

Шины.PCI,.USB.и.FireWire
.pdfти ведущего устройства может быть различной. В простейшем варианте ведущее устройство обеспечивает пересылку блоков данных между устройством и систем$ ной памятью (или памятью других устройств) по указанию от CPU. Здесь CPU командами обращения к определенным регистрам ведущего устройства задает на$ чальный адрес, длину блока, направление пересылки и разрешает запуск переда$ чи. После этого пересылка выполняется по готовности (или инициативе) устрой$ ства, без отвлечения CPU. Таким образом выполняется прямой доступ к памяти (DMA). Более сложный контроллер DMA может организовывать сцепку буферов при чтении, разбросанную запись и т. п. — возможности, знакомые еще по «продви$ нутым» контроллерам DMA для ISA/EISA. Более интеллектуальное ведущее уст$ ройство, как правило, обладающее собственным микроконтроллером, не ограничи$ вается такой простой работой по указке CPU — оно выполняет обмены уже по программе своего контроллера. Таким интеллектом обладают, например, хост$кон$ троллеры последовательных шин USB и IEEE 1394, рассмотренные в данной книге.
Для совместимости устройств PCI со старым PC$ориентированным ПО и упро$ щения устройств PCI фирма Intel разработала специальный протокол PC/PCI DMA, позволяющий централизованно эмулировать стандартную (для PC) связку кон$ троллеров DMA 8237. Альтернативное решение — механизм DDMA (Distributed DMA — распределенный DMA) позволяет «расчленить» стандартный контроллер и отдельные его каналы эмулировать средствами карт PCI. Оба этих механизма реализуемы только как часть моста между первичной шиной PCI и шиной ISA, поэтому их поддержка может обеспечиваться (или не обеспечиваться) только на системной плате и разрешаться в CMOS Setup.
Для поддержки протокола PC/PCI главный мост PCI комбинируется с контролле$ ром DMA, программно$совместимым с парой 8237. Так, например, в хабе$контрол$ лере ввода/вывода ICH3 (микросхема 82801CA фирмы Intel) имеется 7$каналь$ ный контроллер DMA, у которого любой из каналов может быть подключен к протоколу PC/PCI или шине LPC. Подключением каналов к тому или иному протоколу управляет специальный 16$битный регистр (смещение 90h в конфигу$ рационном пространстве нулевой функции устройства ICH), в котором каждому каналу отводится пара бит. Хаб ICH является и главным мостом PCI, обеспечи$ вая, естественно, и функции арбитража для абонентов шины, включая и свои ин$ тегрированные устройства. В протоколе PC/PCI меняется назначение пары сиг$ налов REQi# и GNTi# для заранее выбранного агента шины PCI, являющегося «проводником» DMA. Этот агент имеет внешние (по отношению к шине PCI) пары сигналов DRQx# и DACKx# с логикой, аналогичной одноименным сигналам ISA DMA, а линии REQi# и GNTi# в процессе запроса управления шиной использует особым образом (рис. 2.6). Когда агент получает запрос DRQx (один или несколько), он по линии REQi# передает в последовательном коде состояние активности линий за$ просов DRQx. В первом такте CLK передается старт$бит — низкий уровень REQi#, во втором — активность запроса DRQ0, затем DRQ1 и так далее до DRQ7, после чего со$ храняется низкий уровень REQ#. На это сообщение хаб1 ответит по линии GNTi#
1 Или иной вариант реализации моста, но дальше для краткости будем ссылаться на хаб.

посылкой с указанием номера канала, которому дается подтверждение DACKx# для передачи данных в последующих транзакциях.
