

Лабораторна робота № 7
Тема. Інформаційні технології аналізу тенденцій та економічного прогнозування.
Мета. Формування навиків використання функції регресії для обчислення кутового коефіцієнта і точки перетину апроксимувальної прямої з віссю ординат, для знаходження квадрата коефіцієнта кореляції відповідного набору даних, а також виконання простого регресійного аналізу на підставі безпосередньо діаграми, побудованої за набором даних; ознайомлення з загальним підходом, придатним для довільної лінійно-регресійної моделі.
Контрольні питання
1. Як зробити доступним Пакет аналізу?
2. Як можна ініціалізувати Пакет аналізу?
3. Які засоби аналізу даних доступні користувачам?
4. Які властивості кількісних методів прогнозування?
5. Які особливості причинно-наслідкових моделей прогнозування?
6. У яких випадках доцільно застосовувати причинно-наслідкові моделі прогнозування?
7. Які задачі можна розв’язати за допомогою регресійного аналізу?
8. Які три методи регресійного аналізу найчастіше застосовують в економічному аналізі?
9. За допомогою яких функцій можна визначити параметри лінійної моделі?
10. Як побудувати на діаграмі лінії тренда Excel?
11. Для чого використовують функції ПРЕДСКАЗ, РОСТ, ТЕНДЕНЦИЯ, ЛИНЕЙН?
12. Які моделі лінійної регресії з двома коефіцієнтами найчастіше застосовують?
13. У яких випадках для виконання лінійної регресії зручніше використовувати пакет регресійного аналізу?
14. У якій послідовності виконують просту лінійну регресію з використанням пакета регресійного аналізу?
15. У чому полягає суть методів прогнозування часового ряду?
16. Що таке плинне середнє?
17. У чому суть експоненціального згладжування?
18. У чому полягає прогнозування за допомогою методу підбору кривої?
19. Яку функцію Excel використовують для одержання значення прогнозу методом простого плинного середнього?
Методичні рекомендації
MS Excel дає змогу розв’язувати складні економічні задачі, що забезпечене набором засобів аналізування даних (так званим Пакетом аналізу) і доступне через меню Сервіс → Аналіз даних.
Для аналізу даних за допомогою цих інструментів необхідно задати вхідні дані та вибрати параметри: аналіз виконуватиметься за допомогою відповідної процедури, а результат буде відображений у вихідному діапазоні. Низка засобів аналізу дає змогу зображати результат у графічному вигляді.
Для ініціалізації пакета аналізу необхідно приєднати його, використовуючи команду Сервіс → Надбудова → Аналіз даних (Analysis Tool Pak).
Серед доступних засобів аналізу даних наведемо такі:
дисперсійний аналіз;
кореляційний аналіз;
коваріаційний аналіз;
експоненціальне згладжування;
плинне середнє;
регресія та багато інших.
Важливою частиною економічної науки і практики є аналіз тенденції та прогнозування. Політика держави в галузі економіки ґрунтується на прогнозуванні внутрішнього валового продукту. Потребує прогнозування рівень безробіття, попит на автомобілі, холодильники тощо. Серед великих страхових компаній важко знайти таку, у якої не був би укладений контракт з експертом чи компанією для одержання економічних прогнозів. На їхній підставі мільярди доларів вкладають у позики та облігації. Подібних прикладів можна наводити багато.
Саме тому кількісні моделі відіграють щораз важливішу роль у побудові прогнозів. Яскравий приклад цього – програми керування запасами, які містять підпрограми прогнозування. Інший приклад – це довіра до точних прогнозів попиту в сфері обслуговування (готелі, туристичні компанії, автоперевезення), де застосовують складні математичні моделі оптимізації доходів. Під час розрахунку таких показників, як внутрішній валовий продукт чи курси валют, багато компаній покладається на економетричні моделі х їхніми можливостями прогнозування.
Розрізняють кількісні та якісні методи прогнозування.
Кількісні моделі прогнозування мають дві важливі та привабливі властивості.
1. Їх записують у математичному вигляді.
У кількісній моделі можна змінювати коефіцієнти або додавати умови, доки модель не буде давати надійні результати.
