

7.2. Индексирование
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к записи таблицы по ключу. Различают индексированный файл и индексный файл (рис. 7.5). Индексированный файл — это основной файл, содержащий данные отношения, для которого создан индексный файл.
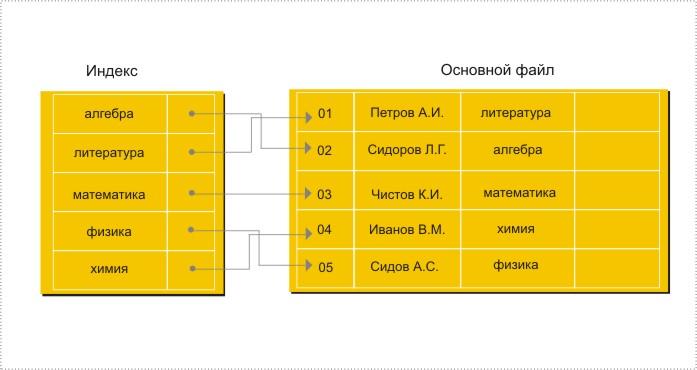
Рис. 7.5. Индексированный и индексный файлы
Индексный файл — это файл особого типа, в котором каждая запись состоит из двух значений: данных и указателя. Данные представляют поле, по которому производится индексирование, а указатель осуществляет связывание с соответствующим кортежем индексированного файла. Если индексирование осуществляется по ключевому полю, то индекс называется первичным. Такой индекс к тому же обладает свойством уникальности, т. е. не содержит дубликатов ключа.
Основное преимущество использования индексов заключается в значительном ускорении процесса выборки данных, а основной недостаток — в замедлении процесса обновления данных. Действительно, при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс в индексный файл.
7.2.1. Индексно-прямые файлы
В индексно-прямых файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а индексная запись содержит значение первичного ключа и порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в индексно-прямых файлах для каждой записи в основной области существует только одна запись из индексной области. Такой индекс называется плотным. Все записи в индексной области упорядочены по значению ключа.
Наиболее эффективным алгоритмом поиска на упорядоченном массиве является бинарный поиск. При этом все пространство поиска разбивается пополам, и так как оно строго упорядочено, то сначала определяется, не является ли срединный элемент искомым, а если нет, то дается оценка в какой половине его надо искать. Далее установленная половина также делится пополам и производятся аналогичные действия, и так до тех пор, пока не будет обнаружен искомый элемент.
Потом путем прямой адресации происходит обращение к основной области уже по конкретному номеру записи.
Операция добавления осуществляет запись в конец основной области. В индексной области при этом производится занесение информации так, чтобы не нарушать упорядоченности. Поэтому вся индексная область файла разбивается на блоки и при начальном заполнении в каждом блоке остается свободная область (процент расширения) (рис. 7.6).
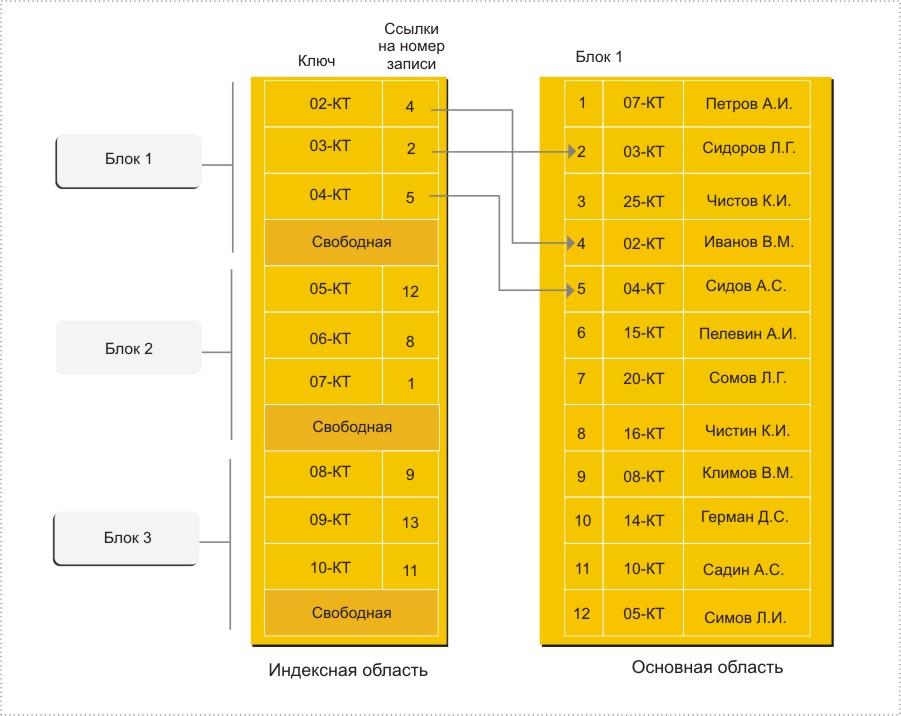
Рис. 7.6. Организация индексно-прямой адресации
При проектировании физической базы данных так важно заранее как можно точнее определить объемы хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
При удалении записи возникает следующая последовательность действий: запись в основной области помечается как удаленная, в индексной области соответствующий индекс уничтожается физически, то есть записи индексного файла, следующие за удаленной записью, перемещаются на ее место, и блок, в котором хранился данный индекс, заново записывается на диск. При этом количество обращений к диску для этой операции такое же, как и при добавлении новой записи.