

9.9.3 Замена наследуемых атрибутов синтезируемыми
Иногда можно избежать использования наследуемых атрибутов путем изменения грамматики.
Например, объявление в PASCAL может состоять из списка идентификаторов, за которым следует тип: m, n: integer;
Грамматика такого объявления может включать продукции вида:
D –> L:T
T –> integer / char
L -> L, id / id
Поскольку идентификаторы порождаются L, но тип в поддереве L не содержится, нельзя связать тип с идентификатором с помощью только синтезируемых атрибутов. Если нетерминал L наследует тип от Т, то получается СУ-определение не являющееся L-атрибутным, так что трансляция на его основе не может быть выполнена в процессе синтаксического анализа.
Решение этой проблемы состоит в реструктуризации грамматики для включения типа в качестве последнего элемента в список идентификаторов.
D –> id L
L -> , id L / : T
T –> integer / char
Теперь тип может рассматриваться как синтезируемый атрибут L.type, и в таблицу символов можно внести тип каждого идентификатора, порождаемого L.
9.9.4 Память для значений атрибутов во время компиляции
При заданном порядке вычисления атрибутов время жизни атрибута начинается, когда атрибут впервые вычисляется, и заканчивается, когда вычислены все атрибуты, зависящие от него. Можно сэкономить память, сохраняя значения атрибутов только на протяжении их времени жизни.
Рассмотрим не являющееся L-атрибутным синтаксически управляемое определение, предназначенное для передачи информации о типе идентификаторам в объявлении.
Пример 40
Синтаксически управляемое определение на рис. 63 представляет собой объявления вида
real с[12] [31]; (а)
int х[3], у[5]; (б)
Дерево разбора для (б) показано на рис. 64(а) пунктирными линиями. Тип, полученный из Т, наследуется L и передается вниз идентификаторам в объявлении. Дуга от T.type к L.in показывает, что L.in зависит от Т.type. Синтаксически управляемое определение на рис. 63 не является L-атрибутным, поскольку I1.in зависит от num.val, а num располагается справа от I1, в I → I1, [num].
|
Продукция |
Правила |
|
D →TL |
L.in := T.type |
|
T → int |
T.type := integer |
|
Т → real |
T.type := real |
|
L → L1,I |
L1.in := L.in |
|
|
l.in := L.in |
|
L → I |
l.in := L.in |
|
I → I1 [num] |
I1.in := array(num.val, l.in) |
|
I → id |
addtype{id.entry, I.in) |
Рис. 63. Передача типа идентификаторам в объявлении
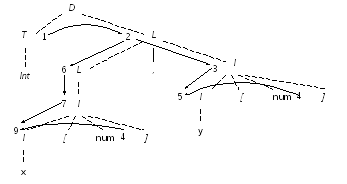
а) Граф зависимости для дерева разбора

б) Узлы в порядке вычисления (а)
Рис. 64. Определение времени жизни значений атрибутов