

Метод арифметичного кодування даних.
Арифметическое кодирование решает проблемы кода хаффманапутем присвоения кода всему, обычно, большому передаваемому файлу вместо кодирования отдельных символов. Алгоритм читает входной файл символ за символом и добавляет биты к сжатому файлу.
Конспект:
Сутність полягає в тому що повідомленню присвоюється велике число.
М=велике.
Кодуєтсяне окремі символи а повідомлення усе повідомлення в цілому.
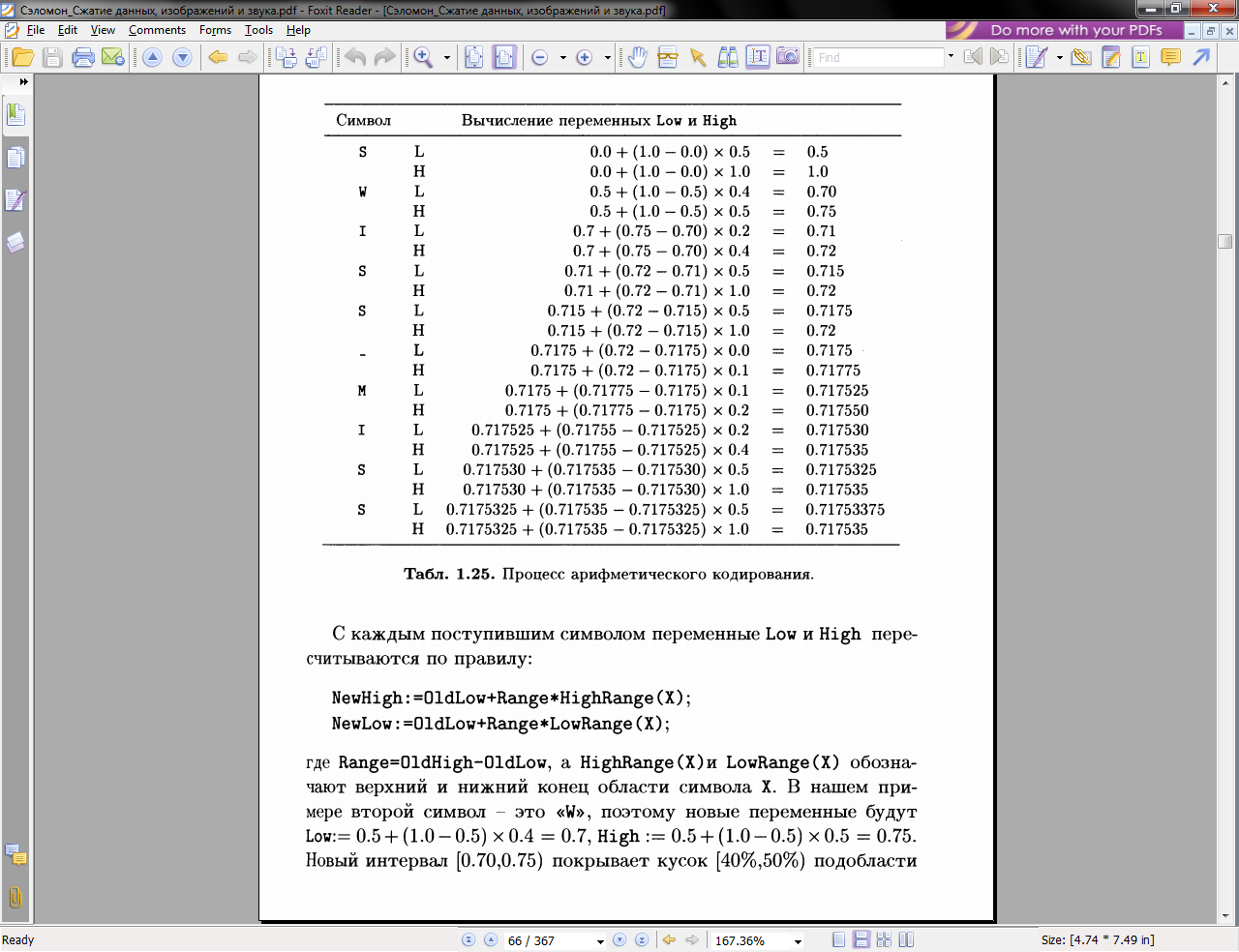
Следующий пример будетнемногоболеезапутанным. Мыпродемонстрируем шаги сжатия для строки «SWISS-MISS». В табл. 1.24 указана информация, приготовленная на предварительномэтапе
{статистическая модель данных). Пять символов на входе можно упорядочить любым способом. Для каждого символа сначала вычислена его частота, затем найдена вероятность ее появления (частота, деленная на длину строки, 10). Область [0,1) делится между символами в любом порядке. Каждый символ получает кусочек или подобласть, равную его вероятности. Таким образом, символ «S»
Получает интервал [0.5,1.0) длины 0.5, а символу «I» достается интервал [0.2,0.4) длины 0.2.