Рис. 2.6. Протокол PC/PCI
Далее хаб (как инициатор на PCI) организует передачу данных между агентом PCI DMA и памятью, при этом направлением передачи и текущим адресом в памяти управляет контроллер 8237, находящийся в том же хабе. Во время этой передачи сигнал GNTi# остается активным. Передача каждого байта или слова данных ведет$ ся не за один шинный цикл, как в ISA DMA, а за пару шинных циклов PCI: в одном цикле происходит обращение к памяти, в другом — к агенту PCI DMA. Порядок циклов определяется направлением передачи (понятно, что в первом цикле дан$ ные должны быть считаны, а во втором — записаны). В этих циклах данные пере$ даются только по линиям AD[7:0] при работе с 8$битными каналами и по AD[15:0] при работе с 16$битными с соответствующими сигналами BE[3:0]#. В цикле обра$ щения к памяти (команда Memory Read или Memory Write) фигурирует адрес па$ мяти, сформированный соответствующим каналом 8237. В цикле ввода/вывода (обращения к агенту) команды IO Read или IO Write адресуются к специальным адресам:
00h — передача данных;
04h — передача данных с признаком конца цикла (сигнал TC контроллера 8237).
Кроме передачи данных протокол PC/PCI позволяет эмулировать и режим вери$ фикации DMA (без передачи данных), здесь используется команда IO Read с дру$ гими адресами:
C0h — верификация данных;
C4h — верификация данных с признаком конца цикла.
Агент должен сообщать хабу обо всех изменениях состояний линий запросов DRQx, в том числе и о снятии сигналов запроса. Если агент сигнализирует об установке более одной линии запроса, то после того, как какой$то из них будет обслужен, агент должен повторить посылку запроса для необслуженного канала. Для посыл$ ки новой информации о запросах агент на один такт снимает сигнал REQi# и снова вводит посылку запроса, начинающуюся со старт$бита. О снятии DRQx, соответ$ ствующего обслуживаемому в данный момент каналу, агент сигнализирует сняти$ ем сигнала REQi# на два такта PCI; это он должен сделать за 7 тактов до подачи им сигнала TRDY# в цикле ввода/вывода, иначе хаб начнет следующий цикл передачи.
Механизм PC/PCI DMA реализуют только в чипсете системной платы. В частно$ сти, вышеупомянутый хаб ICH3 позволяет запрограммировать на поддержку PC/ PCI не более двух пар сигнальных линий REQi# и GNTi#. При этом данные линии не смогут использоваться для обычного арбитража устройств PCI. Сам агент PCI DMA тоже должен находиться на системной плате, он обеспечивает каналами DMA ус$ тройства шины ISA. Поддержку PC/PCI можно разрешать и запрещать через CMOS Setup. Через слоты PCI протокол PC/PCI, очевидно, не используется: упо$ минаний о механизме «объяснения» устройствам PCI, как должны использовать$ ся их линии GNT#/REQ# (штатно или по протоколу PC/PCI), автору найти не уда$ лось.
Пропускная способность шин PCI и PCI X
Шина PCI является самой высокоскоростной шиной расширения современных ПК, однако и ее реальная пропускная способность, увы, не так уж и высока. Рас$ смотрим наиболее распространенный вариант: разрядность 32 бита, частота 33 МГц. Как указывалось выше, пиковая скорость передачи данных внутри пакетного цик$ ла составляет 132 Мбайт/с, то есть за каждый такт шины передаются 4 байт дан$ ных (33 × 4 = 132). Однако пакетные циклы выполняются далеко не всегда. Про$ цессор общается с устройствами PCI инструкциями обращения к памяти или вводу$выводу через главный мост, который шинные транзакции процессора транс$ лирует в транзакции шины PCI. Поскольку у процессоров x86 основные регистры 32$разрядные, то одна инструкция порождает транзакцию с устройством PCI, в ко$ торой передается не более 4 байт данных, что соответствует одиночной передаче. Если же адрес передаваемого (двойного) слова не выровнен по соответствующей границе, то будут порождены два одиночных цикла или один пакетный с двумя фазами данных, но в любом случае это обращение будет выполняться дольше, чем при выровненном адресе.
