

Шины.PCI,.USB.и.FireWire
.pdfПорт графического акселератора — AGP
Порт AGP (Accelerated Graphic Port — порт ускоренной графики) был введен для подключения графических адаптеров с 3D$акселераторами. Такой адаптер содер$ жит акселератор — специализированный графический процессор; локальную па мять, используемую как видеопамять и как локальное ОЗУ графического процес$ сора; управляющие и конфигурационные регистры, доступные как локальному, так и центральному процессорам. Акселератор может обращаться и к локальной па$ мяти, и к системному ОЗУ, в котором для него могут храниться наборы данных, не умещающиеся в локальной памяти (как правило, текстуры большого объема). Ос$ новная идея AGP заключается в предоставлении акселератору максимально быст$ рого доступа к системной памяти (локальная ему и так близка), более приоритет$ ного, чем доступ к ОЗУ со стороны других устройств.
Порт AGP представляет собой 32$разрядный параллельный синхронный интер$ фейс с тактовой частотой 66 МГц; большая часть сигналов позаимствована из шины PCI. Однако в отличие от PCI порт AGP представляет собой двухточечный интер$ фейс, соединяющий графический акселератор с памятью и системной шиной про$ цессора каналами данных чипсета системной платы, не пересекаясь с «узким мес$ том» — шиной PCI. Обмен через порт может происходить как по протоколу PCI, так и по протоколу AGP. Отличительные особенности порта AGP:
конвейеризация обращений к памяти;
умноженная (2x/4x/8x) частота передачи данных (относительно тактовой ча$ стоты порта);
«внеполосная» подача команд (SBA), обеспеченная демультиплексированием шин адреса и данных.
Идею конвейеризации обращений к памяти иллюстрирует рис. 7.1, где сравнива$ ются обращения к памяти по шине PCI и через порт AGP. В PCI во время реакции памяти на запрос шина простаивает (но не свободна). Конвейерный доступ AGP позволяет в это время передавать следующие запросы, а потом получить поток ответов.
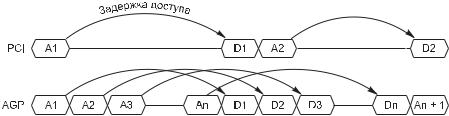
Рис. 7.1. Циклы обращения к памяти PCI и AGP
Умножение частоты передачи данных обеспечивает при частоте 66 МГц пиковую пропускную способность до 533 (2x), 1066 (4x) и 2132 Мбайт/с в режиме 8x. Выше 66 МГц тактовую частоту официально не поднимают.
Демультиплексирование (разделение) шины адреса и данных сделано несколько необычным образом. С целью экономии числа интерфейсных линий шину адреса и команды в демультиплексированном режиме AGP представляют всего 8 линий SBA (SideBand Address), по которым команда, адрес и значение длины передачи передаются последовательно за несколько тактов. Поддержка демультиплексиро$ ванной адресации не являлась обязательной для устройства AGP 1.0, поскольку имеется альтернативный способ подачи адреса по шине AD. В версии AGP 2.0 она стала обязательной, а в 3.0 это уже единственный способ подачи адреса.
Отметим, что порт AGP дает только преимущества, которые могут быть реализо$ ваны лишь при поддержке аппаратными средствами графического адаптера и спе$ циального ПО. Графический адаптер с интерфейсом AGP может реально вести себя по$разному:
не задействовать конвейеризацию, а использовать только быструю запись PCI (Fast Write);
не работать с текстурами, расположенными в системной памяти, но использо$ вать более быстрый обмен данными между памятью и локальным буфером;
использовать все возможности порта, когда акселератор имеет быстрый доступ к системной памяти, а центральный процессор может быстро закачивать дан$ ные в локальную память адаптера.
Порт AGP содержит практически полный набор сигналов шины PCI и дополни$ тельные сигналы AGP. Устройство, подключаемое к порту AGP, может предназ$ начаться как исключительно для операций AGP, так и быть комбинацией AGP + PCI. Акселератор адаптера является мастером (ведущим устройством) порта AGP, свои запросы он может выполнять как в режиме AGP, так и в режиме PCI (см. гла$ ву 2). В режиме AGP обмены выполняются с поддержкой (или без поддержки) таких свойств, как внеполосная адресация (SBA) и скорость 2x/4x/8x. Для тран$ закций в режиме AGP ему доступно только системное ОЗУ (но не локальная па$ мять устройств PCI). Кроме того, адаптер является целевым устройством PCI, для которого, кроме обычных команд PCI, может поддерживаться (или не поддержи$ ваться) быстрая запись (Fast write) со стороны процессора (сокоростью 2x/4x/8x).
