

План издательства
|
Номер книги |
Номер автора |
|
1 |
3 |
|
1 |
2 |
|
2 |
3 |
|
3 |
1 |
|
3 |
2 |
Формальні граматики і мови.(37)
Формальні граматики були введені американським вченим, математиком та філософом, Н.Хомським в 50-тих роках ХХ сторіччя.
Формальна граматика
Формальна граматика
- це четвірка
![]() .
Де:
.
Де:
-
Т — алфавіт термінальних символів, терміналів (від англ. terminate - завершитись). Термінальні символи є алфавітом мови.
-
N — алфавіт нетермінальних символів, нетерміналів.
 ;
Нетермінали не входять в алфавіт мови.
;
Нетермінали не входять в алфавіт мови. -
S — аксіома, спеціально виділений нетермінальний символ.
![]()
-
P — скінченна підмножина множини
 .
Інколи визначають так:
.
Інколи визначають так: .
.
Елемент (α,β) з множини Р
називається правилом
виводу і записується
у вигляді
![]() .
Таким чином, ліва частина правила не
може бути порожньою. Правила з однаковою
лівою частиною записують:
.
Таким чином, ліва частина правила не
може бути порожньою. Правила з однаковою
лівою частиною записують:
![]() ,
βi,
i = 1,2,..,n - називаются альтернативами
правила виводу з ланцюжка α.
,
βi,
i = 1,2,..,n - називаются альтернативами
правила виводу з ланцюжка α.
Виведення в формальних граматиках
Ланцюжок
![]() назвемо
безпосередньо виведеним
з ланцюжка
назвемо
безпосередньо виведеним
з ланцюжка
![]() в
граматиці G
= {T,N,S,P}
(позначається
в
граматиці G
= {T,N,S,P}
(позначається
![]() ),
якщо
),
якщо
![]() .
.
Ланцюжок
![]() назвемо
виведеним
з ланцюжка
назвемо
виведеним
з ланцюжка
![]() в
граматиці G
= {T,N,S,P}
(позначається
в
граматиці G
= {T,N,S,P}
(позначається
![]() ),
якщо
),
якщо
![]()
Термінальний рядок називається правильним(або сентенціальною формою) відносно граматики G якщо він виводиться з аксіоми цієї граматики.
Неоднозначності, та стратегії виводу
Граматика G називається неоднозначною, якщо існує декілька варіантів виводу слова ω в G ( ω ∈ L(G ) ).
Приклад. Розглянемо таку граматику G = <N, Σ, P, S> зі схемою Р.
S → S +S |S *S |a
Покажемо, що для ланцюжка ω = a + a + a існує щонайменше два варіанти виводу:
-
S ⇒ S + S ⇒ S + S + S ⇒ a + S + S ⇒ a + a + S ⇒ a + a + a
-
S ⇒ S + S ⇒ a + S ⇒ a + S + S ⇒ a + a + S ⇒ a + a + a
В теорії граматик розглядається декілька стратегій виведення ланцюжка ω в G.
Лівостороння стратегія виводу ланцюжка ω в G — це послідовність кроків безпосереднього виводу, при якій на кожному кроку до уваги береться перший зліва направо нетермінал.
Правостороння стратегія виводу ω в G протилежна лівосторонній стратегії. З виводом ω в G пов'язане синтаксичне дерево, яке визначає синтаксичну структуру програми.
Формальні мови
Формальна мова породжена граматикою G - це множина термінальних рядочків, що виводяться з аксіоми, тобто множина усіх правильних рядків.
![]()
З іношого боку, множина термінальних рядків, таких, що вони можуть бути виведені в граматиці G, називається мовою, що може бути розпізнана в даній граматиці, або допускається даною граматикою.
-
Граматики G1 та G2 називаються еквівалентними, якщо L(G1) = L(G2).
-
Граматики G1 та G2 називаються майже еквівалентними, якщо
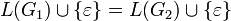 ,
тобто мови, ними породжувані, відрізняються
не більш ніж на ε.
