

Перелічити основні передумови регресійного аналізу. Сформулювати ідею принципу максимальної правдоподібності і показати, що по цьому принципу найкращими оцінками параметрів моделі є мнк–оцінки.
Предпосылки
регрессионного анализа: 1) y(xi) = yp(xi) + ei
(все ошибки
относятся только к результативному
признаку у,
объясняющие переменные х
измерены без ошибок); 2) М(ei) = 0
– систематических ошибок нет, выбранная
модель адекватная; 3) М(еiej) = 0
– ошибки разных наблюдений не коррелированы
(наблюдения независимые); 4)
![]() – наблюдения равноточные; 4) ошибки
распределены нормально. Отсюда получаем
плотность распределения отдельных
ошибок
– наблюдения равноточные; 4) ошибки
распределены нормально. Отсюда получаем
плотность распределения отдельных
ошибок
![]() и плотность распределения системы
независимых ошибок
и плотность распределения системы
независимых ошибок
![]() .
Согласно “принципу
максимума правдоподобия”
параметры модели (и оценку дисперсии
e2)
надо выбрать так, чтобы получить максимум
функции распределения f
(наблюдаемая система ошибок ei
должна быть наиболее вероятной). Из
условий максимума плотности совместного
распределения следуют метод наименьших
квадратов (параметры модели необходимо
определять из условий минимума e2),
а оценка дисперсии случайной ошибки
оказывается равной
.
Согласно “принципу
максимума правдоподобия”
параметры модели (и оценку дисперсии
e2)
надо выбрать так, чтобы получить максимум
функции распределения f
(наблюдаемая система ошибок ei
должна быть наиболее вероятной). Из
условий максимума плотности совместного
распределения следуют метод наименьших
квадратов (параметры модели необходимо
определять из условий минимума e2),
а оценка дисперсии случайной ошибки
оказывается равной
![]() .
.
Викласти ідею розрахунку дисперсій коефіцієнтів регресії і дисперсій розрахункових значень. Описати графічний спосіб побудови 95%-вої довірчої смуги на лінію регресії.
Согласно
предпосылкам регрессионного анализа,
все объясняющие переменные х
считаются измеренными точно, все
случайные ошибки относятся только к
результативному признаку у.
Эти ошибки независимые, равноточные
(имеют одинаковую дисперсию для любых
наблюдений), систематических ошибок
нет (т.е. М(ei) = 0).
МНК-оценки коэффициентов регрессии
являются линейными комбинациями значений
результативного признака уi
с неслучайными коэффициентами, отсюда
можно получить выражение ошибки
коэффициента регрессии как комбинацию
ошибок наблюдений и вычислить ее
дисперсию (дисперсия суммы независимых
величин равна сумме дисперсий, неслучайные
множители возводятся в квадрат). Так,
для линейной однофакторной модели
коэффициент регрессии вычисляется по
формуле
![]() ,
откуда получаем выражение случайной
ошибки коэффициента регрессии в виде
,
откуда получаем выражение случайной
ошибки коэффициента регрессии в виде
![]() ,
где х
и sx
– не случайные. Дисперсия этой ошибки
равна
,
где х
и sx
– не случайные. Дисперсия этой ошибки
равна
![]() .
Теперь рассмотрим случайную дисперсию
расчетных значений
.
Теперь рассмотрим случайную дисперсию
расчетных значений
![]() как линейную комбинацию случайных
величин
как линейную комбинацию случайных
величин
![]() и b1
с известными дисперсиями:
и b1
с известными дисперсиями:
![]() .
Как функция х
это есть уравнение сопряженной гиперболы
.
Как функция х
это есть уравнение сопряженной гиперболы
![]() ,
сдвинутой вправо на величину
,
сдвинутой вправо на величину
![]() с
полуосями а = sx
и
с
полуосями а = sx
и
![]() .
Достаточно построить только каркас
доверительной полосы на линию регрессии.
На интервале
.
Достаточно построить только каркас
доверительной полосы на линию регрессии.
На интервале
![]() ширина доверительной полосы практически
постоянна и равна удвоенной ошибке
среднего
ширина доверительной полосы практически
постоянна и равна удвоенной ошибке
среднего
![]() ;
строим на линии регрессии этот
параллелограмм; далее доверительная
полоса расширяется, приближаясь к
продолжениям диагоналей построенного
параллелограмма.
;
строим на линии регрессии этот
параллелограмм; далее доверительная
полоса расширяется, приближаясь к
продолжениям диагоналей построенного
параллелограмма.
В заключение приведем подробный вывод формулы для дисперсии коэффициента регрессии:
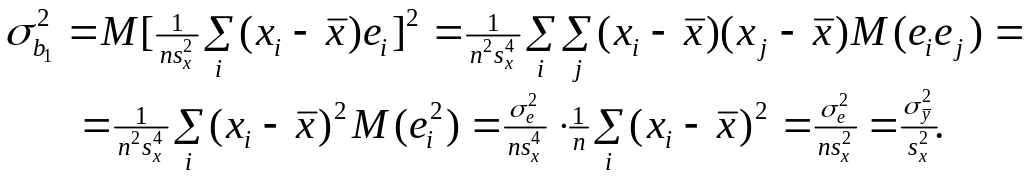
Пояснити спосіб вибіру форми зв’язку. Продемонструвати можливості узагальненої лінійної моделі, нелінійної щодо аргументів, але лінійної щодо параметрів. Розглянути стандартні перетворення змінних (логарифмування і перехід до зворотних величин).