В качестве целевого устройства адаптер выступает при обращениях ЦП к его ло$ кальной памяти, регистрам ввода$вывода и конфигурационного пространства.
Устройство, подключаемое к AGP, обязательно должно выполнять функции веду$ щего устройства AGP (иначе порт AGP для него теряет смысл) и функции ведомо$ го устройства PCI со всеми его атрибутами (конфигурационными регистрами и т. п.); дополнительно оно может быть и ведущим устройством PCI.
Порт AGP позволяет акселератору работать в двух режимах — DMA и DIME (DIrect Memory Execute). В режиме DMA акселератор при вычислениях рассмат$ ривает локальную память как первичную, а когда ее недостаточно, подкачивает в нее данные из основной памяти. В режиме DIME (он же режим исполнения, Executive Mode) локальная память и основная память для акселератора логически равнозначны и располагаются в едином адресном пространстве. В режиме DMA для трафика порта характерны длительные блочные передачи, в режиме DIME трафик порта будет насыщен короткими произвольными запросами.
Спецификации AGP разрабатывались фирмой Intel на базе шины PCI 2.1 с часто$ той 66 МГц; пока имеется три основные версии спецификаций:
AGP 1.0 (1996 год) — определен порт с конвейерным обращением к памяти, двумя альтернативными способами подачи команд: внеполосной (по шине SBA) и внутриполосной (по сигналу PIPE#). Режимы передачи 1x/2x, питание интер$ фейса — 3,3 В;
AGP 2.0 (1998 год) — добавлена возможность быстрой записи в режиме PCI (Fast Writes), а также режим 4х с питанием 1,5 В;
AGP 3.0 (2002 год, проект назывался AGP8X) — добавлен режим 8x с питанием 0,8 В и динамическим инвертированием байтов, отменены скорости 1x и 2x; оставлен один способ подачи команд — внеполосный (SBA); исключены неко$ торые команды AGP; введены команды изохронного обмена; введена возмож$ ность выбора размера страниц, описанных в GART; введена селективная поддерж$ ка когерентности при обращениях к разным страницам в пределах GART.
Порт AGP предназначен только для подключения интеллектуального графического адаптера, имеющего 3D$акселератор, причем только одного. Системная логика порта AGP отличается сложным контроллером памяти, который выполняет глу$ бокую буферизацию и высокопроизводительное обслуживание запросов AGP (от адаптера) и других своих клиентов — центрального процессора (одного или не$ скольких) и шины PCI. Единственный вариант подключения нескольких адапте$ ров с AGP — организация на системной плате нескольких портов AGP, что вряд ли будет применяться.
AGP может реализовать всю пропускную способность 64$битной системы памяти современного компьютера. При этом возможны конкурирующие обращения к па$ мяти как со стороны процессора, так и со стороны мостов шин PCI. Фирма Intel впервые ввела поддержку AGP в чипсеты для процессоров P6, конкуренты исполь$ зуют AGP и в системных платах для процессоров с интерфейсом Pentium (сокет Super 7). В настоящее время порт AGP имеется практически во всех системных платах для PC$совместимых компьютеров и других платформ (даже Macintosh).

Протоколы транзакций
Транзакции в режиме PCI, инициируемые акселератором, начинаются с подачи сигнала FRAME# и выполняются обычным для PCI способом (см. главу 2). Заме$ тим, что при этом на все время транзакции шина AD занята, причем транзакции чтения памяти занимают шину на большее число тактов, чем транзакции запи$ си, — после подачи адреса неизбежны такты ожидания на время доступа к памяти. Запись на шине происходит быстрее — данные записи задатчик посылает сразу за адресом, а на время доступа к памяти они «оседают» в буфере контроллера памя$ ти. Контроллер памяти позволяет завершить транзакцию и освободить шину до физической записи в память.
Конвейерные транзакции AGP (команды AGP) инициируются только акселерато$ ром; логикой AGP они ставятся в очереди на обслуживание и исполняются в зави$ симости от приоритета, порядка поступления запросов и готовности данных. Эти транзакции могут быть адресованы акселератором только к системному ОЗУ. Если устройству на AGP требуется обратиться к локальной памяти каких$либо устройств PCI, то оно должно выполнять эти транзакции в режиме PCI.