,
тобто мови, ними породжувані, відрізняються
не більш ніж на ε.
Граматика може бути породжуючою та розпізнавальною, це залежить від "напрямку" застосування правил. Для породжучих граматик виведення починається з аксіоми і закінчується термінальним рядком (рядком, що скаладається тільки з терміналів). А розпізнавальні аналізують вхідний термінальний рядок на правильність, чи можна такий рядок вивести в цій граматиці. Коротше кажучи - породжуючі це "згори вниз", а розпізнавальні - "знизу вгору". Остання задача є більш практичною і гострою.
Розпізнавання мови.(38)
Синтез мови за текстом.(39)
В настоящее время синтез речи по тексту можно применить во многих
областях, например мультимедийных обучающих системах, общение| с
информационными системами на естественном языке.
В системах синтеза речи по тексту применяются три основных метода
синтеза речевых сигналов: форматный синтез, синтез на основе коэффициентов линейного предсказания (ЛПК-синтез) и конкатенативный синтез.
Формантный синтез и ЛПК-синтез опираются на модель речеобразования
человека. В этом случае образование звуков речи представляется как результат прохождения сигнала источника возбуждения через модель речевого тракта. При формирование гласных звуков источник возбуждения формирует импульсы, частота следования которых (частота основного тона Fo) непрерывно изменяется в соответствии с мелодикой речи. Модель речевого тракта реализуется в виде цифрового фильтра с управляемыми параметрами. Возбуждение цифрового фильтра импульсным источником приводит к формированию гласных звуков.
Спектр гласных звуков xapактеризуется рядом максимумов, соответствующих резонансным свойств голосового тракта. Частоты максимумов называют формантными частотами. Глухие звуки формируются при прохождении через управляемый цифровой фильтр сигнала источника шума. Параметры фильтра могут определяться либо формантными частотами, либо ЛПК-коэффициентами. В первом случае получают формантный синтезатор, а во втором — ЛПК-синтезатор.
Хорошее обоснование ЛПК-модели речеобразования позволили применить
ее в задачи синтеза речи по тексту. При этом имеется возможность согласования звуков по энергии, по темпу, по частоте основного тона. Однако лучшие результаты в отношении разборчивости и натуральности звучания речи удается получить с помощью конкатенативного метода синтеза (от англ, concatenate — сцеплять, сглаживать).
Наибольшее распространение получили системы диффонного
конкатенативного синтеза. Диффоном называют участок речи, расположенный между центрами двух соседних фонем. Диффон содержит переходные элементы речи от одной фонемы к другой, что обеспечивает при синтезе речи её высокую натуральность. Кроме этого, благодаря тому, что границы диффонов сooтветствуют серединам фонем, где спектр наиболее стабилен, диффоны легко выделяются. При диффонном синтезе требуется запоминание большого числа диффонов (до нескольких тысяч). В ходе конкатенативного синтеза возникают две основные проблемы, во-первых, формирование речевого сигнала из сегментов, соответствующих диффонам, требует, устранения разрывов, возникающих на границах сегментов. Во-вторых, необходимо осуществлять такое независимое управление длительностью диффонов и частотой основного тона, чтобы сохранялись спектральные портреты формант. Если разрывы на границах сегментов устраняются путем обычного сглаживания, то управление длительностью диффонов и частотой основного тона требует специального
рассмотрения.

Рисунок 1 — Общая схема синтеза речи
В основе разрабатываемой системы синтеза речи лежит идея совмещения
метода конкатенации и синтеза по правилам. Метод конкатенации при адекватном наборе исходных элементов обеспечивает качественное воспроизведение спектральных характеристик речевого сигнала, а набор правил — возможность формирования естественного просодического оформления высказываний. Суть предлагаемого подхода заключается в том, что диффон разбивается на отрезки по 25 мс, каждый из них подвергается ЛПK -синтезу и производится запоминание этих ЛПК-коэффициентов. Предложенный метод синтеза обеспечивает простое управление просодическими характеристиками речи. Для этого применяется
известная схема ЛПК-синтезатора. Общая схема синтеза речи представлена на рисунке 1. Для того чтобы осуществить ЛПК синтезирование, необходимо по тексту построить транскрипцию, на основании которой формируются параметры синтезируемой речи — длительность, интенсивность, частота.