Процесс кодирования начинается инициализацией двух переменных Low и High и присвоениемим 0 и 1, соответственно. Они определяют интервал [Low,High). По мере поступления и обработки символов, переменные Low и High начинают сближаться, уменьшая интервал. После обработки первого символа «S», переменные Low и High равны 0.5 и 1, соответственно.
Декодер работает в обратномпорядке. Сначала он узнаётсимволыалфавита и считывает табл. 1.24. Затем он читает цифру «7» и узнаёт, что весь код имеет вид 0.7... Это число лежитвнутриинтервала [0.5,1) символа «S». Значит, первый символ был S. Далее декодер удаляетэффектсимвола S изкода с помощьювычитаниянижнегоконцаинтервала S и деления на длинуэтогоинтервала, равную 0.5. Результатом будет число 0.4350675, котороеговорит декодеру, чтовторой символ был «W» (поскольку область «W» - [0.4,0.5)). Чтобыудалитьвлияниесимвола X, декодер делаетследующеепреобразование над кодом: Code : = (Code-LowRange(X))/Range, гдеRangeобозначаетдлинуинтерваласимвола X. В табл. 1.26 отраженпроцессдекодированиярассмотренной строки.

Метод цілочисленого арифметичного кодування даних.
На практиці було запропоновано обчислення з обмеженою розрядністю з використанням цілих чисел.
Приклад: SWISS_MISS
СМОТРЕТЬ 24 ВОПРОС ТАМ ФОРМУЛЫ.
1 |
|
2 |
|
|
4 |
5 |
S |
L= H= |
0+(10000-0)*0.5 0+(10000-0)*1.0-1 |
= = |
5000 9999 |
|
5000 9999 |
W |
L= H= |
5000+(10000-5000)*0.4 5000+(10000-5000)*0.5 |
= = |
7000 7499 |
7 |
0000 4999 |
I |
L= H= |
0+(5000-0)*0.2 0+(5000-0)*0.4-1 |
= = |
1000 1999 |
1 |
0000 9999 |
S |
L= H= |
0+(10000-0)*0.5 0+(10000-0)*1.0-1 |
= = |
5000 9999 |
|
5000 9999 |
S |
L= H= |
5000+(10000-5000)*0.5 5000+(10000-5000)*1.0-1 |
= = |
7500 9999 |
|
7500 9999 |
_ |
L= H= |
7500+(10000-7500)*0.0 7500+(10000-7500)*0.1-1 |
= = |
7500 7749 |
7 |
5000 7499 |
M |
L= H= |
5000+(7500-5000)*0.1 5000+(7500-5000)*0.2 |
= = |
5250 5499 |
5 |
2500 4999 |
I |
L= H= |
2500+(5000-2500)*0.2 2500+(5000-2500)*0.4-1 |
= = |
3000 3499 |
3 |
0000 4999 |
S |
L= H= |
0+(5000-0)*0.5 0+(5000-0)*1.0-1 |
= = |
2500 4999 |
|
2500 4999 |
S |
L= H= |
2500+(5000-2500)*0.5 2500+(5000-2500)*1.0-1 |
= = |
3750 4999 |
3750 |
3750 4999 |
Декодер работает в обратном порядке. В начале переменным Low и High присваиваются значения 0000 и 9999 соответственно, а переменной Code значение 7175. На основе этой информации требуется определить первый закодированный символ. Для этого число переменной Code нужно корректно представить в интервале от 0 до 1. В самом начале интервал такой и есть, поэтому частота символа, соответствующая значению Code будет равна
index = 7175/10000=0,7175.