Обращения со стороны процессора (или задатчиков шины PCI), адресованные к устройству на AGP, отрабатываются им как ведомым устройством PCI, однако имеется возможность быстрой записи в локальную память — FW (Fast Write), в ко$ торой данные передаются на скорости AGP (2x/4x/8x), и управление потоком их передач ближе к протоколу AGP, нежели PCI. Транзакции FW инициируются про$ цессором и предназначены для принудительного «заталкивания» данных в локаль$ ную память акселератора.
Концепцию конвейера AGP иллюстрирует рис. 7.2. Порт AGP может находиться
водном из четырех состояний:
IDLE — покой;
DATA — передача данных конвейеризированных транзакций;
AGP — постановка в очередь команды AGP;
PCI — выполнение транзакции в режиме PCI.
Рис. 7.2. Конвейер AGP
Из состояния покоя IDLE порт может вывести запрос транзакции PCI (как от ак$ селератора, так и с системной стороны) или запрос AGP (только от акселератора). В состоянии PCI транзакция PCI выполняется целиком, от подачи адреса и коман$

ды до завершения передачи данных. В состоянии AGP ведущее устройство переда$ ет только команду и адрес для транзакции (по сигналу PIPE# или через шину SBA), ставящейся в очередь; несколько запросов могут следовать сразу друг за другом. В состояние DATA порт переходит, когда у него в очереди имеется необслуженная команда, готовая к исполнению. В этом состоянии происходит передача данных для команд, стоящих в очереди. Это состояние может прерываться вторжением запросов PCI (для выполнения целой транзакции) или AGP (для постановки в оче$ редь новой команды), но прерывание1 возможно только на границах данных транз$ акций AGP. Когда порт AGP обслужит все команды, он снова переходит в состоя$ ние покоя. Все переходы происходят под управлением арбитра порта AGP, реагирующего на поступающие запросы (сигнал REQ# от акселератора и вне$ шние обращения от процессора или других устройств PCI) и ответы контрол$ лера памяти.
Транзакции AGP отличаются от транзакций PCI некоторыми деталями реа$ лизации:
фаза данных отделена от фазы адреса, чем и обеспечивается конвейеризация;
используется собственный набор команд;
транзакции адресуются только к системной памяти, используя пространство физических адресов (как и в PCI). Транзакции могут иметь длину, кратную 8 байтам, и начинаться только по 8$байтной границе. Транзакции чтения иного размера должны выполняться только в режиме PCI; транзакции записи могут использовать сигналы C/BE[3:0]# для маскирования лишних байтов;
длина транзакции явно указывается в запросе;
конвейерные запросы не гарантируют когерентности памяти и кэша. Для опе$ раций, требующих когерентности, должны использоваться транзакции PCI. В AGP 3.0 возможно указать области памяти, для которых когерентность обес$ печивается и для конвейерных транзакций.
Возможны два способа подачи команд AGP (постановок и запросов в очередь), из которых в текущей конфигурации выбирается один, причем изменение способа «на ходу» не допускается:
запросы вводятся по шине AD[31:0] и C/BE[3:0] с помощью сигнала PIPE#, по каж$ дому фронту CLK ведущее устройство передает очередное двойное слово запро$ са вместе с кодом команды;
команды подаются через внеполосные (sideband) линии адреса SBA[7:0]. «Вне$ полосность» означает, что эти сигналы используются независимо от занятости шины AD. Синхронизация подачи запросов зависит от режима (1x/2x/4x/8x).
При подаче команд по шине AD во время активности сигнала PIPE# код команды AGP (CCCC) кодируется сигналами C/BE[3:0], при этом на шине AD помещаются начальный адрес (на AD[31:3]) и длина n (на AD[2:0]) запрашиваемого блока дан$ ных. Определены следующие команды (в скобках указан код CCCC):
1Здесь прерыванием называем вклинивание команд AGP и транзакций PCI в поток передач данных; к прерываниям процессора это не имеет отношения.