Для построения транскрипции используется экспертная подсистема. База
знаний экспертной подсистемы содержит набор правил, на основании которых осуществляется перевод орфографического текста в фонемную транскрипцию. 'Экспертная система с помощью машины вывода и набора правил осуществляет морфологический анализ орфографического текста. На основании этого происходит уточнение параметров отдельных фонем с учётом предшествующих и последующих фонем, то есть с учетом положения данного звука в предложении. Пусть на вход системы поступает:
Мо/й дя/дя са/мых че/стных пра/вил
База знаний экспертной системы содержит 1000 правил, которые подготовлены
на основании лингвистических исследований русских литераторов [1]. В
результате анализа слова “Мо/й” при выполнении:
- правило 1
если элем = й и пред = гл и последн = й то рез = i !
- правило 2
если элем = м и послед = о то рез = м !
получим “моi”
Слова “пред” “послед” и “последн” соответственно обозначают предыдущий
последующий и последний. Применим слова к остальным словам, получим Моi д``aд``a са`мы`х ч`jе^сны`х пра`в`и^л.
На основании добавочных и специальных символов (?, :, ^, ‘, j, i) и остальных
символов на выходе формируется фонетическое представление предложений текста с выделенными интонационно-смысловыми группами, их интонационными типами и уровнями ударений, которое затем применяется для определения просодических характеристик и поиска параметров звуковых элементов, из которых затем синтезируется речевой сигнал.
Для реализации комбинированного способа синтеза речи необходимо
создание базы данных параметров цифрового фильтра, используемого в данном методе. Этими параметрами являются массивы из ЛПК, каждый из которых соответствует конкретному диффону.
Суть создания этих массивов заключается в следующем: подготавливают
исходный текст, содержащий как можно большее количество диффонов, причем, они должны встречаться в тексте несколько раз. Данный текст записывается на магнитный носитель информации. Затем производится анализ полученного сигнала, в результате которого производят выделение всех встречаемых диффонов, длительность которых составит от 300-600 мс, и сохранение их в базе данных.
Выделенные диффоны разбиваются на п участков длительностью примерно 25 мс.
В дальнейшем производится ЛПК-анализ каждого участка, в результате чего
получают от 7 до 14 ЛПК. Полученные коэффициенты сохраняются в базе данных параметров, которые и будут использоваться в данном методе синтеза речи. Для получения наиболее достоверных характеристик, при повторном анализе уже изученных диффонов, полученные результаты сравниваются с предыдущими и производится усреднение соответствующих параметров.
В зависимости от количества диффонов, и числа соответствующих ЛПК,
хранимых в базе данных, объем памяти, необходимый для реализации данного метода будет составлять примерно 60 – 150 Кбайт.
Поняття про евристичний пошук.(40)
Евристичний алгоритм
Матеріал з Вікіпедії — вільної енциклопедії.
В інформатиці, евристичний алгоритм, або просто евристика, це алгоритм спроможний видати прийнятне рішення проблеми серед багатьох рішень, але неспроможний гарантувати, що це рішення буде найкращим. Отже такі алгоритми є приблизними і неточними. Зазвичай такі алгоритми знаходять рішення близьке до найкращого і роблять це швидко. Іноді такий алгоритм може бути точним, тобто він знаходить дійсно найкраще рішення, але він все одно буде називатися евристичним, доти доки не буде доведено, що рішення дійсно найкраще. Один з найвідоміших жадібний алгоритм, для того, щоб бути простим і швидким цей алгоритм ігнорує деякі вимоги задачі.
Дві фундаментальні цілі в інформатиці - знаходження алгоритмів з вірогідно найкращим часом виконання та з хорошою або оптимальною якістю. Евристичний алгоритм відмовляється від однієї або обох цих цілей; наприклад, він зазвичай знаходить дуже хороше рішення, але немає доказів, що рішення насправді не є поганим; або працює досить швидко, але не має гарантії, що він завжди видасть рішення.
