

Формирование данных
Классификация данных:
-
Cross-section data - не важен порядок данных
-
Временные ряды - порядок существеннен
-
Panel data (t - время, i - номер экономической единицы)
Последний вид данных был впервые применен в связи с исследованием данных по безработице (Мичиган, 1968).
Если абстрагироваться от панели, то возможный вариант модели:
![]() ,
,
Наличие панельной структуры позволяет выделить индивидуальные особенности объекта.
Пример макромодели.
ВВП по 50 странам за один год - cross-section. Получили зависимость, но в этом случае все объекты полагаются однородными. Как правило особенности объектов не измеряемы или не наблюдаемы (усторические, культурные и пр. факторы). Они являются постоянными по времени, но различными по странам (объектам).
Модели более реалистичны.
Пример.
Потребление продукта или услуг. Допустим, проведено исследование, потребление выросло, но ничего нельзя сказать о характере возрастания. Например, у каких то групп оно выросло, у других осталось на прежнем уровне. Так как исследуемые объекты, как правило, различны.
Пример.
(1973, Ben-Porah)
Участие женщин в рынке труда. Приблизительно 50 % женщин работают. Означает, что случайная женщина может работать или нет, либо одна работает, а другая - нет. В первом случае присутствует циркуляция рынка, во втором - отсутствует. На основе панельных данных можно ответить на вопрос об устройстве рынка труда.
Итак, панельные данные дают возможность учитывать индивидуальные отличия объектов.
Техническое удобство данных - больше наблюдений. Практически изчезает проблема мультиколлинеарности.
Рассмотрим
![]() ,
допустим индивидуальный эффект сильно
коррелирует с x.
Имеем модель:
,
допустим индивидуальный эффект сильно
коррелирует с x.
Имеем модель:
![]() ,
,
здесь
![]() - индивидуальный показатель каждого
объекта, не зависящий от времени.
- индивидуальный показатель каждого
объекта, не зависящий от времени.
Пример.
Оценка произодственной функции. При традиционном подходе используем функцию Кобба-Дугласа. В небольших фирмах существенное влияние оказывает качество управления фрмы, но этот фактор связан с другими производственными. Тогда эластичность оценивается более точно.
Можно
считать, что индивидуальный эффект
имеет различную природу. Будем полагать,
что ошибки
![]() устроены как в стандартной классической
модели.
устроены как в стандартной классической
модели.
![]()
![]() -
некоррелированы.
-
некоррелированы.
Если
не учитывать
![]() ,
то модель обычная. Введем обозначения:
,
то модель обычная. Введем обозначения:
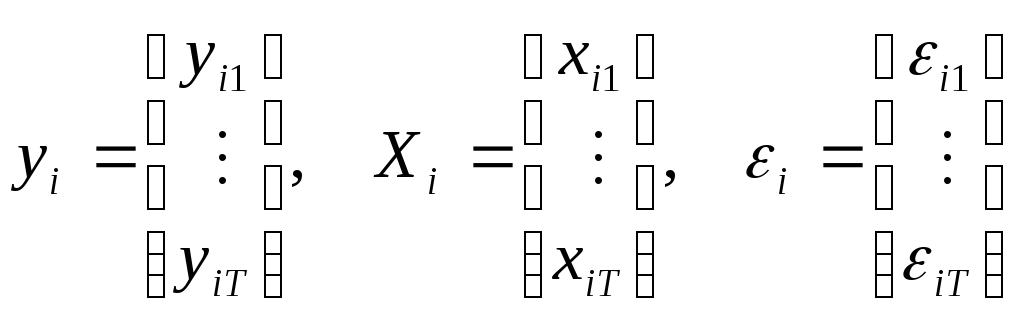 .
.
Получаем объединенную модель (Pulled).
![]() .
.
Введя дополнительные обозначения:
 ,
,
получим стандартную модель:
![]() .
.