2. У разі використання електронних таблиць кількісні моделі можуть містити величезну кількість параметрів, що дає змогу будувати моделі, які адекватно відображають економічну ситуацію як окремого підприємства, так і цілих галузей.
Треба розрізняти причинно-наслідкові (каузальні) моделі та моделі часових рядів.
У причинно-наслідкових моделях прогнозування значення якої-небудь величини змінюють на підставі відомих значень іншої величини чи набору величин. Іншими словами, знаючи значення однієї змінної (чи, можливо, декількох змінних) можна передбачити значення іншої. Математично це виражають так. Нехай у – дійсне значення деякої потрібної нам змінної, а ŷ – передбачене або спрогнозоване її значення. Тоді
ŷ = f(x1, x2, …, xn),
де f – функція прогнозування; x1, x2, …, xn – набір змінних.
У цьому виразі змінні x називають незалежними змінними, а ŷ – залежною (або змінною відклику). Отже, знаючи значення незалежних змінних, можна передбачити значення залежної.
Причинно-наслідкові моделі застосовують тоді, коли незалежні змінні відомі заздалегідь, або ж їх спрогнозувати простіше, ніж залежну змінну ŷ. Наприклад, функціональне відношення обсягів продажу капусти і вугілля за рік може бути цікавим для соціологів, проте як би не було просто передбачити попит на капусту, навряд чи це матиме яке-небудь значення для вугільної промисловості. Однак у компаніях, як звичайно, шукають зв’язок між обсягами продажу й обсягами внутрішнього валового продукту за цей же період. Отже, можна досить точно спрогнозувати обсяг продажу компанії на наступний місяць, використовуючи дані про очікуваний обсяг внутрішнього валового продукту.
Тому для вибору причинно-наслідкової моделі прогнозування повинні виконуватися дві умови:
1) повинен існувати зв’язок, який можна налагодити на підставі даних за минулий період, між залежною змінною і незалежними;
2) значення незалежної змінної за період, за який потрібно зробити прогноз, повинні бути відомі.
У причинно-наслідкових моделях прогнозування часто використовують підхід, який називають підбором кривої за точками.
Найпростіший метод прогнозування – звичайний метод “зі стелі”, коли менеджер або група менеджерів шляхом експертної оцінки аналізують тенденції на підставі досвіду і знання ринку. Однак такий підхід суб’єктивний і орієнтований на короткочасний період, оскільки багато менеджерів просто переносить недавній досвід на майбутнє та ігнорують довготермінові тренди.
Є й об’єктивніші методи (наприклад, оцінка за середнім значенням результатів попередніх періодів), однак їх можна використовувати для прогнозування тільки на декілька місяців уперед.
Найпотужнішою статистичною процедурою, яка набула найбільшої популярності в бізнесі, є регресійний аналіз. У найпростішій формі регресійний аналіз застосовують для визначення взаємозв’язку і залежності між двома факторами. Наприклад, виторг від реалізації може залежати від відсоткових ставок на кредити, а обсяг продажу – від затрат на рекламу. Залежний фактор називають залежною змінною (переважно її позначають як у), а фактор, від якого залежить ця змінна, – незалежною змінною (x).
Таку залежність часто зображають у вигляді графіка або діаграми, де незалежна змінна відображена на горизонтальній осі (x), а залежна – на вертикальній осі (у).
За умови, що значення змінних відомі, регресійний аналіз можна застосовувати для розв’язування двох таких задач:
визначення залежності між відомими значеннями x та у і використання результатів для обчислення і зображення на графіку загального тренду в цій залежності;
використання наявного тренду для прогнозування майбутніх значень у.
Зазначимо, що Excel містить хороший набір інструментів, які дають змогу обчислювати поточний тренд і будувати прогнози незалежно від типу аналізованих даних.
В економічному аналізі найчастіше застосовують три методи регресійного аналізу.
■ Проста регресія. Цей тип регресії використовують під час аналізу залежності від однієї змінної. Наприклад, залежна змінна – виторг від реалізації, а незалежна – рівень відсоткових ставок. Крім того, має значення характер залежності:
лінійна залежність: у разі зображення даних на графіку одержані точки лежать (з можливими відхиленнями) на деякій прямій лінії;
нелінійна залежність: у разі зображення даних на графіку одержані точки утворюють криву.
