чи
більше різних дерева висновку.
,
для якого може бути побудовано два чи
більше різних дерева висновку.
Це
твердження еквівалентне тому, що ланцюжок
![]() має два чи більше різних лівосторонніх
чи правобічних висновків.
має два чи більше різних лівосторонніх
чи правобічних висновків.
У протилежному випадку граматика називається однозначною.
Мова, породжена граматикою, називається неоднозначною, якщо вона не може бути породжена ніякою однозначною граматикою.
Приклад неоднозначної граматики:
G=({if, then, else, a, b}, {S}, P,S), де P={S if b then S else Sif b then Sa}.
У цій граматиці для ланцюжка if b then if b then a else a можна побудувати два дерева висновку. Однак це не означає, що мова L(G) обов‘язково неоднозначна.
Визначена нами неоднозначність – це властивість граматики, а не мови, тобто для деяких неоднозначних граматик існують еквівалентні їм однозначні граматики. Якщо граматика використовується для визначення мови програмування, то вона повинна бути однозначною. У наведеному вище прикладі різні дерева висновку припускають відповідність else різним then, і якщо підправити граматику G, то неоднозначність буде усунута:
S if b then Sif b then S| else Sa
S| b then S| else S| | a
Проблема, чи породжує дана КС-граматика однозначну мову (тобто чи існує еквівалентна їй однозначна граматика), є алгоритмічно нерозв‘язуваною.
Однак можна вказати деякі види правил висновку, що приводять до неоднозначності.
A AA |
A A A

