

Данные, полученные при обработке документов программой
FREE ONLINE OCR SERVICE
|
№ |
Количество слов |
Слов с ошибками (нет слов) |
Без ошибок |
Качество обработки % |
|
1 |
111 |
14 |
97 |
87,39 |
|
2 |
124 |
61 |
63 |
50,81 |
|
3 |
273 |
120 |
153 |
56,04 |
|
4 |
151 |
20 |
131 |
86,75 |
|
5 |
144 |
22 |
122 |
84,72 |
|
6 |
178 |
156 |
22 |
12,36 |
|
7 |
199 |
5 |
194 |
97,49 |
|
8 |
201 |
12 |
189 |
94,03 |
|
9 |
121 |
73 |
48 |
39,67 |
|
10 |
126 |
43 |
83 |
65,87 |
|
|
|
|
|
|
|
Среднее значение |
162,8 |
52,6 |
110,2 |
67,51 |
|
MIN |
111 |
5 |
22 |
12,36 |
|
MAX |
273 |
156 |
194 |
97,49 |
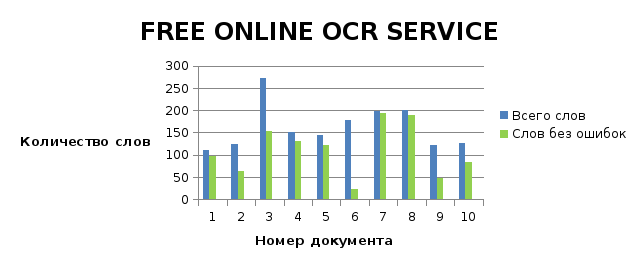
Рисунок 9. Соотношение слов без ошибок к общему количеству слов (обработано FREE ONLINE OCR SERVICE)
Исходя из полученных результатов, можно сделать вывод, что данный сервис имеет высокий уровень распознавания текста. В среднем, количество распознанных слов составляет 67,5 %. Данный сервис является хорошим способом быстро распознать графический файл и перевести его в текстовый формат, но для оптимизации реального бизнес-процесса данный продукт не подходит из-за узкого спектра функциональных возможностей.
Плюсы: простота в использовании, быстрый доступ с любого устройства с выходом в интернет, множество языков для распознавания.
Минусы: в отличие от загруженных программ для оптического распознавания текста, данный продукт не имеет таких широких функциональных возможностей.
CuneiForm – это программа, используемая для распознавания текста документов и дальнейшего перевода в редактируемый вид. Данный продукт бесплатный и доступный любому пользователю. В результате работы программы можно получить файл в нужном формате с отредактированным текстом.
Форматы выходных файлов в CuneiForm представлены на рисунке 10.

Рисунок 10. Поддерживаемые форматы в CuneiForm
Исходя из увиденного выше, делаем вывод, что данное ПО не поддерживает одни из основных форматов файлов, как Microsoft Word (расширение .doc) и Acrobat Reader DC (расширение .pdf). Следовательно, данный продукт будет проигрывать по широте использования тому же ABBYY FineReader 12. Но в этой дипломной работе как раз необходим текст исполнительного листа в формате .txt, поэтому сравним качество обработанного документа и вероятность некорректного перевода текста (Таблица 3, Рисунок 11).
Таблица 3
Данные, полученные при обработке документов программой ocr CuneiForm
|
№ |
Количество слов |
Слов с ошибками (нет слов) |
Без ошибок |
Качество обработки % |
|
1 |
111 |
18 |
93 |
83,78 |
|
2 |
124 |
120 |
4 |
3,23 |
|
3 |
273 |
273 |
0 |
0,00 |
|
4 |
151 |
147 |
4 |
2,65 |
|
5 |
144 |
141 |
3 |
2,08 |
|
6 |
178 |
175 |
3 |
1,69 |
|
7 |
199 |
166 |
33 |
16,58 |
|
8 |
201 |
175 |
26 |
12,94 |
|
9 |
121 |
119 |
2 |
1,65 |
|
10 |
126 |
122 |
4 |
3,17 |
|
Среднее значение |
162,8 |
145,6 |
17,2 |
12,78 |
|
MIN |
111 |
18 |
0 |
0,00 |
|
MAX |
273 |
273 |
93 |
83,78 |

Рисунок 11. Соотношение слов без ошибок к общему количеству слов (обработано OCR CuneiForm)
Как можем видеть, OCR CuneiForm является низкокачественным программным продуктов для распознавания оптического текста. Основную часть слов переводит в непонятный набор символов или вообще не распознает. В среднем, количество распознанных слов составляет 12,8 %. Это очень низкое качество.
Плюсы: данная программа бесплатная, русифицированная, имеется доступ к исходным кодам программы (используя их, можно запускать программу для анализа графического документа с помощью написанного кода на С#). Минусы: низкое качество распознавания.
Ниже представлена диаграмма, сравнивающая количество обработанных слов различными программами (Рисунок 12).

Рисунок 12. Соотношение слов без ошибок к общему количеству слов для разных программ по распознаванию текста
Анализ проводился без корректировки активных полей для распознавания, т.е. программы переводили текст только в тех местах графического файла, где они его определили. Суть распознавания без корректировки в том, что мы не тратим время на выбор того или иного поля, соответственно, не затрачиваем время на обработку. В таком виде анализа возможны потери качества, но так как основная цель дипломной работы – оптимизировать бизнес-процесс, значит, будем полагаться на корректную обработку документа программой для оптического распознавания текста (Рисунок 13).

Рисунок 13. Качество обработки документов (количество обработанных слов, выраженное в процентах, %)
Исходя из результатов анализа, можно сделать вывод, что программа ABBYY FineReader является наилучшим продуктом для оптического распознавания графического файла. Данная программа имеет широкий спектр возможностей и множество плюсов. Сервис FREE ONLINE OCR SERVICE также неплох для быстрого распознавания текста на картинке, но не подходит для автоматизации бизнес-процесса из-за минимального функционала. Программное обеспечение OCR CuneiForm оказалось низкокачественным продуктом и не будет использовано в качестве программы, используемой в данной дипломной работе. 32
Также были проанализированы программы для распознавания текстов, такие как TopOCRDemo и Capture Text, но ни одна из них в нашем случае не показала достойных результатов в качественном переводе текста из графического формата в текстовый.
В данной дипломной работе будет использована программа ABBYY FineReader 12.