■ Поліноміальна регресія. Цей тип регресії застосовують для аналізу залежності від однієї незалежної змінної, коли характер змінної описує поліном.
■ Множинна регресія. Цей тип регресії використовують для аналізу залежності від декількох змінних. Наприклад, як залежну змінну досліджують обсяг продажу, а незалежні змінні – рівень відсоткових ставок і дохід фізичних осіб.
Під час роботи з лінійними даними залежна змінна пов’язана з незалежною змінною деяким сталим коефіцієнтом. Наприклад, обсяг продажу (залежна змінна) може збільшуватися на сто тисяч одиниць зі зменшенням відсоткової ставки (незалежна змінна) на 1%. Аналогічно, приріст доходу від діяльності підрозділу (залежна змінна) зі збільшенням затрат на рекламу (незалежна змінна) на 10 000 може становити 100 000.
Параметри лінійної моделі y = mx +b (де m кутовий коефіцієнт (Slope) і точку перетину з віссю ординат (Intercept) прямої лінії можна визначити за допомогою функцій НАКЛОН (SLOPE) і ОТРЕЗОК (INTERCEPT).
Функція НАКЛОН (SLOPE) визначає коефіцієнт лінійного тренда.
Синтаксис: НАКЛОН (відомі_значення_у; відомі_значення_х).
Функція ОТРЕЗОК (INTERCEPT) визначає точку перетину лінії лінійного тренда з віссю ординат.
Синтаксис: ОТРЕЗОК (відомі_значення_у; відомі_значення_х).
Якщо до наведених вище функцій додати функцію КВПИРСОН (RSQ), що обчислює квадрат коефіцієнта кореляції (Coefficient of determination), одержимо найпростіший набір, який дає змогу розв’язати багато задач з аналізу даних.
Функція КВПИРСОН (RSQ) визначає квадрат коефіцієнта кореляції.
Синтаксис: КВПИРСОН (відомі_значення_у; відомі_значення_х).
Аргументи функцій НАКЛОН, ОТРЕЗОК та КВПИРСОН означають таке:
відомі_значення_у – масив відомих значень залежної спостереженої величини;
відомі_значення_х – масив відомих значень незалежної спостереженої величини.
Функції НАКЛОН та ОТРЕЗОК обчислюють за такими формулами:
![]()

Розглянемо задачу побудови рівняння регресії на прикладі лінійної моделі.
Приклад 1. Задамо дві спостережувані величини х та у – обсяг реалізації (млн грн.) фірми, яка торгує старими автомобілями, за шість тижнів її роботи (х – звітний тиждень, у – обсяг реалізації за цей тиждень).
Обчисліть кутовий коефіцієнт, знайдіть точку перетину лінії регресії з віссю координат, а також квадрат коефіцієнта кореляції.
Розв’язування. Розмістимо значення х у комірках А4:А9, а у – у комірках В4:В9. Для розв’язування цієї задачі відведемо під змінну m комірку D4.
D4 |
▼ ■ |
= НАКЛОН (B4:B9; A4:A9) |
||||
|
A |
B |
C |
D |
E |
F |
1 |
Лінійна регресія за допомогою функцій Excel |
|
|
|||
2 |
звітний |
обсяг |
|
|
|
|
3 |
тиждень – х |
реалізації – у |
|
m |
|
|
4 |
1 |
7 |
НАХИЛ |
1,88571 |
|
|
5 |
2 |
9 |
|
b |
|
|
6 |
3 |
12 |
ВІДРІЗОК |
|
|
|
7 |
4 |
13 |
|
R2 |
|
|
8 |
5 |
14 |
КОЕФІЦІЄНТ КОРЕЛЯЦІЇ В КВАДРАТІ |
|
|
|
9 |
6 |
17 |
|
|
|
|
Рис. 1.
У цьому випадку вивчаємо залежність обсягу реалізації від звітного тижня, тому залежною змінною є обсяг реалізації (комірки В4:В9), а порядковий номер тижня (комірки А4:А9) вважають незалежною змінною. Результати розрахунку кутового коефіцієнта показані на рис. 1.
Аналогічно, точку перетину прямої регресії з віссю ординат можна знайти за допомогою функції ОТРЕЗОК з тими ж аргументами (рис. 2).