Декілька евристичних методів використовуються антивірусним ПЗ для виявлення вірусів та іншого шкідливого ПЗ.
Часто, можна знайти таку задачу, що евристичний алгоритм буде працювати або дуже довго, або видавати невірні результати, однак, такі парадоксальні приклади можуть ніколи не зустрітись на практиці через свою специфічну структуру. Таким чином, використання евристики дуже поширене в реальному світі. Для багатьох практичних проблем евристичні алгоритми, можливо, єдиний шлях для отримання гарного рішення в прийнятний проміжок часу. Існує клас евристичних стратегій названих метаалгоритмами, котрі часто використовують, наприклад, випадковий пошук. Такі алгоритми можуть бути застосовані до широкого кола завдань, при цьому хороші характеристики не гарантуються.
«Жадібні» алгоритми, поняття. (41)
Жа́дібний алгори́тм — простий і прямолінійний евристичний алгоритм, який приймає найкраще рішення, виходячи з наявних на поточному етапі даних, не турбуючись про можливі наслідки, сподіваючись врешті-решт отримати оптимальне рішення. Легкий в реалізації і часто дуже ефективний за часом виконання. Багато задач не можуть бути розв'язані з його допомогою.
Наприклад, використання жадібної стратегії для задачі комівояжера породжує наступний алгоритм: «На кожному етапі вибирати найближче з невідвіданих міст».
Специфіка:
Зазвичай, жадібний алгоритм базується на п'яти принципах:
-
Набір можливих варіантів, з яких робиться вибір;
-
Функція вибору, за допомогою якої знаходиться найкращий варіант;
-
Функція придатності, яка визначає придатність отриманого набору;
-
Функція цілі, оцінює цінність рішення, не виражена явно;
-
Функція розв'язку, яка вказує на те, що знайдене кінцеве рішення.
Критерії застосування
Жадібний алгоритм добре розв'язує деякі задачі, а інші — ні. Більшість задач, для яких він спрацьовує добре, мають дві властивості: по-перше, до них можливо застосувати Принцип жадібного вибору, по-друге, вони мають властивість Оптимальної підструктури.
Принцип жадібного вибору
До оптимізаційної задачі можна застосувати принцип жадібного вибору, якщо послідовність локально оптимальних виборів дає глобально оптимальний розв'язок. В типовому випадку доведення оптимальності має таку схему: спочатку доводиться, що жадібний вибір на першому етапі не унеможливлює шлях до оптимального розв'язку: для всякого розв'язку є інше, узгоджене із жадібним і не гірше першого. Далі доводиться, що підзадача, що виникла після жадібного вибору на першому етапі, аналогічна початковій, і міркування закінчується за індукцією. Інакше кажучи, жадібний алгоритм ніколи не переглядає свої попередні вибори для здійснення наступного, на відміну від динамічного програмування.
Властивість оптимальної підструктури
«Задача має оптимальну підструктуру, якщо оптимальне рішення задачі містить оптимальне рішення для підзадач»[1]. Інакше кажучи, задача має оптимальну підструктуру, якщо кожен наступний крок веде до оптимального розв'язку. Прикладом 'неоптимальної підструктури' може бути ситуація в шахах, коли взяття ферзя (хороший наступний крок) веде до програшу партії в цілому.
Жадібні алгоритми можна характеризувати як 'короткозорі' і 'невідновлювані'. Вони ідеальні лише для задач з 'оптимальною підструктурою'. Незважаючи на це, жадібні алгоритми найкраще підходять для простих задач. Для багатьох інших задач жадібні алгоритми зазнають невдачі у продукуванні оптимального розв'язку, і можуть навіть видати найгірший з можливих розв'язків.
Алгоритм Харта, Нільсона, Рафаеля.(42)
Поиск A* (произносится «А звезда» или «А стар», от англ. A star) — в информатике и математике, алгоритм поиска по первому наилучшему совпадению на графе, который находит маршрут с наименьшей стоимостью от одной вершины (начальной) к другой (целевой, конечной).