Read (0000) — чтение из памяти (n + 1) учетверенных слов (по 8 байт) данных, начиная с указанного адреса;
HP Read (0001) — чтение с высоким приоритетом (упразднено в AGP 3.0);
Write (0100) — запись в память;
HP Write (0101) — запись с высоким приоритетом (упразднено в AGP 3.0);
Long Read (1000) — «длинное» чтение (n + 1)×4 учетверенных слов (до 256 байт данных, упразднено в AGP 3.0);
HP Long Read (1001) — «длинное» чтение с высоким приоритетом (упразднено
вAGP 3.0);
Flush (1010) — очистка, выгрузка данных всех предыдущих команд записи по адресам назначения (на порте AGP выглядит как чтение, возвращающее про$ извольное учетверенное слово в качестве подтверждения исполнения; адрес и длина, указанные в запросе, значения не имеют);
Fence (1100) — установка «ограждений», позволяющих низкоприоритетному потоку записей не пропускать чтения;
Dual Address Cycle, DAC (1101) — двухадресный цикл для 64$битной адресации:
впервом такте по AD передаются младшая часть адреса и длина запроса, а во вто$ ром — старшая часть адреса (по AD) и код исполняемой команды (по C/BE[3:0]).
Для изохронных передач в AGP 3.0 выделены специальные команды (см. далее).
При внеполосной подаче команд по шине SBA[7:0] передаются 16$битные посылки четырех типов. Тип посылки кодируется старшими битами:
тип 1: 0AAA AAAA AAAA ALLL — поле длины (LLL) и младшие биты адреса (A[14:03]);
тип 2: 10CC CCRA AAAA AAAA — код команды (CCCC) и средние биты адреса (A[23:15]);
тип 3: 110R AAAA AAAA AAAA — старшие биты адреса (A[35:24]);
тип 4: 1110 AAAA AAAA AAAA — дополнительные старшие биты адреса, если требуется 64$битная адресация.
Посылка из всех единиц является пустой командой (NOP); такие посылки означа$ ют покой шины SBA. Биты «R» зарезервированы. Посылки типов 2, 3 и 4 являются «липкими» (sticky) — значения, ими определяемые, сохраняются до введения но$ вой посылки того же типа. Постановку команды в очередь инициирует посылка типа 1, задающая длину транзакции и ее младшие адреса, — код команды и осталь$ ная часть адреса должны быть определены ранее введенными посылками типов 2– 4. Такой способ очень экономно использует такты шины для подачи команд при пересылках массивов. Каждая 2$байтная посылка передается по 8$битной шине SBA за два приема (сначала старший, потом младший байт). Синхронизация бай$ тов зависит от режима порта:
в режиме 1x каждый байт передается по фронту CLK; начало посылки (старший байт) определяется по получению байта, отличного от 11111111b, по последую$ щему фронту передается младший байт. Очередная команда (посылкой типа 1)
может вводиться за каждую пару тактов CLK (при условии, что код команды и старший адрес уже введены предыдущими посылками). Полный цикл ввода команды занимает 10 тактов;
в режиме 2x для SBA используется отдельный строб SB_STB, по его спаду переда$ ется старший байт, а по последующему фронту — младший. Частота этого стро$ ба (но не фаза) совпадает с CLK, так что очередная команда может вводиться
в каждом такте CLK;
в режиме 4x используется еще и дополнительный (инверсный) строб SB_STB#. Старший байт фиксируется по спаду SB_STB, а младший — по последующему спаду SB_STB#. Частота стробов в два раза выше, чем CLK, так что в каждом такте CLK может вводиться пара посылок. Однако мастер AGP может вводить в каж$ дом такте не более одной посылки типа 1, то есть ставить в очередь не более одного запроса;
В режиме 8x стробы называются иначе (SB_STBF и SB_STBS), их частота в четыре раза выше CLK, так что в каждом такте CLK умещаются уже 4 посылки. Однако темп постановки команд в очередь все равно ограничен одной командой за такт CLK.
В ответ на полученные команды порт AGP выполняет передачи данных, причем фаза данных AGP явно не привязана к фазе команды/адреса. Фаза данных будет вводиться портом AGP по готовности системной памяти к запрашиваемому обмену.
Передачи данных AGP выполняются, когда шина находится в состоянии DATA. Фазы данных вводит порт AGP (системная логика), исходя из порядка ранее при$ шедших к нему команд от акселератора. Акселератор узнает о назначения шины AD в последующей транзакции по сигналам ST[2:0] (действительны только во вре$ мя сигнала GNT#, коды 100–110 зарезервированы):
000 — устройству будут передаваться данные низкоприоритетного запроса чте$ ния (в AGP 3.0 — просто асинхронного чтения), ранее поставленного в очередь, или выполняется очистка;
001 — устройству будут передаваться данные высокоприоритетного запроса чтения (резерв в AGP 3.0);
010 — устройство должно будет предоставлять данные низкоприоритетного запроса записи (в AGP 3.0 — просто асинхронной записи);
011 — устройство должно будет предоставлять данные высокоприоритетного запроса записи (резерв в AGP 3.0);
111 — устройству разрешается поставить в очередь команду AGP (сигналом PIPE#) или начать транзакцию PCI (сигналом FRAME#);
110 — цикл калибровки приемопередатчиков (в AGP 3.0 для скорости 8x).