Квадрат коефіцієнта кореляції (R2) обчислюють за допомогою функції КВПИРСОН з тими ж аргументами, що і в двох попередніх функціях (рис. 3).
Одержані результати свідчать про те, що пряма, яка найліпше описує кутовий коефіцієнт m = 1,88571 шт./тиждень і перетинає вісь ординат у точці b = 5,400 шт. значення R2 = 0,9723 (ці величини отримано безпосередньо з даних без побудови діаграми).
Отже, обчислено кутовий коефіцієнт, знайдено точку перетину лінії регресії з віссю ординат, а також величину R2. Наскільки добре пряма лінії описує дані? Щоб відповісти на це запитання, необхідно побудувати діаграму з даними і лінією регресії, яка дає змогу візуально переконатися в ступені їхнього збігу.
D4 |
▼ ■ |
= ОТРЕЗОК (B4:B9; A4:A9) |
||||
|
A |
B |
C |
D |
E |
F |
1 |
Лінійна регресія за допомогою функцій Excel |
|
|
|||
2 |
звітний |
обсяг |
|
|
|
|
3 |
тиждень – х |
реалізації – у |
|
m |
|
|
4 |
1 |
7 |
НАХИЛ |
1,88571 |
|
|
5 |
2 |
9 |
|
b |
|
|
6 |
3 |
12 |
ВІДРІЗОК |
|
|
|
7 |
4 |
13 |
|
R2 |
|
|
8 |
5 |
14 |
КОЕФІЦІЄНТ КОРЕЛЯЦІЇ В КВАДРАТІ |
|
|
|
9 |
6 |
17 |
|
|
|
|
Рис. 2.
D4 |
▼ ■ |
= КВПИРСОН (B4:B9; A4:A9) |
||||
|
A |
B |
C |
D |
E |
F |
1 |
Лінійна регресія за допомогою функцій Excel |
|
|
|||
2 |
звітний |
обсяг |
|
|
|
|
3 |
тиждень – х |
реалізації – у |
|
m |
|
|
4 |
1 |
7 |
НАХИЛ |
1,88571 |
|
|
5 |
2 |
9 |
|
b |
|
|
6 |
3 |
12 |
ВІДРІЗОК |
|
|
|
7 |
4 |
13 |
|
R2 |
|
|
8 |
5 |
14 |
КОЕФІЦІЄНТ КОРЕЛЯЦІЇ В КВАДРАТІ |
|
|
|
9 |
6 |
17 |
|
|
|
|
Рис. 3.
Як тільки дані зображено в графічному вигляді, регресію виконують за допомогою кількох клацань мишки, тому регресію з використанням прямої часто застосовують, незважаючи на те, що залежність між змінними не лінійна, а складніша.
Сформулюємо практичне правило: завжди треба будувати діаграму, на якій зображена крива регресії і дані, щоб можна було візуально оцінити ступінь збігу. У випадку, коли регресію виконують за допомогою лінії тренда, крива регресії автоматично додається на діаграму з відповідними даними.
Для виконання лінійної регресії, в процесі якої відбувається обчислення кутового коефіцієнта і точки перетину прямої, що апроксимується, з віссю ординат, обчислюють різні суми, які охоплюють значення х (незалежної змінної) та у (залежної змінної). За допомогою цих сум і рівнянь (1) можна було б обчислити кутовий коефіцієнт m і знайти точку перетину прямої регресії, яка найліпше описує дані, з віссю ординат (b). Однак у цьому немає потреби, оскільки формули (1) вбудовані в Excel.
Під час побудови на діаграмі лінії тренда Excel автоматично обчислює всі необхідні суми, потім знаходить значення коефіцієнтів m і b, а також квадрат коефіцієнта кореляції (достовірність апроксимації) R2. Завдяки тому, що лінії тренда будується на діаграмі, можна переконатися, наскільки добре вона описує дані. Рівняння лінії тренда і значення R2 за замовчуванням на діаграмі не відображаються. Щоб відобразити цю інформацію, треба скористатися вкладкою Параметри діалогового вікна Лінія тренда.
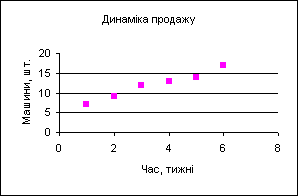
Опишемо застосування лінії тренда на прикладі даних, розглянутих вище. Перший крок у використанні лінії тренда для одержання регресії – це зображення даних у графічному вигляді на точковій діаграмі (рис. 4).
