

2.2. Определение синтаксиса
В этом разделе для определения синтаксиса языка будет рассмотрен способ записи, называемый контекстно-свободной грамматикой (или, для краткости, просто грамматикой). Данный способ будет использоваться как часть спецификации предварительной стадии компилятора на протяжении всей книги.
Грамматика естественным образом описывает иерархическую структуру множества конструкций языка программирования. Например, инструкция if-else в С имеет вид
if (выражение) инструкция else инструкция
Таким образом, инструкция if-else представляет собой ключевое слово if, за которым следует открывающая круглая скобка, выражение, закрывающая скобка, инструкция, ключевое слово else и еще одна инструкция (в С нет ключевого слова then). Используя переменную ехрг для обозначения выражения и переменную stmt для обозначения инструкции, можно записать это структурное правило так:
stmt → if (ехрг) stmt else stmt (2.1)
Здесь символ (→) можно прочесть как "может иметь вид". Такое правило называется продукцией (production). В продукции лексические элементы вроде ключевого слова if и скобок называются токенами. Переменные типа ехрг и stmt представляют последовательности токенов6 и называются нетерминальными символами, или просто нетерминалами (nonterminals).
Контекстно-свободная грамматика имеет четыре компонента.
1. Множество токенов, представляющих собой терминальные символы (или просто терминалы).
2. Множество нетерминальных символов.
3. Множество продукций, каждая из которых состоит из нетерминала, называемого левой частью продукции, стрелки и последовательности токенов и/или нетерминалов, называемых правой частью продукции.
4. Указание одного из нетерминальных символов как стартового, или начального.
Следует придерживаться правила, согласно которому грамматика определяется перечислением ее продукций, причем первая продукция указывает стартовый символ. Цифры, знаки вроде <= и выделенные полужирным шрифтом слова типа while являются терминальными символами. Выделенные курсивом слова являются нетерминалами, а все слова или символы, поданные без выделения, могут рассматриваться как токены7. Для удобства записи правые части продукций с одними и теми же нетерминалами слева могут быть сгруппированы с помощью символа "|" ("или").
Пример 2.1
В примерах этой главы используются выражения, состоящие из цифр и знаков "плюс" и "минус", например 9-5+2, 3-1 или 7. Поскольку знаки "плюс" и "минус" должны располагаться между двумя цифрами, такие выражения можно рассматривать как списки цифр, разделенных знаками "плюс" и "минус". Синтаксис используемых выражений описывает грамматика из следующих продукций:
list → list + digit (2.2)
list → list - digit (2.3)
list → digit (2.4)
digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 (2.5)
Правые части трех продукций с нетерминалом list в левой части могут быть объединены:
list —> list + digit | list - digit | digit
Здесь, в соответствии с нашими соглашениями, токенами грамматики являются символы
+ - 0123456789
Нетерминальными символами являются выделенные курсивом имена list и digit, при этом нетерминал list — стартовый; именно его продукция дана первой. □
Продукция называется продукцией нетерминала, если он записан в левой части. Строка токенов является последовательностью из нуля или нескольких токенов. Строка, содержащая нуль токенов и записываемая как е, называется пустой.
Грамматика выводит, или порождает строки, начиная со стартового символа и неоднократно замещая нетерминалы правыми частями продукций этих нетерминалов. Строки токенов, порождаемые из стартового символа, образуют язык, определяемый грамматикой.
Пример 2.2
Язык, определяемый грамматикой из примера 2.1, состоит из списков цифр, разделенных знаками "плюс" и "минус".
Десять продукций для нетерминала digit позволяют ему быть любым из токенов О, 1, 9. Из продукции (2.4) следует, что список может состоять и из одной цифры, т.е. цифра сама по себе является списком. Продукции (2.2) и (2.3) выражают тот факт, что если мы возьмем любой список и добавим к нему знак "плюс" или "минус" с последующей цифрой, то получим новый список.
Оказывается, что продукции (2.2) - (2.5) — все, что надо для определения языка. Например, можно сделать вывод, что 9-5+2 является списком, следующим образом.
1. 9 — список в соответствии с продукцией (2.4), поскольку 9 — цифра.
2. 9-5 — список в соответствии с продукцией (2.3), так как 9 — список, а 5 — цифра.