Акселератор узнает лишь тип и приоритет команды, результаты которой последу$ ют в данной транзакции. Какую именно команду из очереди отрабатывает порт, акселератор определяет сам, так как именно он ставил их в очередь (ему известен порядок). Никаких тегов транзакций (как, например, в системной шине процессо$ ров P6 или в PCI$X) в интерфейсе AGP нет. Имеются только независимые очере$ ди для каждого типа команд (чтение низкоприоритетное, чтение высокоприори
тетное, запись низкоприоритетная, запись высокоприоритетная). Фазы испол$ нения команд разных очередей могут чередоваться произвольным образом; порт имеет право исполнять их в порядке, оптимальном с точки зрения производитель$ ности. Реальный порядок исполнения команд (чтения и записи памяти) тоже мо$ жет изменяться. Однако для каждой очереди порядок выполнения всегда совпада$ ет с порядком подачи команд (об этом знают и акселератор, и порт). В AGP 3.0 приоритеты очередей отменили, но ввели возможность изохронных транзакций.
Запросы AGP с высоким приоритетом для арбитра системной логики являются более приоритетными, чем запросы от центрального процессора и ведущих уст$ ройств шины PCI. Запросы AGP с низким приоритетом для арбитра имеют при$ оритет ниже, чем от процессора, но выше, чем от остальных ведущих устройств. Хотя принятый протокол никак явно не ограничивает глубину очередей, специфи$ кация AGP формально ее ограничивает до 256 запросов. На этапе конфигурирования устройства система PnP устанавливает реальное ограничение (в конфигурацион$ ном регистре акселератора) в соответствии с его возможностями и возможностя$ ми системной платы. Программы, работающие с акселератором (исполняемые и ло$ кальным, и центральным процессорами), не должны допускать превышения числа необслуженных команд в очереди (у них для этого имеется вся необходимая ин$ формация).
При передаче данных AGP управляющие сигналы, заимствованные от PCI, имеют почти такое же назначение, что и в PCI. Передача данных AGP в режиме 1x очень похожа на циклы PCI, но немного упрощена процедура квитирования (поскольку это выделенный порт и обмен выполняется только с быстрым контроллером си$ стемной памяти). В режимах 2x/4x/8x имеется специфика стробирования:
в режиме 1x данные (4 байта на AD[31:0]) фиксируются получателем по поло$ жительному перепаду каждого такта CLK, что обеспечивает пиковую скорость 66,6×4 = 266 Мбайт/с;
в режиме 2x используются стробы данных AD_STB0 и AD_STB1 для линий AD[0:15]
иAD[16:31] соответственно. Стробы формируются источником данных, прием$ ник фиксирует данные и по спаду, и по фронту строба. Частота стробов совпадает с частотой CLK, что и обеспечивает пиковую скорость 66,6×2×4 = 533 Мбайт/с;
в режиме 4x используются еще и дополнительные (инверсные) стробы AD_STB0#
иAD_STB1#. Данные фиксируются по спадам и прямых и инверсных стробов (пары стробов могут использоваться и как два отдельных сигнала, и как один дифференциальный). Частота стробов в два раза выше, чем CLK, что и обеспечи$ вает пиковую скорость 66,6×2×2×4 = 1066 Мбайт/с;
в режиме 8x пары стробов получили новые названия AD_STBF[1:0] (First — пер$ вый) и AD_STBS[1:0] (Second — второй), четные порции данных защелкиваются по положительному перепаду первого, нечетные — по перепаду второго. Часто$ та переключения каждого из этих стробов в четыре раза выше CLK, стробы сдви$ нуты относительно друг друга на половину своего периода, чем и обеспечивает$ ся восьмикратная частота стробирования информации на линиях AD. Отсюда пиковая скорость 66,6×4×2×4 = 2132 Мбайт/с.