Зазначимо, що звичайно дані на точковій діаграмі позначаються маркерами, але не з’єднуються кривими, щоб ліпше було видно, наскільки близько від них проходить апроксимувальна лінія.
Лінійна регресія за допомогою лінії тренда |
|
|
|
|||||
звітний |
обсяг |
|
|
|
|
|
|
|
тиждень х |
р
|
|
||||||
1 |
7 |
|||||||
2 |
9 |
|||||||
3 |
12 |
|||||||
4 |
13 |
|||||||
5 |
14 |
|||||||
6 |
17 |
|||||||
|
|
|||||||
|
|
|||||||
|
|
|||||||
|
|
|||||||
|
|
|||||||
|
|
|
|
|
|
|
|
|
 еалізації
у
еалізації
уРис. 4.
Далі виділяють точки графіка подвійним клацанням, а потім клацають правою кнопкою мишки на довільному з маркерів даних. У контекстному меню, що відкривається, вибирають команду Лінії тренда (Trend line).
У діалоговому вікні Лінія тренда на вкладці Тип (Type) у групі Побудова лінії тренда (апроксимація і згладжування) (Trend/Regression type) вибирають параметр Лінійна (Linear), а на вкладці Параметри (Options) задають прапорці Показувати рівняння на діаграмі (Display Equation on Chart) і Помістити діаграму величини достовірності апроксимації (R^2) (Display R-squared) (тобто на діаграму потрібно помістити значення квадрата коефіцієнта кореляції.
Щоб закрити діалогове вікно Лінія тренда і додати до діаграми лінію тренда, треба натиснути на кнопку ОК (рис. 5).
Лінійна регресія за допомогою лінії тренда |
|
|
|
|||||
звітний |
обсяг |
|
|
|
|
|
|
|
тиждень х |
реалізації у |
|
||||||
1 |
7 |
|||||||
2 |
9 |
|||||||
3 |
12 |
|||||||
4 |
13 |
|||||||
5 |
14 |
|||||||
6 |
17 |
|||||||
|
|
|||||||
|
|
|||||||
|
|
|||||||
|
|
|||||||
|
|
|||||||
|
|
|
|
|
|
|
|
|
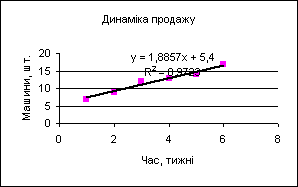
Рис. 5.
Під час додавання лінії тренда в програмі Excel на підставі графічних даних виконується лінійна регресія. Є змога відобразити рівняння кривої регресії на діаграмі. Для цього програмі Excel потрібно дати відповідні вказівки – двічі клацнути на лінії тренда, що приведе до відображення на екрані діалогового вікна Формат лінії тренда.
Далі треба перейти на вкладку Параметри і задати прапорці Показувати рівняння на діаграмі та Помістити на діаграму величину достовірності апроксимації (R^2), щоби ввести ці елементи в діаграму. Після натискання на кнопку ОК Excel відобразить на діаграмі рівняння регресії і величина R2.
Як видно з діаграми, рівняння регресії має вигляд
у = 1,8857х + 5,4
з достовірністю апроксимації 0,9723.
Якщо R2 є в діапазоні від 0,9 до 1,0, то цю залежність можна використовувати для передбачення результату. Чим ближче до одиниці коефіцієнт кореляції, тим обґрунтованіше це свідчить про лінійну залежність між спостережуваними величинами. Якщо коефіцієнт кореляції близький до -1, то це є ознакою зворотної залежності між спостережуваними величинами.
Нагадаємо, що ті ж результати одержані за допомогою функцій НАКЛОН, ОТРЕЗОК, КВПИРСОН. Це засвідчує, що пряма, яка найліпше описує дані, має кутовий коефіцієнт m = 1,8857 шт./тиждень (одиниці вимірювання одержані з урахуванням розмірностей даних) і точкою перетину з віссю ординат b = 5,4 шт. Наявність лінії тренда на діаграмі дає змогу візуально оцінити якість описання.