При записи массива данных в устройство PCI (передача с последовательно нарас$ тающим адресом) мост может пытаться организовать пакетные циклы. У совре$ менных процессоров (начиная с Pentium) шина данных 64$битная и применяется буферизация записи, так что два последовательных 32$битных запроса записи объе$ динятся в один 64$битный. Этот запрос, если он адресован к 32$битному устрой$ ству, мост попытается передать пакетом с двумя фазами данных. «Продвинутый» мост может пытаться собирать в пакет и последовательные запросы, что может породить пакет существенной длины. Пакетные циклы записи можно наблюдать, например, передавая массив данных из ОЗУ в устройство PCI строковой инструк$ цией MOVSD, используя префикс повтора REP. Тот же эффект даст и цикл последо$ вательных операций LODSW, STOSW (и иных инструкций обращения к памяти). По$ скольку у современных процессоров ядро исполняет инструкции гораздо быстрее, чем шина способна вывести их результаты, между инструкциями, порождающими объединяемые записи, процессор может успеть выполнить еще несколько опера$ ций. Однако если пересылка данных организуется директивой языка высокого уровня, которая ради универсальности работает гораздо сложнее вышеприведен$
ных ассемблерных примитивов, транзакции, скорее всего, будут уже одиночными (у буферов записи процессора не хватит «терпения» придержать один 32$битный запрос до появления следующего, или же произойдет принудительная выгрузка буферов записи процессора или моста по запросу чтения).
Что касается чтения из устройства PCI, то здесь пакетный режим организовать сложнее. Буферизации чтения у процессора, естественно, нет (операцию чтения можно считать выполненной лишь по получении реальных данных), и даже стро$ ковые инструкции будут порождать одиночные циклы. Однако у современных процессоров имеются возможности генерации запросов чтения более 4 байт. Для этого можно использовать инструкции загрузки данных в регистры MMX (8 байт) или XMM (16 байт), а из них уже выгружать данные в ОЗУ (которое работает много быстрее устройств PCI).
Строковые инструкции ввода/вывода (INSW, OUTSW с префиксом повторения REP), используемые для программированного ввода/вывода блоков данных (PIO), по$ рождают серии одиночных транзакций, поскольку все данные блока относятся к одному адресу PCI.
Посмотреть, каким образом происходит обращение к устройству, несложно при наличии осциллографа: в одиночных транзакциях сигнал FRAME# активен в тече$ ние всего одного такта, в пакетных он длиннее. Число фаз данных в пакете соот$ ветствует числу тактов, во время которых активны оба сигнала IRDY# и TRDY#.
Стремиться к пакетизации транзакций записи стоит только в том случае, если уст$ ройство PCI поддерживает пакетные передачи в ведомом (target) режиме. Если это не так, то попытка пакетизации приведет даже к небольшой потере производи$ тельности, поскольку транзакция будет завершаться по инициативе ведомого уст$ ройства (сигналом STOP#), а не инициатора обмена, на чем теряется один такт шины. Так, к примеру, можно наблюдать, как при записи массива в память PCI, выполня$ емой директивой языка высокого уровня, устройство среднего быстродействия (вводящее лишь 3 такта ожидания готовности) принимает данные каждые 7 так$ тов, что при частоте 33 МГц и разрядности 32 бита дает скорость 33 × 4/7 = = 18,8 Мбайт/с. Здесь 4 такта занимает активная часть транзакции (от сигнала FRAME# до снятия сигнала IRDY#) и 3 такта паузы. То же устройство по инструкции MOVSD принимает данные каждые 8 тактов шины (33 × 4/8 = 16,5 Мбайт/с). Эти данные — результат наблюдения работы PCI$ядра, выполненного на основе мик$ росхемы FPGA фирмы Altera, не поддерживающего пакетные транзакции в ведо$ мом режиме. То же самое устройство при чтении памяти PCI работает существен$ но медленнее — инструкцией REP MOWSW с него удалось получать данные каждые 19–21 тактов шины (скорость 33 × 4/20 = 6,6 Мбайт/с). Здесь сказывается и боль$ шая задержка устройства (оно выдает данные лишь в 8 такте после появления сиг$ нала FRAME#), и то, что процессор начинает следующую пересылку, лишь дождав$ шись данных от предыдущей. Трюк с использованием регистра XMM здесь дает положительный эффект, несмотря на потерю такта (на прекращение транзакции непакетным устройством), поскольку каждый 64$битный запрос процессора вы$ полняется парой смежных транзакций PCI, между которыми пауза всего в пару тактов.