Этот алгоритм был впервые описан в 1968 году Питером Хартом, Нильсом Нильсоном и Бертрамом Рафаэлем. Это по сути было расширение алгоритма Эдсгера Дейкстры, созданного в 1959 году. Он достигал более высокой производительности (по времени) с помощью эвристики. В их работе он упоминается как «алгоритм A». Но так как он вычисляет лучший маршрут для заданной эвристики, он был назван A*.
A* пошагово просматривает все пути, ведущие от начальной вершины в конечную, пока не найдёт минимальный. Как и все информированные алгоритмы поиска, он просматривает сначала те маршруты, которые «кажутся» ведущими к цели. От жадного алгоритма (который тоже является алгоритмом поиска по первому лучшему совпадению) его отличает то, что при выборе вершины он учитывает, помимо прочего, весь пройденный до неё путь (составляющая g(x) — это стоимость пути от начальной вершины, а не от предыдущей, как в жадном алгоритме). В начале работы просматриваются узлы, смежные с начальным; выбирается тот из них, который имеет минимальное значение f(x), после чего этот узел раскрывается. На каждом этапе алгоритм оперирует с множеством путей из начальной точки до всех ещё не раскрытых (листовых) вершин графа («множеством частных решений»), которое размещается в очереди с приоритетом. Приоритет пути определяется по значению f(x) = g(x) + h(x). Алгоритм продолжает свою работу до тех пор, пока значение f(x) целевой вершины не окажется меньшим, чем любое значение в очереди (либо пока всё дерево не будет просмотрено). Из множественных решений выбирается решение с наименьшей стоимостью.
Чем меньше эвристика h(x), тем больше приоритет (поэтому для реализации очереди можно использовать сортирующие деревья).
Код MatLab
function A*(start,goal)
% множество уже пройденных вершин
var closed := the empty set
% множество частных решений
var q := make_queue(path(start))
while q is not empty
var p := remove_first(q)
var x := the last node of p
if x in closed
continue
if x = goal
return p
add x to closed
% добавляем смежные вершины
foreach y in successors(x)
enqueue(q, p, y)
return failure
Представлення генетичної інформації.(43)
Из школьного курса биологии известно, что хромосомный материал представляет собой
последовательность комбинаций четырех нуклеотидов:
• А — аденин;
• Ц — цитозин;
• Т — тимин;
• Г — гуанин.
В генетических алгоритмах вектора переменных также записывают в виде цепочек симво-лов. Обычно используются достаточно бедные алфавиты. Наиболее часто используются бинарный алфавит — проще реализация алгоритмов.Будем считать, что каждая переменная х представлена фрагментом хромосомы, состоя-щим из фиксированного количества генов. В любой позиции фрагмента может стоять как ноль, так и единица. Рядом стоящие фрагменты не отделяют друг от друга какими-либомаркерами.Важно заметить, (и заметить именно тут), что фенотип однозначно определя-ется генотипом, а не наоборот. Таким образом наше «кодирование» является первичным по отношению к фенотипу. Для приведения генетической информации из бинарной формы к десятичному виду под-ходит любой двоично-десятичный код, но обычно исходят из того, что она представлена в коде Грея. От кода Грея переходим к двоично-десятичному коду, а от него — к натуральным целым числам. Код Грея обладает интересным свойством: соседние числа в двоичном представлении отличаются ровно на символ. Это очень важно для поиска опти-мальной точки. В таком представлении поиск происходит быстрее и реже «сваливается»в локальные экстремумы.