На підставі знайдених коефіцієнтів рівняння регресії може визначити теоретичне значення спостережуваної величини у в комірці Е4 (рис. 1) при х із А4 за формулою
= $D$4 * А4 + $D$6 = 1,88 * 1 + 5,4 = 7.
Аналогічно можна знайти теоретичні значення спостережуваної величини в комірках Е5:Е6 – 9; 11; 13; 15; 17.
Однак теоретичне значення у у фіксованій точці можна обчислити і без попереднього визначення коефіцієнтів лінійної моделі за допомогою функції ПРЕДСКАЗ (Forecast).
Синтаксис (х; відомі_значення_у; відомі_значення_х).
Функція ПРЕДСКАЗ обчислює або передбачає майбутнє значення за наявним значенням.
Аргументи функції означають таке:
х – це точка даних, для якої передбачають значення;
відомі_значення_у – масив відомих значень залежної спостереженої величини або інтервал даних;
відомі_значення_х – масив відомих значень незалежної спостереженої величини або інтервал даних. Якщо аргумент відомі_значення_х опущений, то вважають, що це масив {1; 2; 3; …} такого ж розміру, як і масив відомі_значення_у.
Наприклад, теоретичне значення в комірці Е4 (рис. 1) можна також визначити за формулою
= ПРЕДСКАЗ (Е4; $В$4:$В9; $А$4:$А$9).
Використання лінії тренда, яка відображена на діаграмі, має той недолік, що ви не можете обчислити фактичні значення, з якими працюєте. Якщо необхідно одержати числові значення в таблиці, то окремі точки на лінії тренда можна визначити за допомогою регресійного рівняння. А як діяти у випадку зміни первісних даних? Наприклад, рівняння могло бути побудоване на основі оцінок, а не фактичних значень, або значення могли бути замінені точнішими даними. Тоді потрібно вилучити стару лінію тренда, додавши нову, і перераховувати значення тренда з нового одержаного рівняння.
Якщо необхідно працювати з числовими значеннями тренда, то повторення одних і тих же дій з рівнянням тренда можна уникнути.
Для цього треба обчислити значення тренда за допомогою функції Excel ТЕНДЕНЦИЯ (Trend).
Функція ТЕНДЕНЦИЯ обчислює значення рівняння лінійної регресії для цілого діапазону значень незалежної змінної як для одновимірного, так і для багатовимірного рівняння регресії. Багатовимірна лінійна модель регресії має вигляд
у = m1 · x1 + … + mn · xn + b.
Синтаксис ТЕНДЕНЦИЯ (відомі_значення_у; [відомі_значення_х]; [нові_значення_х]; [конст]).
Аргументи функції означають таке:
відомі_значення_у – це посилання на діапазон або масив відомих значень спостереженої величини, наприклад, статистичний ряд даних, за яким необхідно обчислити тренд;
відомі_значення_х – це посилання на діапазон або масив значень х, які відповідають відомим значенням у. Якщо цей аргумент не заданий, то як значення х беруть послідовність {1, 2, 3, …, n}, де n – кількість відомих значень у;
нові_значення_х – це посилання на діапазон або масив значень х, для яких функція ТЕНДЕНЦИЯ повертає відповідні значення у;
конст – це логічне значення, яке визначає застосування константи. Якщо цей аргумент має значення ХИБА, то беруть b = 0, а якщо ІСТИНА або опущений, b обчислюють звичним способом.
Якщо будують багатовимірну лінійну модель, то аргументи відомі_значення_х і нові_значення_х повинні містити стовпець (чи рядок) для кожної незалежної змінної. Якщо аргумент нові_значення_х опущений, то вважають, що він збігається з аргументом відомі_значення_х.
Функція ТЕНДЕНЦИЯ – найпростіший спосіб обчислення значень тренда, але в Excel є інший метод, який дає змогу визначити коефіцієнт нахилу і константу регресійного рівняння. Ці значення можна підставити в загальне рівняння регресії у = mх + b, замість m і b, відповідно.
Коефіцієнти регресійного рівняння можна обчислити за допомогою функції ЛИНЕЙН (Linest).
Функція ЛИНЕЙН повертає масив { mn, …, m1, b} значень параметрів рівняння багатовимірної лінійної регресії.