Переходим к модели м индивидуальным эффектом:
-
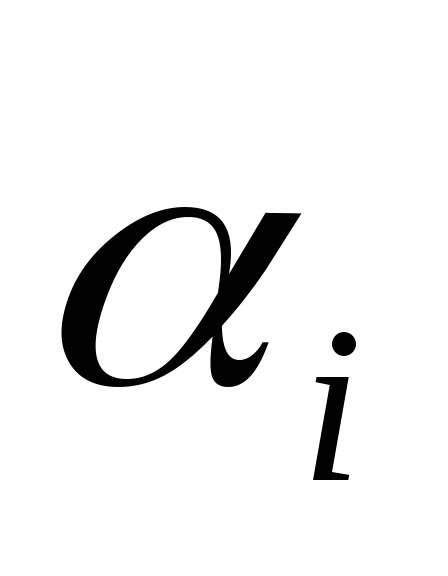 может
носить случайный характер, если объекты
из большой совокупности выбраны
случайным образом. Например, домашние
хозяйства.
может
носить случайный характер, если объекты
из большой совокупности выбраны
случайным образом. Например, домашние
хозяйства. -
Не случайны, если, например, модель по странам с развитой экономикой.
Тогда в первом случае модель называется моделью со случайным эффектом (Random effect model), а во втором - модель с фиксированным эффектом (fixed effect model).
Модель с фиксированным эффектом
Число
![]() растет с увеличением количества объектов.
Если число параметров растет с числом
наблюдений, оценки получаются
несостоятельными. Кроме того, возникают
вычислительные сложности.
растет с увеличением количества объектов.
Если число параметров растет с числом
наблюдений, оценки получаются
несостоятельными. Кроме того, возникают
вычислительные сложности.
Можно ввести dummy переменные для каждой фирмы (предприятия, страны).
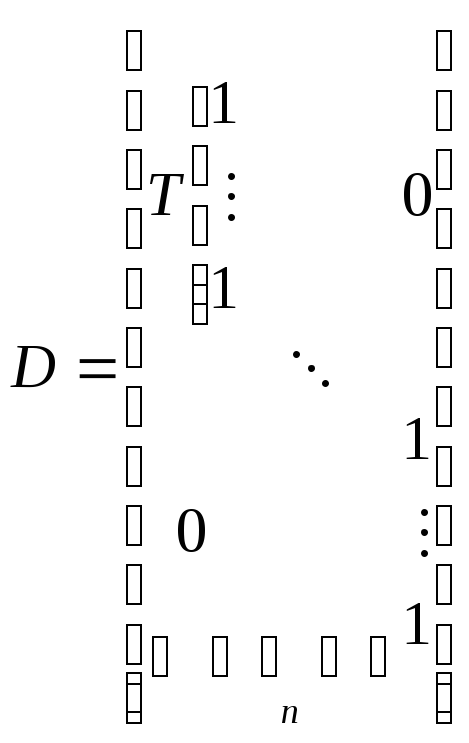 .
.
Для
удобства будем использовать матричные
произведения Кронеккера. Тогда в тех
же обозначениях можно записать:
![]() .
Эта модель оценивается при помощи LSDV
(Less Square Dummy Variables).
.
Эта модель оценивается при помощи LSDV
(Less Square Dummy Variables).
Предполагается, что в этой модели в X нет константы. Обобщение модели по объединенным данным.
Реально параметры оценить нельзя, слишком много вычислений.
Если же число объектов фиксировано, а растет только временной интервал, то можно ожидать состоятельность оценок, реально же таких данных нет.
Если
ввести
![]() - выборочное осреднение, в данном случае
по времени, то для каждого фактора можно
провести группирововчные преобразования:
- выборочное осреднение, в данном случае
по времени, то для каждого фактора можно
провести группирововчные преобразования:
![]() .
.
Оценки получим состоятельные. Оценки называются Within estimator (внутригрупповые оценки).
Для обработки панельных данных удобна Stata. Второе название fixed effect estimator.
Возникают
сложности при учете пола, расовой
принадлежности. Так как эти праметры
станут нуле. Оценка
![]() при меняющихся во времени X.
при меняющихся во времени X.
После
нахождения
![]() усредняются по количеству наблюдений
усредняются по количеству наблюдений
![]() .
.
Очень часто оценки по методу наименьших квадратов и такие усредненные сильно отличаются.
Пример.
В США было проведено исследование, где в качестве зависимой переменной были взяты расходы семьи на зубную пасту. Собрали панельные данные, включили доход семьи и некоторые демографические признаки. Сделали обединенную модель, получилась положительная зависимость.
После оценки с помощью FEM оказалось, что значимой зависимости нет.