Порт AGP должен отслеживать состояние готовности буферов акселератора к по$ сылке или получению данных транзакций, поставленных в очередь. Сигналом RBF# (Read Buffer Full) акселератор может информировать порт о неготовности к при$ ему данных низкоприоритетных транзакций чтения (к приему высокоприоритет$ ных он должен быть всегда готов). Сигналом WBF# (Write Buffer Full) он информи$ рует о неспособности принять первую порцию данных быстрой записи FW.
Трансляция адресов — GART и апертура AGP
Порт AGP обеспечивает трансляцию логических адресов, фигурирующих в запро$ сах акселератора к системной памяти, в физические адреса, согласуя видение ОЗУ программой, выполняемой акселератором, и программой, выполняемой на цент$ ральном процессоре. Трансляция осуществляется в постраничном базисе (по умол$ чанию размер страницы — 4 Кбайт), принятом в системе виртуальной памяти с подкачкой страниц по запросу, используемой в процессорах x86 (и других совре$ менных процессорах). Трансляции подлежат обращения, попадающие в апертуру AGP, — область физических адресов памяти, лежащую выше границы ОЗУ и, как правило, примыкающую к области локальной памяти адаптера (рис. 7.3). Таким образом, при работе в режиме DIME акселератору доступна непрерывная область памяти, часть которой составляет локальная память адаптера. Остальная часть ад$ ресуемой им памяти отображается на системное ОЗУ через апертуру с помощью таблицы GART (Graphics Address Remapping Table — таблица переопределения графических адресов). Каждый элемент этой таблицы описывает свою страни$ цу в области апертуры. В каждом элементе GART есть признак его действительнос$ ти; в действительных элементах указывается адрес страницы физической памяти, на которую отображается соответствующая область апертуры. Таблица GART фи$ зически находится в системном ОЗУ, она выровнена по границе 4$килобайтовой страницы, на ее начало указывают конфигурационные регистры порта AGP.
Размер апертуры AGP (определяющий и размер таблицы GART) задается програм$ мированием регистров чипсета. Путем настройки параметров CMOS Setup или внешних утилит его можно задать размером 8, 16, 32...256 и более Мбайт. Опти$ мальное значение апертуры зависит от объема памяти и используемых программ, но можно ориентироваться на половину объема системного ОЗУ. Заметим, что назначение размера апертуры в большинстве случаев еще не означает отчуждения указанного объема ОЗУ от системного ОЗУ — это лишь предельный размер памя$ ти, которую ОС будет выделять акселератору по его запросам. Пока акселератору хватает своей локальной памяти, он не запрашивает память в системном ОЗУ. Только при нехватке локальной памяти он будет динамически запрашивать до$ полнительную, и эти запросы будут удовлетворяться в пределах установленной апертуры. По мере уменьшения потребности в дополнительной памяти она будет динамически высвобождаться для обычных нужд операционной системы. Правда, если у графического акселератора локальной памяти нет вообще (в дешевых ин$

тегрированных адаптерах), то от ОЗУ статически (на все время работы) отчуж$ дается часть памяти (хотя бы под экранный буфер). Это видно по уменьшенному размеру памяти, который POST показывает в начале процесса загрузки.
Рис. 7.3. Адресация памяти в системе с AGP |
Логика порта обеспечивает когерентность всех кэш$памятей системы для обра$ щений мастера AGP вне диапазона адресов апертуры. В AGP 3.0 введена возмож$ ность выборочного обеспечения когерентности для обращений внутри апертуры. В предыдущих версиях предполагалось, что область памяти внутри апертуры долж$ на быть просто некэшируемой. Поскольку эту память предполагалось использо$ вать для хранения текстур (они достаточно статичны), такое упрощение вполне приемлемо.
Изохронные транзакции в AGP 3.0
Для поддержки изохронных транзакций в AGP 3.0 введены новые коды команд и состояний, а также конфигурационные регистры, управляющие изохронным со$ единением. Изохронные транзакции может выполнять мастер AGP только через область апертуры AGP, причем с областью памяти, для которой не обеспечивается когерентность (чтобы избежать непрогнозируемых задержек, связанных с выгруз$ ками «грязных» строк). Изохронные транзакции возможны только на скорости 8x. Соглашение на изохронный обмен описывается набором параметров:
N — число транзакций чтения или записи за период времени T;
V — размер блока данных в изохронной транзакции;
L — максимальная задержка (латентность) доставки данных от подачи коман$ ды (в периодах T).