Двоичное кодирование Кодирование по коду Грея
десятичное двоичное шестнадцатеричное десятичное двоичное шестнадцатеричное
0 000 0h 0 0000 0h
1 0001 1h 1 0001 1h
2 0010 2h 3 0011 3h
3 0011 3h 2 0010 2h
4 0100 4h 6 0110 6h
5 0101 5h 7 0111 7h
6 0110 6h 5 0101 5h
7 0111 7h 4 0100 4h
8 1000 8h 12 1100 Ch
9 1001 9h 13 1101 Dh
10 1010 Ah 15 1111 Fh
11 1011 Bh 14 1110 Eh
12 1100 Ch 10 1010 Ah
13 1101 Dh 11 1011 Bh
14 1110 Eh 9 1001 9h
15 1111 Fh 8 1000 8h
Если привлечь геометрические интерпретации Код Грея гарантирует, что две соседние, принадлежащие одному ребру, вершины гиперкуба, на котором осуществляется поиск, всегда декодируются в две ближайшие точки пространства вещественных чисел отстоящие друг от друга на одну единицу точности. Двоично-десятичный код подобным свойством не обладает.
Генетичні оператори, мутації.(44)
Применение генетических операторов к хромосомам, отобранным с помощью селекции, приводит к формированию новой популяции потомков от созданной на предыдущем шаге родительской популяции.
В классическом генетическом алгоритме применяются два основных генетических оператора: оператор скрещивания (crossover) и оператор мутации (mutation). Однако следует отметить, что оператор мутации играет явно второстепенную роль по сравнению с оператором скрещивания. Это означает, что скрещивание в классическом генетическом алгоритме производится практически всегда, тогда как мутация - достаточно редко. Вероятность скрещивания, как правило, достаточно велика (обычно 0,5 ≤ рс ≤ 1), тогда как вероятность мутации устанавливается весьма малой (чаще всего 0 ≤ рm ≤ 0,1). Это следует из аналогии с миром живых организмов, где мутации происходят чрезвычайно редко.
В генетическом алгоритме мутация хромосом может выполняться на популяции родителей перед скрещиванием либо на популяции потомков, образованных в результате скрещивания.
Оператор скрещивания.
На первом этапе скрещивания выбираются пары хромосом из родительской популяции (родительского пула). Это временная популяция, состоящая из хромосом, отобранных в результате селекции и предназначенных для дальнейших преобразований операторами скрещивания и мутации с целью формирования новой популяции потомков. На данном этапе хромосомы из родительской популяции объединяются в пары. Это производится случайным способом в соответствии с вероятностью скрещивания рс. Далее для каждой пары отобранных таким образом родителей разыгрывается позиция гена (локус) в хромосоме, определяющая так называемую точку скрещивания. Если хромосома каждого из родителей состоит из L генов, то очевидно, что точка скрещивания lk представляет собой натуральное число, меньшее L. Поэтому фиксация точки скрещивания сводится к случайному выбору числа из интервала [1, L - 1]. В результате скрещивания пары родительских хромосом получается следующая пара потомков:
1) Потомок, хромосома которого на позициях от 1 до lk состоит из генов первого родителя, а на позициях от k + 1 до L - из генов второго родителя;
2) Потомок, хромосома которого на позициях от 1 до k состоит из генов второго родителя, а на позициях от lk + 1 до L - из генов первого родителя.
Как бы то нибыло, с уверенностью можно сказать лишь одно - опыты показывают необходимость присутствия обоих механизмов в алгоритме. При этом В большенстве экспериментов оператор мутации применяется к потомку с заданной вероятностью, причем величина вероятности выбирается давольно малой - порядка 0,01.
Необходимо также сказать, что в основном все операторы мутации сводятся к инвертированию одного или нескольких ген потомка. Это справедливо только для бинарного кодирования хромосом. В случае других способов кодирования мутация гена требует либо случайного выбора из заданного множества вариантов (случай алфавитного кодирования) либо специальных алгоритмов.
Оператор мутации с вероятностью рт изменяет значение гена в хромосоме на любое другое возможное значение. Например, если в хромосоме [100110101010] мутации подвергается ген на позиции 7, то его значение, равное 1, изменяется на 0. что приводит к образованию хромосомы [100110001010]. Как уже упоминалось выше, вероятность мутации обычно очень мала, и именно от нее зависит, будет данный ген мутировать или нет. Вероятность рт мутации может эмулироваться, например, случайным выбором числа из интервала [0, 1] для каждого гена и отбором для выполнения этой операции тех генов, для которых разыгранное число оказывается меньшим или равным значению рт.
