

5.2 Роль синтаксического анализатора
В модели компилятора синтаксический анализатор получает строку лексем с выхода лексического анализатора, как показано на рис. 21, и проверяет, может ли эта строка порождаться грамматикой исходного языка. Он также сообщает обо всех выявленных ошибках. Кроме того, он должен уметь обрабатывать обычно часто встречающиеся ошибки и продолжать работу с оставшейся частью программы.
Дерево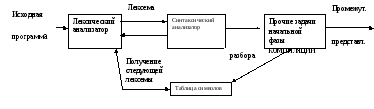
Рис. 21. Место синтаксического анализатора в модели компилятора
Имеется три основных типа синтаксических анализаторов грамматик.
-
Универсальные методы разбора, такие как алгоритмы Кока-Янгера-Касами или Эрли, могут работать с любой грамматикой. Однако эти методы слишком неэффективны для использования в промышленных компиляторах.
-
Нисходящие (сверху вниз) методы синтаксического анализа. Нисходящие синтаксические анализаторы строят дерево разбора сверху (от корня) вниз (к листьям). Входной поток синтаксического анализатора сканируется посимвольно слева направо.
-
Восходящие (снизу вверх) методы синтаксического анализа. Восходящие методы начинают построение дерева разбора с листьев и идут к корню. Входной поток также сканируется посимвольно слева направо.
Восходящие и нисходящие методы синтаксического анализа наиболее распространены в компиляторах.
Наиболее эффективные нисходящие и восходящие методы работают только с подклассами грамматик, однако некоторые из этих подклассов, такие как LL- и LR-грамматики, достаточно выразительны для описания большинства синтаксических конструкций языков программирования. Реализованные вручную синтаксические анализа-торы чаще работают с LL-грамматиками. Синтаксические анализаторы для несколько большего класса LR-грамматик обычно создаются с помощью автоматизированных инструментов.
Выходом синтаксического анализатора является некоторое представление дерева разбора входного потока лексем, выданного лексическим анализатором. На практике имеется множество задач, которые могут сопровождать процесс разбора, - например, сбор информации о различных лексемах в таблице символов, исполнение проверки типов и других видов семантического анализа, а также создание промежуточного кода.
5.3 Обработка синтаксических ошибок
Если компилятор будет иметь дело исключительно с корректными программами, его разработка и реализация существенно упрощаются. Однако программисты пишут программы с ошибками, и хороший компилятор должен помочь программисту обнаружить их и локализовать. Большинство спецификаций языков программирования не определяет реакции компилятора на ошибки - этот вопрос отдается на откуп разработчикам компилятора. Однако планирование системы обработки ошибок с самого начала работы над компилятором может, как упростить его структуру, так и улучшить его реакцию на ошибки.
Любая программа потенциально содержит множество ошибок самого разного уровня. Например, ошибки могут быть
-
лексическими, такими как неверно записанные идентификаторы, ключевые слова или операторы;
-
синтаксическими, например арифметические выражения с несбалансированными скобками;
-
семантическими, такими как операторы, применяемые к несовместимым с ними операндам;
-
логическими, например бесконечная рекурсия.
Основные действия по выявлению ошибок и восстановлению после них решаются на этапе синтаксического анализа. Одна из причин этого состоит в том, что многие ошибки по природе своей являются синтаксическими или проявляются, когда поток лексем, идущий от лексического анализатора, нарушает определяющие язык программирования грамматические правила. Вторая причина заключается в точности современных методов разбора - они очень эффективно выявляют синтаксические ошибки в программе. Определение присутствия в программе семантических или логических ошибок - задача более сложная.
Обработчик ошибок синтаксического анализатора имеет очень просто формулируемые цели:
-
он должен ясно и точно сообщать о наличии ошибок;
-
он должен обеспечивать быстрое восстановление после ошибки, чтобы продолжить поиск последующих ошибок.