Для МНК важно, чтобы форма связи была линейной относительно параметров (а не относительно х), тогда система нормальных уравнений для определения параметров будет линейной. Общий вид двухпараметрических моделей, линейных относительно параметров: Y = a + b X . где Y = F(x, y); X = Ф(х, у). Если эмпирические точки в преобразованных координатах (X, Y) не группируются вокруг некоторой прямой, то принятая форма связи должна быть отвергнута (надо подбирать другую, более подходящую). Чаще всего применяется или логарифмирование переменных, или переход к обратным величинам, что дает дополнительно 7 нелинейных моделей, приведенных в таблице ниже (g2 – весовая функция):
Двухпараметрические зависимости Y(y) = a + b X(x)
Преобразования |
X = x |
X = ln x |
X = 1/x |
Y = y |
Линейная y = a + b x |
Логарифмическая y = a + b ln x |
Гиперболическая1 y = a + b / x |
Y = ln y g2 = y2 |
Показательная ln y = a + b x y = A eb x |
Степенная ln y = a + b ln x y = A xb |
S-образная ln y = a + b / x y = A eb / x |
Y = 1/y g2 = y4 |
Гиперболическая 2 1 / y = a + b x
|
|
Гиперболическая 3 1 / y = a + b / x
|
Роз’яснити ідею методу зважених найменших квадратів. Показати, що функціональні перетворення результативної ознаки приводять до порушення рівноточности (гомоскедастичністі) спостережень, і запропонувати вагову функцію для усунення наслідків порушення зазначеної передумови регресійного аналізу.
В
регрессионном анализе предполагается,
что дисперсия остатков модели ei
постоянна, не зависит ни от х,
ни от у,
ни от номера наблюдения (это свойство
называется гомоскедастичностью). При
нарушении этой предпосылки
(гетероскедастичность) оценки коэффициентов
регрессии оказываются смещенными
(сдвинутыми). Иногда известен закон
изменения дисперсии остатков модели и
мы можем подобрать такую функцию
g(x, y),
при умножении на которую ошибки
i = gi ei
становятся гомоскедастичными. Умножим
на эту функцию все уравнение регрессии
y = b0 + b1 x + e
и получим модель gy = b0 g+ b1 gx + .
Ошибки модели должны быть ортогональны
к каждому члену модели, откуда получаем
такую систему нормальных уравнений:
g2y = b0 g2+ b1 g2x
и g2yх = b0 g2х+ b1 g2x2 .
Здесь в
отличие от обычных уравнений нормальной
системы в каждой сумме присутствует
«весовой» множитель g2.
Решение данной системы формально будет
похоже на решение обычной системы, если
всюду вместо обычных средних использовать
«взвешенные» средние:
![]() .
Весовая функция g2
придает
большие «веса» надежным наблюдениям,
и меньшие – малонадежным (с большой
дисперсией), тем самым компенсирует
нежелательные последствия
гетероскедастичности. Функциональные
преобразования результативного признака
Y = F(y)
часто приводит к гетероскедастичности
(если исходные данные были гомоскедастичными).
Действительно, пусть F(у) – желаемое
функциональное преобразование, после
которого модель становится линейной
относительно параметров: F(yp) = b0 + b1 X ;
однако F(yp) =
F(y ‑ e) F(y) – eF '(y),
т.е. мы получили модель Y = b0 + b1 X + ,
где
.
Весовая функция g2
придает
большие «веса» надежным наблюдениям,
и меньшие – малонадежным (с большой
дисперсией), тем самым компенсирует
нежелательные последствия
гетероскедастичности. Функциональные
преобразования результативного признака
Y = F(y)
часто приводит к гетероскедастичности
(если исходные данные были гомоскедастичными).
Действительно, пусть F(у) – желаемое
функциональное преобразование, после
которого модель становится линейной
относительно параметров: F(yp) = b0 + b1 X ;
однако F(yp) =
F(y ‑ e) F(y) – eF '(y),
т.е. мы получили модель Y = b0 + b1 X + ,
где
![]() .
Если еi
были гомоскедастичными, то после
умножения их на
.
Если еi
были гомоскедастичными, то после
умножения их на
![]() гомоскедастичность будет нарушена. Для
нейтрализации гетероскедастичности
надо всю модель умножить на
гомоскедастичность будет нарушена. Для
нейтрализации гетероскедастичности
надо всю модель умножить на
![]() ,
т.е. в расчетах следует учесть весовую
функцию
,
т.е. в расчетах следует учесть весовую
функцию
![]() .
Например, при
.
Например, при
![]() весовая функция будет равна g2 = y4 .
весовая функция будет равна g2 = y4 .