A A A

A A A A
Приклад неоднозначної КС мови:
L = {a ibj ck | i=j чи j=k}.
Інтуїтивно це пояснюється тим, що ланцюжки з i=j повинні породжуватись групою правил висновку, відмінних від правил, що породжують ланцюжки з j=k. Але тоді, певні з ланцюжків з i=j=k будуть породжуватись обома групами правил, та відповідно будуть мати по два різних дерева висновку.
Одна з граматик, що породжує L така:
S AB DC
A aA
B bBc
C cC
D aDb
Очевидно, що вона неоднозначна.
Дерево виведення можна будувати знизу вверх, чи з гори вниз.
При формуванні дерева згори вниз, дерево формується від кореня до гілок. На кожному крокові для вершини, позначеної нетермінальним символом, намагаються знайти таке правило висновку, щоб наявні в ньому термінальні символи «проектувались на символи» вихідного ланцюжка.
Метод «знизу до гори» полягає у тому, що вихідний ланцюжок намагаються «згорнути» до початкового символу S; на кожному крокові шукають ланцюжок який співпадає з правою частиною будь-якого правила висновку; якщо такий підланцюжок знаходиться, то вона замінюється нетерміналом з лівої частини правила.
Якщо граматика однозначна, то при будь-якому способі побудови, буде отримане одне й те саме дерево.
Перетворення граматик
В певних випадках КВ-граматика може містити недосяжні та марні символи, котрі не беруть участь у породженні ланцюжків мови і тому можуть бути видаленими з граматики.
Визначення
Символ
![]() називається недосяжним
в граматиці G=(VT,
VN,
P,
S),
якщо він не з‘являється в жодній
сентенціальній формі цієї граматики.
називається недосяжним
в граматиці G=(VT,
VN,
P,
S),
якщо він не з‘являється в жодній
сентенціальній формі цієї граматики.
Алгоритм видалення недосяжного символу
Вхід: КС – граматика G=(VT, VN, P, S)
Вихід:
КС – граматика
![]() ,
що не містить недосяжних символів, для
якої
,
що не містить недосяжних символів, для
якої
![]() .
.
Метод
V0={S}; i=1.
 в
в
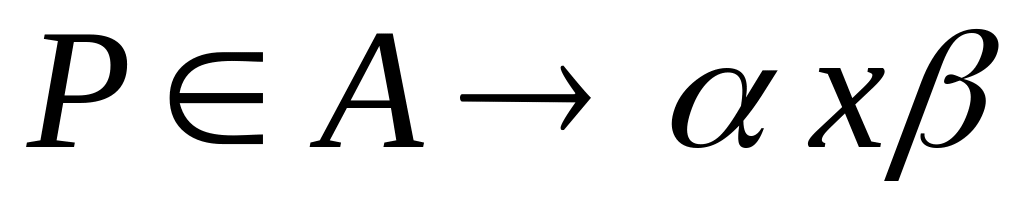 та
та
 .
.Якщо
 ,
то
,
то
 ,
і переходимо до кроку 2, інакше
,
і переходимо до кроку 2, інакше
 складається з правил множини Р,
що містять тільки символи з Vi;
.
складається з правил множини Р,
що містять тільки символи з Vi;
.
Визначення
Символ
називається марним
в граматиці G=(VT,
VN,
P,
S),
якщо множина
![]() є порожньою.
є порожньою.
Алгоритм видалення марних символів
Вхід: КС – граматика G=(VT, VN, P, S)
Вихід: КС – граматика , що не містить марних символів, для якої .
Метод
Рекурсивно будуємо множини N0, N1…
 ,
i=1.
,
i=1.
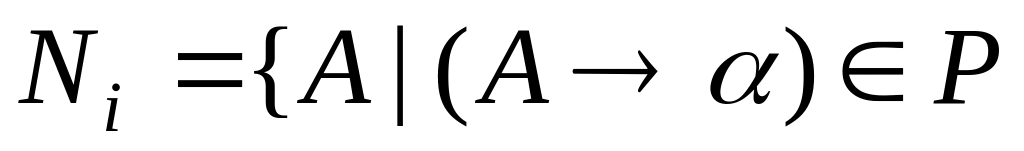 та
та
 .
.Якщо
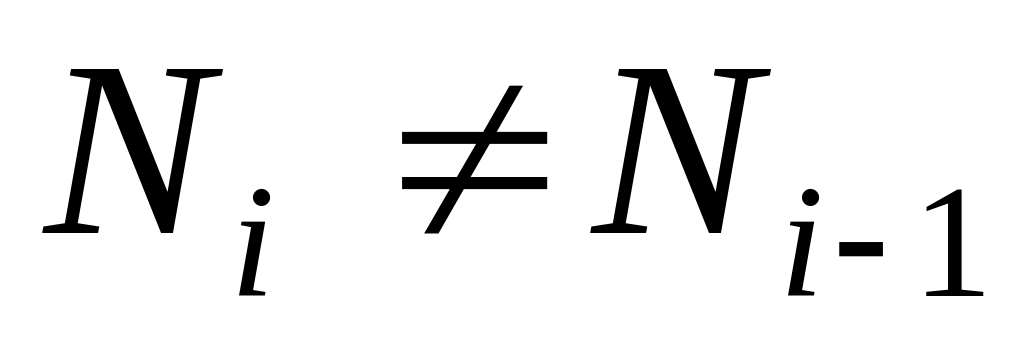 ,
то і=і+1,
і переходимо до кроку 2, інакше
,
то і=і+1,
і переходимо до кроку 2, інакше
 складається з правил множини Р,
що містять лише символи з
складається з правил множини Р,
що містять лише символи з

 .
.
Визначення
КС-граматика G називається приведеною, якщо в ній немає недосяжних та марних символів.
Алгоритм приведення граматики
Знаходяться та видаляються усі марні нетермінали.
Знаходяться та видаляються всі недосяжні символи.
Видалення символів супроводжується видаленням правил висновку, що містять ці символи.
Зауваження
Якщо у цьому алгоритмі переставити кроки 1 та 2, то не завжди результатом буде приведена граматика.
Для опису синтаксису мов програмування намагаються використовувати однозначні, приведені КВ-граматики.