Одноточечная мутация
В этом варианте оператора мутации в потомке случайно выбирается один ген и мутируется. П
Плотность мутации
Стратегия мутации с использованием понятия "плотности" заключается в мутировании каждого гена потомка с заданной вероятностью. Таким образом, кроме вероятности применения мутации к самому потомку используется еще вероятность применения мутации к каждому его гену, величину которой выбирают с таким расчетом, чтобы в среднем мутировало от 1 до 10 процентов ген.
Инцест
как механизм самоадаптации оператора мутации. Она заключается в том, что "плотность мутации" (вероятность мутации каждого гена) определяется для каждого потомка на основании генетической близости его родителей. Например, это может быть отношение числа совпадающих ген родителей к общему числу ген хромосомы. Это приводит к очень интересному эффекту - при высоком разнообразии генофонда пополяции (первые шаги ГА) последствия мутации будут минимальными, что позволяет репродукции работать без стороннего вмешательства. В случае же понижения разнообразия, что возникает в основном при застревании алгоритма в локальном оптимуме, последствия мутации становятся более ощутимыми, а при полном схождении популяции алгоритм просто становится стахостическим, что увеличивает вероятность выхода популяции из локального оптимума. ПОЗИЦИОНИРОВАНИЕ
Фитнес-функция
Тут нужно обратить внимание что фитнес-функция это пожалуй наиболее важная (или одна из) деталь ГА. Здесь нужно выделить 3 главных момента:
Функция оценки должны быть адекватна задаче. фитнесс функция всегда должна стремиться удовлетворить условие, что для всех решений X выполняется F(X1) Фитнес-функция должна иметь рельеф. Мало того, рельеф должен быть разнообразным. Это означает, что ГА имеет мало шансов на успех, если на поверхности фитнес-функции есть огромные "плоские" участки - это приводит к тому, что многие (или, что хуже, все) решения в популяции при различии в генотипе не будут отличаться фенотипом, тоесть, не смотря на то что решения различаются, они имеют одинаковую оценку, а значит алгоритм не имеет возможности выбрать лучшее решение, выбрать направление дальнейшего развития. Эта проблема еще упоминается как "проблема поля для гольфа", где всё пространство абсолютно одинаково, за исключением лишь одной точки, которая и является оптимальным решением - в этом случае алгоритм просто остановится или будет блуждать абсолютно случайно.
Фитнес-функция должна требовать минимум ресурсов. Т.к. это наиболее часто используемая деталь алгоритма, она имеет существенное влияние на его скорость работы.
Переважне правило розмноження найсильніших.(45)
способи представлення генетичної інфомарції.(46)
Из школьного курса биологии известно, что хромосомный материал представляет собой
последовательность комбинаций четырех нуклеотидов:
• А — аденин;
• Ц — цитозин;
• Т — тимин;
• Г — гуанин.
В генетических алгоритмах вектора переменных также записывают в виде цепочек симво-лов. Обычно используются достаточно бедные алфавиты. Наиболее часто используются бинарный алфавит — проще реализация алгоритмов.Будем считать, что каждая переменная х представлена фрагментом хромосомы, состоя-щим из фиксированного количества генов. В любой позиции фрагмента может стоять как ноль, так и единица. Рядом стоящие фрагменты не отделяют друг от друга какими-либомаркерами.Важно заметить, (и заметить именно тут), что фенотип однозначно определя-ется генотипом, а не наоборот. Таким образом наше «кодирование» является первичным по отношению к фенотипу. Для приведения генетической информации из бинарной формы к десятичному виду под-ходит любой двоично-десятичный код, но обычно исходят из того, что она представлена в коде Грея. От кода Грея переходим к двоично-десятичному коду, а от него — к натуральным целым числам. Код Грея обладает интересным свойством: соседние числа в двоичном представлении отличаются ровно на символ. Это очень важно для поиска опти-мальной точки. В таком представлении поиск происходит быстрее и реже «сваливается»в локальные экстремумы.