Для определения теоретического предела пропускной способности вернемся к рис. 2.1, чтобы определить минимальное время (число тактов) транзакций чте$ ния и записи. В транзакции чтения после подачи команды и адреса инициатором (такт 1) меняется текущий «владелец» шины AD. На этот так называемый пируэт (turnaround) уходит такт 2, что обусловливается задержкой сигнала TRDY# целе$ вым устройством. Далее может следовать фаза данных (такт 3), если целевое уст$ ройство достаточно расторопно. После последней фазы данных требуется еще 1 такт на обратный пируэт шины AD (в нашем случае это такт 4). Таким образом, одиноч$ ное чтение двойного слова (4 байта) занимает минимум 4 такта по 30 нс (33 МГц). Если эти транзакции следуют непосредственно друг за другом (если на такое спо$ собен инициатор и у него не отбирают право на управление шиной), то можно го$ ворить о максимальной скорости чтения в 33 Мбайт/с при одиночных транзакци$ ях. В транзакциях записи шиной AD все время управляет инициатор, так что здесь нет потери тактов на пируэт. При расторопном целевом устройстве, не вносящем дополнительных тактов ожидания, скорость записи может достигать 66 Мбайт/с.
Скорость, соизмеримую с максимальной пиковой, можно получить только при пакетных передачах, когда дополнительные 3 такта при чтении и 1 такт при запи$ си добавляются не к одной фазе данных, а к их последовательности. Так, для чте$ ния пакета с числом фаз данных 4 требуется 7 тактов (V = 16/(7 × 30) байт/нс = = 76 Мбайт/с), а для записи — 5 (V = 16/(5 × 30) байт/нс = 106,6 Мбайт/с). При 16 фазах данных скорость чтения может достигать 112 Мбайт/с, а записи — 125 Мбайт/с.
В этих выкладках не учитывались потери времени, связанные со сменой инициа$ тора. Инициатор может начинать транзакцию по получении сигнала GNT#, только убедившись в том, что шина находится в покое (сигналы FRAME# и IRDY# пассив$ ны); на фиксацию состояния покоя уходит 1 такт. Как видно, захватывать для од$ ного инициатора большую часть пропускной способности шины можно, увеличи$ вая длину пакета. Однако при этом возрастет задержка получения управления шиной для других устройств, что не всегда допустимо. Отметим также, что далеко не все устройства способны отвечать на транзакции без тактов ожидания, так что реальные цифры будут скромнее.
Итак, для выхода на максимальную производительность обмена устройства PCI сами должны быть ведущими устройствами шины, причем способными генериро$ вать пакетные циклы. Поддержку пакетного режима имеют далеко не все устрой$ ства PCI, а у имеющих, как правило, есть существенные ограничения на макси$ мальную длину пакета. Радикально повысить пропускную способность позволяет переход на частоту 66 МГц и разрядность 64 бита, что обходится недешево. Для того чтобы на шине могли нормально работать устройства, критичные к времени доставки данных (сетевые адаптеры, устройства, участвующие в записи и воспро$ изведении аудио$видеоданных и др.), не следует пытаться выжать из шины ее де$ кларированную полосу пропускания полностью. Перегрузка шины может привести, например, к потере пакетов из$за несвоевременности доставки данных. Заме$ тим, что адаптер Fast Ethernet (100 Мбит/с) в полудуплексном режиме занимает полосу около 13 Мбайт/с (10% декларируемой полосы обычной шины), а в полно$
дуплексном — уже 26 Мбайт/с. Адаптер Gigabit Ethernet даже в полудуплексном режиме вписывается в полосу шины уже с натяжкой (он «выживает» лишь за счет больших внутренних буферов), для него больше подходит 64 бит / 66 МГц. Суще$ ственное повышение пиковой скорости и эффективной пропускной способности дает переход на PCI$X с более высокими тактовыми частотами (PCI$X66, PCI$ X100, PCI$X133) и быстрой записью в память (PCI$X266 и PCI$X533).
