

18. !!! Неизвестно
19. Сжатие информации без потерь осуществляется статистическим кодированием или на основе предварительно созданного словаря. Статистические алгоритмы (напр., схема кодирования Хафмана) присваивают каждому входному символу определенный код. При этом наиболее часто используемому символу присваивается наиболее короткий код, а наиболее редкому - более длинный. Таблицы кодирования создаются заранее и имеют ограниченный размер. Этот алгоритм обеспечивает наибольшее быстродействие и наименьшие задержки. Для получения высоких коэффициентов сжатия статистический метод требует больших объемов памяти. Статистические методы сжатия учитывают статистику появления символов в тексте. Используются для текстовых данных. Статистические методы учитывают не только статистику появления символов, но и их корреляционные связи.
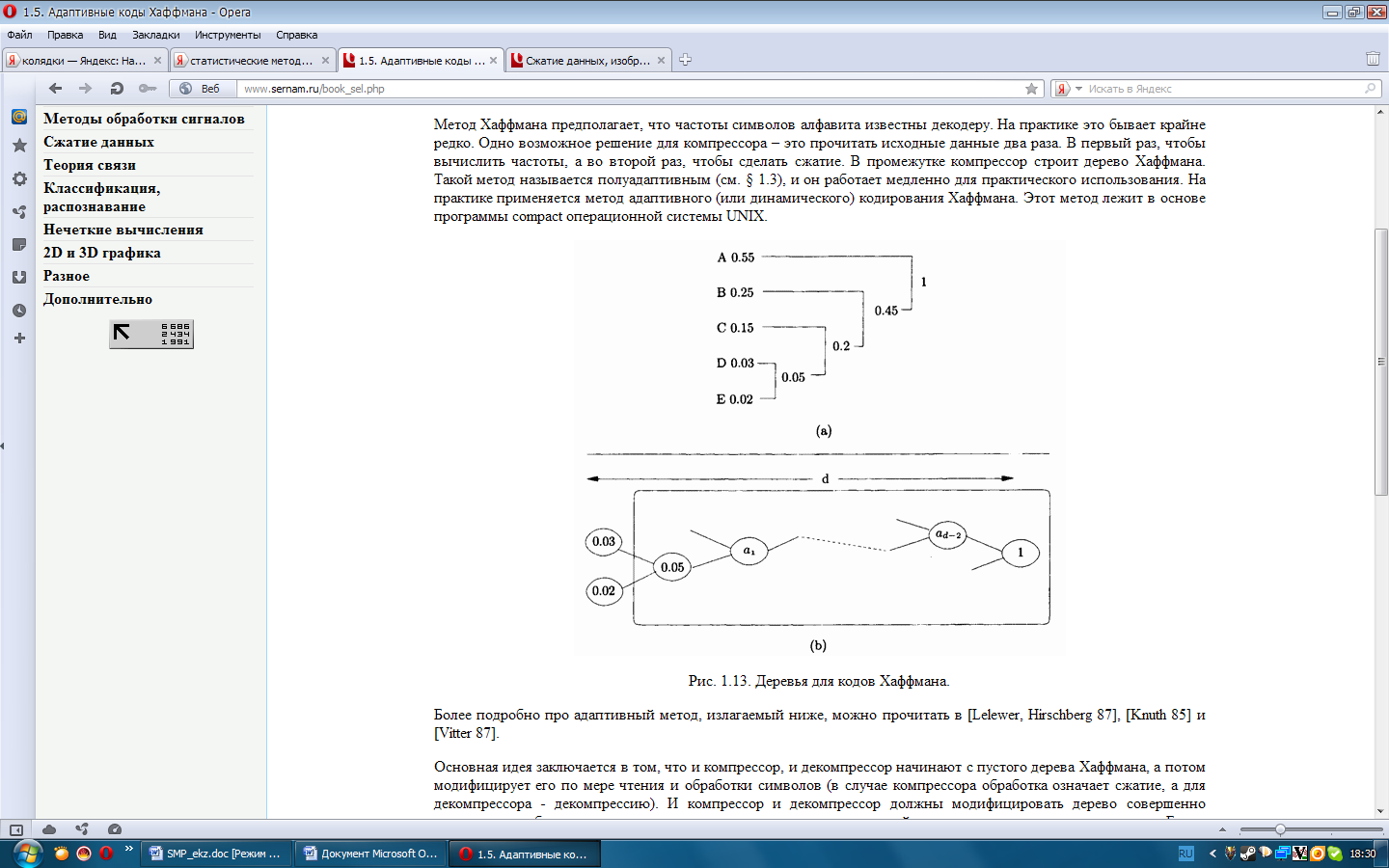
20. Метод Хаффмана предполагает, что частоты символов алфавита известны декодеру. На практике это бывает крайне редко. Одно возможное решение для компрессора – это прочитать исходные данные два раза. В первый раз, чтобы вычислить частоты, а во второй раз, чтобы сделать сжатие. В промежутке компрессор строит дерево Хаффмана. Такой метод называется полуадаптивным и он работает медленно для практического использования. На практике применяется метод адаптивного (или динамического) кодирования Хаффмана. Этот метод лежит в основе программы compact операционной системы UNIX.
Основная идея заключается в том, что и компрессор, и декомпрессор начинают с пустого дерева Хаффмана, а потом модифицирует его по мере чтения и обработки символов (в случае компрессора обработка означает сжатие, а для декомпрессора - декомпрессию). И компрессор и декомпрессор должны модифицировать дерево совершенно одинаково, чтобы все время использовать один и тот же код, который может изменяться по ходу процесса. Будем говорить, что компрессор и декомпрессор синхронизованы, если их работа жестко согласована (хотя и не обязательно выполняется в одно и то же время). Слово зеркально, возможно, лучше обозначает суть их работы. Декодер зеркально повторяет операции кодера.
В начале кодер строит пустое дерева Хаффмана. Никакому символу код еще не присвоен. Первый входной символ просто записывается в выходной файл в несжатой форме. Затем этот символ помещается на дерево и ему присваивается код. Если он встретится в следующий раз, его текущий код будет записан в файл, а его частота будет увеличена на единицу. Поскольку эта операция модифицировала дерево, его надо проверить, является ли оно деревом Хаффмана (дающее наилучшие коды). Если нет, то это влечет за собой перестройку дерева и перемену кодов.
Декомпрессор зеркально повторяет это действие. Когда он читает несжатый символ, он добавляет его на дерево и присваивает ему код. Когда он читает сжатый код (переменной длины), он использует текущее дерево, чтобы определить, какой символ отвечает данному коду, после чего модифицирует дерево тем же образом, что и кодер.