Эта частота попадает в диапазон [0,5 1) и соответствует символу S. Теперь границы Low и High пересчитываются, так как это делалось в кодере и принимают значения 5000 и 9999 соответственно. Так как значащие цифры этих переменных отличаются, то переменная Code остается прежней и величина
index = (7175-5000)/(10000-5000)=0,4350.
Это значение попадает в диапазон [0,4 0,5) и соответствует символу W. После этого величины Low и High принимают значения 7000 и 7499 и после отбрасывания значащей цифры переходят в 0000 и 4999 соответственно, а переменная Code преобразуется в 1753. Таким образом раскодируется вся последовательность.
На практике обычно значение index принимает целочисленные значения, которые вычисляются по формуле
index = ((Code-Low)*10-1)/(High-Low+1)
и округляют до ближайшего целого.
Может показаться, что приведенный выше пример не производит никакого сжатия. Для того чтобы выяснить степень сжатия результаты кодирования нужно перевести в двоичную форму. Так как из конечного интервала можно выбрать любое число, выберем наименьшее для хранения – это 717534, которому соответствует битовое представление 10101111001011011110 и составляет 20 бит. И строка из 10 символов сжимается в 20 бит. Хорошее ли это сжатие? Для этого нужно найти энтропию кодируемой последовательности и она будет равна.
Словарні методи стиску даних. Метод стиску даних Лемпела-Зіва LZ77.
Cловарні методи напряму не є статистичними методами, не використовують коди змінної довжини, але являються практичними методом і може використовуватись на практиці в багатьох прикладах.
Якщо для кодування використовуємо словар об’ємом 219 текстів = 524288 символів. В багатьох випадках слова можна не знайти в словарі тому необхідно слова передавати у вигляді відомих у цьому словарі знаків. Для цього використовується флагова комбінація.
Визначимо розмір файла для словаря:
- якщо ймовірність знаходження слова в словарі = Р і бажано мати стиск, н.д. з 48 біт в 20 біт в цьому випадку необхідно щоб Р було > ніж 0.29
Зауваження:
- якщо вхідний файл має текст, достатній розмір словаря десь 500000 фраз;
- якщо текст специфічний ми можемо мати не стиск,а розширення данних;
- словарі можуть бути статичними, тобто незмінними та динамічними (словар оновлюється постійно).
Словарні методи мають переваги:
- простота реалізації;
- невикористовуються обчислення.
Метод LZ77
Суть метода:
Метод використовує «скользящее» вікно, яке складається з двох частин: ліва – буфер пошуку і визначає словар для пошуку фраз, права – буфер, що попереджує і кодує символи.
Кодер в процесі роботи переглядає буфер пошуку в якому знаходяться символи, що вже були закодовані знаходять співпадаючі фрази між буфер пошуку та буфером, що попереджає і кодує їх.
Код визначається як значення зсуву і розміру к-ті символів, що співпадають.
Код LZ77 має три поля: зсув, довжина і наступний символ. Якщо в буфері не знаходять символ, то записується мітка «0,0» і значення наступного символа. Такі мітки «0,0» не забезпечують гарний стиск. Розмір мітки зсуву визначається як log2 S , де S – розмір буфера пошуку.
Приклад: закодувати «хаффманхаффман»
|
Хаффманхаффман 0,0,х |
Х |
Аффманхаффман 0,0,а |
Ха |
Ффманхаффман 0,0, ф |
Хаф |
Фманхаффман 1,1, м |
Хаффм |
Анхаффман 4,1, н |
хаффман |
Хаффман 7,7, хаффман |
Словарні методи стиску даних. Метод стиску даних Лемпела-Зіва LZ78.