Двоичное кодирование Кодирование по коду Грея
десятичное двоичное шестнадцатеричное десятичное двоичное шестнадцатеричное
0 000 0h 0 0000 0h
1 0001 1h 1 0001 1h
2 0010 2h 3 0011 3h
3 0011 3h 2 0010 2h
4 0100 4h 6 0110 6h
5 0101 5h 7 0111 7h
6 0110 6h 5 0101 5h
7 0111 7h 4 0100 4h
8 1000 8h 12 1100 Ch
9 1001 9h 13 1101 Dh
10 1010 Ah 15 1111 Fh
11 1011 Bh 14 1110 Eh
12 1100 Ch 10 1010 Ah
13 1101 Dh 11 1011 Bh
14 1110 Eh 9 1001 9h
15 1111 Fh 8 1000 8h
Если привлечь геометрические интерпретации Код Грея гарантирует, что две соседние, принадлежащие одному ребру, вершины гиперкуба, на котором осуществляется поиск, всегда декодируются в две ближайшие точки пространства вещественных чисел отстоящие друг от друга на одну единицу точности. Двоично-десятичный код подобным свойством не обладает.
Генетичний алгоритм.(47)
Классический генетический алгоритм.
Основной (классический) генетический алгоритм (также называемый элементарным или простым генетическим алгоритмом) состоит из следующих шагов:
1) Инициализация, или выбор исходной популяции хромосом;
2) Оценка приспособленности хромосом в популяции;
3) Проверка условия остановки алгоритма;
4) Селекция хромосом;
5) Применение генетических операторов;
6) Формирование новой популяции;
7) Выбор “наилучшей” хромосомы.
Инициализация, т.е. формирование исходной популяции, заключается в случайном выборе заданного количества хромосом (особей), представляемых двоичными последовательностями фиксированной длины
Оценивание приспособленности хромосом в популяции состоит в расчете функции приспособленности для каждой хромосомы этой популяции. Чем больше значение этой функции, тем выше «качество» хромосомы.
Проверка условия остановки алгоритма. Определение условия остановки генетического алгоритма зависит от его конкретного применения. В оптимизационных задачах, если известно максимальное (или минимальное) значение функции приспособленности, то остановка алгоритма может произойти после достижения ожидаемого оптимального значения, возможно - с заданной точностью. Остановка алгоритма также может произойти в случае, когда его выполнение не приводит к улучшению уже достигнутого значения. Алгоритм может быть остановлен по истечении определенного времени выполнения либо после выполнения заданного количества итераций
Селекция хромосом заключается в выборе (по рассчитанным на втором этапе значениям функции приспособленности) тех хромосом, которые будут участвовать в создании потомков для следующей популяции, т.е. для очередного поколения.
Применение генетических операторов к хромосомам, отобранным с помощью селекции, приводит к формированию новой популяции потомков от созданной на предыдущем шаге родительской популяции.
Формирование новой популяции.
Хромосомы, полученные в результате применения генетических операторов к хромосомам временной родительской популяции, включаются в состав новой популяции. Она становится так называемой текущей популяцией для данной итерации генетического алгоритма.
Выбор “наилучшей” хромосомы.
Если условие остановки алгоритма выполнено, то следует вывести результат работы, т.е. представить искомое решение задачи. Лучшим решением считается хромосома с наибольшим значением функции приспособленности.

Умови створення початкової популяції.(48)
Перед першим кроком необхідно отримати з життя або випадковим чином створити деяку початкову популяцію. Навіть якщо популяція здасться зовсім не конкурентною, генетичний алгоритм все одно достатньо швидко переведе її в придатну для життя популяцію. Таким чином, на першому кроці можна не особливо старатися зробити надто вже пристосованих осіб, достатньо, щоб вони відповідали формату осіб популяції, і на них можна було вирахувати функції пристосованості (Fitness). Наслідком першого кроку є популяція H, що налічує N осіб.