3. 9-5+2— список в соответствии с продукцией (2.2), поскольку 9-5— список, а 2 — цифра.
Данное утверждение продемонстрируем деревом, представленным на рис. 2.2. Каждый узел дерева помечен символом грамматики. Внутренний узел и его дочерние узлы соответствуют продукции, причем узел соответствует левой части продукции, а потомки — правой. Такие деревья называются деревьями разбора (parse trees); они будут рассмотрены ниже. □
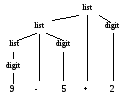
Рис. 2.2. Дерево разбора выражения 9-5+2 в соответствии с грамматикой из примера 2.1
Пример 2.3
Еще один пример списков — последовательность инструкций, разделенных точками с запятыми; такую последовательность можно найти в Pascal, в блоке begin-end. Однако между токенами begin и end может и не быть инструкций. Разработку грамматики для блока begin-end можно начать со следующих продукций:
block → begin opt stmts end
opt_stmts → stmt_list | ε
stmt_list → stmt_list; stmt | stmt
Заметьте, что правой частью для opt_stmts может являться е, т.е. пустая строка символов. Таким образом, opt_stmts может быть заменено пустой строкой, и блок может оказаться строкой из двух токенов begin end. Обратите также внимание, что продукции для stm_list аналогичны продукциям для list в примере 2.1 (точка с запятой вместо арифметической операции и с stmt вместо digit). В данном примере не представлены продукции для stmt, но далее вкратце будут рассмотрены продукции для различных инструкций, таких как инструкции присвоения, инструкции if и др. □
Деревья разбора
Дерево разбора наглядно показывает, как стартовый символ грамматики порождает строку языка. Если нетерминал А имеет продукцию A→XYZ, то дерево разбора может иметь внутренний узел А с тремя потомками, помеченными слева направо как X, Y и Z.

Формально для данной контекстно-свободной грамматики дерево разбора представляет собой дерево со следующими свойствами.
1. Корень дерева помечен стартовым символом.
2. Каждый лист помечен токеном или е.
3. Каждый внутренний узел представляет нетерминальный символ.
4. Если А является нетерминалом и помечает некоторый внутренний узел, а Х1 Х2,
Хn — отметки его дочерних узлов, перечисленные слева направо, то А → Х1 Хг ... Хn — продукция. Здесь X1, Х2, … , Хn могут представлять собой как терминальные, так и нетерминальные символы. В качестве специального случая продукции А → ε соответствует узел А с единственным дочерним узлом ε.
Пример 2.4
На рис. 2.2 корневой узел помечен нетерминалом list, стартовым символом грамматики из примера 2.1. Дочерние узлы имеют отметки list, + и digit. Заметьте, что
list → list + digit
является продукцией грамматики из примера 2.1. К левому дочернему узлу применен тот же шаблон, со знаком "минус" вместо знака "плюс". Все три узла, помеченные как digit, имеют по одному дочернему узлу с метками-цифрами. □
Листья дерева разбора, читаемые слева направо, образуют крону (yield) дерева, которая представляет собой строку, выведенную, или порожденную из нетерминального символа в корне дерева. На рис. 2.2 порожденная строка — 9–5+2. Здесь все листья показаны на одном, нижнем, уровне; в дальнейшем выравнивать листья деревьев таким образом не будем. Они должны рассматриваться в определенном порядке слева направо: если а и b — два дочерних узла одного родителя и узел а находится слева от b, то все потомки а будут находиться слева от любого потомка b.
Другое определение языка, порожденного грамматикой, — это множество строк, которые могут быть сгенерированы некоторым деревом разбора. Процесс поиска дерева разбора для данной строки токенов называется разбором, или синтаксическим анализом этой строки.
Неоднозначность
Будьте предельно внимательны при рассмотрении структуры строки, соответствующей грамматике. Очевидно, что каждое дерево порождает единственную строку (путем считывания листьев этого дерева), однако для данной строки токенов грамматика может иметь более одного дерева. Такая грамматика называется неоднозначной. Чтобы убедиться в ее неоднозначности, достаточно найти строку токенов, которая имеет более одного дерева разбора. Поскольку такая строка обычно имеет не единственный смысл, следует использовать либо однозначные (непротиворечивые), либо неоднозначные грамматики с дополнительными правилами для разрешения неоднозначностей.