Cловарні методи напряму не є статистичними методами, не використовують коди змінної довжини, але являються практичними методом і може використовуватись на практиці в багатьох прикладах.
Якщо для кодування використовуємо словар об’ємом 219 текстів = 524288 символів. В багатьох випадках слова можна не знайти в словарі тому необхідно слова передавати у вигляді відомих у цьому словарі знаків. Для цього використовується флагова комбінація.
Визначимо розмір файла для словаря:
- якщо ймовірність знаходження слова в словарі = Р і бажано мати стиск, н.д. з 48 біт в 20 біт в цьому випадку необхідно щоб Р було > ніж 0.29
Зауваження:
- якщо вхідний файл має текст, достатній розмір словаря десь 500000 фраз;
- якщо текст специфічний ми можемо мати не стиск,а розширення данних;
- словарі можуть бути статичними, тобто незмінними та динамічними (словар оновлюється постійно).
Словарні методи мають переваги:
- простота реалізації;
- невикористовуються обчислення.
Метод LZ78
Основується на тому, що схожі образці стискувальних даних знаходяться близько один від одного. Якщо слова зустрічаються рівномірно тексту – стиску не буде. Копії даних, які зберігаються в буфері пошуку постійно змінюються. Бажано, щоб часто зустрічаємі слова десь зберігалися. Для ефективної роботи LZ78 необхідно мати великий буфер пошуку, але при цьому зростає час пошуку, що знижує швидкість алгоритму.
Алгоритм будується на основі створення словаря та кодування фраз з використанням тільки двох полів.
В процесі стиску словар починається з коротких строк і далі все довші строки добавляються у словар. Розмір словаря може бути фіксований і коли він заповнюється можна використати декілька рішень:
Словар заморожується;
Видаляються з нього самі старі строки;
Весь словар знищується і будується новий.
Словар починається з нульової фрази.
0 |
Null |
|
1 |
S |
0, s |
2 |
I |
0, i |
3 |
R |
0, r |
4 |
- |
0, - |
5 |
Si |
1, i |
6 |
D |
0, d |
7 |
-e |
4, e |
Словарні методи стиску даних. Метод стиску даних Лемпела-Зіва LZW.
Cловарні методи напряму не є статистичними методами, не використовують коди змінної довжини, але являються практичними методом і може використовуватись на практиці в багатьох прикладах.
Якщо для кодування використовуємо словар об’ємом 219 текстів = 524288 символів. В багатьох випадках слова можна не знайти в словарі тому необхідно слова передавати у вигляді відомих у цьому словарі знаків. Для цього використовується флагова комбінація.
Визначимо розмір файла для словаря:
- якщо ймовірність знаходження слова в словарі = Р і бажано мати стиск, н.д. з 48 біт в 20 біт в цьому випадку необхідно щоб Р було > ніж 0.29
Зауваження:
- якщо вхідний файл має текст, достатній розмір словаря десь 500000 фраз;
- якщо текст специфічний ми можемо мати не стиск,а розширення данних;
- словарі можуть бути статичними, тобто незмінними та динамічними (словар оновлюється постійно).
Словарні методи мають переваги:
- простота реалізації;
- невикористовуються обчислення.
Метод LZW
Відноситься до словарних методів і для кодування використовується тільки одна команда. Порядок стиску:
L |
Перевірка наявності |
Формування нового запису |
Вихід |
s |
так |
|
|
si |
ні |
256 –si |
115(s) |
i |
так |
|
|
ir |
ні |
257 – ir |
105(i) |
r |
так |
|
|
r- |
ні |
258 – r- |
114(r) |
- |
так |
|
|
-s |
ні |
259 - -s |
32(-) |
s |
так |
|
|
si |
так |
|
|
sid |
ні |
260 –sid |
256(si) |
d |
так |
|
|
d- |
ні |
261 – d- |
100(d) |