Пример 2.5
Предположим, что цифры и списки в примере 2.1 не различаются. Тогда грамматику можно записать следующим образом.
string → string + string | string - string |0|1|2|3|4|5|6|7|8|9
Объединение записей для digit и list в один нетерминальный символ string имеет кажущийся смысл, поскольку отдельная цифра является специальным случаем списка.
Однако из рис. 2.3 видно, что выражение типа 9–5+2 теперь имеет больше одного дерева разбора. В данном случае два дерева разбора соответствуют двум вариантам расстановки скобок в выражении: (9-5)+2 и 9-(5+2). Это второе выражение дает в результате значение 2 вместо обычного 6. Грамматика в примере 2.1 не допускает такой интерпретации. □
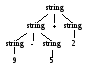
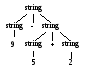
Рис. 2.3. Два дерева разбора для выражения 9-5+2
Ассоциативность операторов
По соглашению 9+5+2 эквивалентно (9+5)+2, а 9-5-2 эквивалентно (9-5)-2. Когда операнд типа 5 имеет операторы и слева, и справа, необходимо установить, какой именно оператор использует этот операнд. Мы говорим, что оператор + левоассоциативен, поскольку операнд со знаками "плюс" с обеих сторон используется левым оператором. В большинстве языков программирования четыре арифметических оператора — сложение, вычитание, умножение и деление — левоассоциативны.
Некоторые распространенные операторы, например возведение в степень, правоассоциативны. Другим примером правоассоциативного оператора может служить оператор присвоения (=) в С, где выражение а=b=с трактуется как а= (b=с).
Строки типа а=b=с с правоассоциативным оператором генерируются следующей грамматикой.
right → letter = right | letter
letter → a|b|…|z
Различия между деревьями разбора для левоассоциативных операторов типа "-" и правоассоциативных операторов вроде "=" показаны на рис. 2.4. Обратите внимание, что дерево разбора для 9-5-2 растет вниз влево, в то время как дерево разбора для а=b=с — вниз вправо.
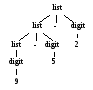
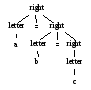
Рис. 2.4. Деревья разбора для лево- и правоассоциативных операторов
1 В настоящее время наличие языка структурированных запросов SQL снимает вопрос о том, является ли интерпретация запросов задачей, всего лишь схожей с компиляцией. — Прим. перев.
2 Здесь следует обратить внимание на перевод термина statement. Дословно statement означает высказывание, утверждение, однако в применении к компьютерной тематике это не совсем удачно. Обычно при переводе используется термин оператор, но в данной книге, посвященной формальным языкам, этот термин имеет собственное значение. Поэтому при переводе термина statement за редкими исключениями было использовано понятие инструкция — как наиболее близкое по смыслу, так и уже используемое при описании языка, например, в книге Б. Страуструп. Язык программирования С++, 3-е изд. — СПб.; М.: "НевскийДиалект"— "ИздательствоБИНОМ", 1999. — Прим. перев.
3 Следует упомянуть о важности вопроса выделения памяти для размещения идентификаторов исходной программы. Как мы увидим в главе 7, "Среды времени исполнения", распределение памяти в процессе работы зависит от компилируемого языка. Принятие решения о выделении памяти происходит либо в процессе создания промежуточного кода, либо при генерации целевого кода.
4 "Почти произвольные" строки, поскольку производится только простое сканирование макроса. Как только при сканировании находится символ, соответствующий тексту, следующему после #i в шаблоне, сканированная строка считается соответствующей формальному параметру #i. Таким образом, если мы попытаемся подставить ab; cd вместо #1, обнаружим, что параметру #1 соответствует строка ab, а параметру #2 — строка cd.
5 Slanted — наклоненный. — Прим. перев.
6 Вообше говоря, нетерминал представляет множество последовательностей токенов. — Прим. ред.
7 Отдельные символы, выделенные курсивом, будут использоваться и для других целей при детальном изучении грамматики в главе 4, "Синтаксический анализ". Например, они будут применяться при указании символов, которые могут представлять собой либо токены, либо нетерминалы. Однако выделенное курсивом имя из двух или более символов будет всегда означать нетерминал.