Говоря о пропускной способности шины и эффективной скорости обмена с уст$ ройствами PCI, следует помнить об издержках, вносимых дополнительными мос$ тами PCI/PCI. Устройство, находящееся на дальней шине, получит меньшую про$ пускную способность, чем устройство, находящееся сразу за главным мостом и для которого справедливы вышеприведенные рассуждения. Это обусловлено механиз$ мом работы моста — транзакции через мост выполняются в несколько этапов (см. главу 4).
Прерывания PCI: INTx#, PME#, MSI и SERR#
Устройства PCI имеют возможность сигнализации об асинхронных событиях с помощью прерываний. На шине PCI возможны четыре типа сигнализации пре$ рываний:
традиционная проводная сигнализация по линиям INTx;
проводная сигнализация событий управления энергопотреблением по линии
PME#;
сигнализация с помощью сообщений — MSI;
сигнализация фатальной ошибки по линии SERR#.
В данной главе рассматриваются все эти типы сигнализации, а также общая кар$ тина поддержки аппаратных прерываний в PC$совместимых компьютерах.
Аппаратные прерывания в PC совместимых компьютерах
Аппаратные прерывания обеспечивают реакцию процессора на события, происхо$ дящие асинхронно по отношению к исполняемому программному коду. Прерыва$ ния в процессорах x86, используемых в PC$совместимых компьютерах, подробно рассмотрены в литературе [2]. Напомним, что аппаратные прерывания делятся на маскируемые и немаскируемые. Процессор x86 по сигналу прерывания приоста$ навливает выполнение текущего потока инструкций, сохраняя в стеке состояние (флаги и адрес возврата), и выполняет процедуру обработки прерывания. Конк$ ретная процедура обработки выбирается из таблицы прерываний по вектору пре рывания — однобайтному номеру элемента в данной таблице. Вектор прерывания доводится до процессора разными способами: для немаскируемого прерывания он фиксирован, для маскируемых прерываний его сообщает специальный контрол лер прерываний. Кроме аппаратных прерываний у процессоров x86 имеются также внутренние прерывания — исключения (exceptions), связанные с особыми случая$ ми выполнения инструкций, и программные прерывания. Для исключений вектор
определяется самим особым условием, и под исключения фирмой Intel зарезерви$ рованы первые 32 вектора (0–31 или 00–1Fh). В программных прерываниях но$ мер вектора содержится в самой инструкции (программные прерывания — это лишь специфический способ вызова процедур по номеру, с предварительным сохране$ нием в стеке регистра флагов). Все эти прерывания используют один и тот же на$ бор из 256 возможных векторов. Исторически сложилось так, что векторы, исполь$ зуемые для аппаратных прерываний, пересекаются с векторами исключений и векторами для программных прерываний, используемых для вызовов сервисов BIOS и DOS. Таким образом, для ряда номеров векторов процедура, на которую ссылается таблица прерываний, должна в начале содержать программный код, определяющий, по какому поводу она вызвана: из$за исключения, аппаратного прерывания или же для вызова какого$то системного сервиса. Таким образом, про$ цедура, собственно и обеспечивающая реакцию процессора на то самое асинхрон$ ное событие, будет вызвана только после ряда действий по идентификации источ$ ника прерываний. Здесь еще заметим, что один и тот же вектор прерывания может использоваться и несколькими периферийными устройствами — это так назы$ ваемое разделяемое использование прерываний, которое подробно обсуждается ниже.
Вызов процедуры обслуживания прерываний в реальном и защищенном режимах процессора существенно различается:
в реальном режиме таблица прерываний содержит 4$байтные дальние указате ли (сегмент и смещение) на соответствующие процедуры, которые вызываются дальним вызовом (Call Far с предварительным сохранением флагов). Размер (256 × 4 байт) и положение таблицы (начинается с адреса 0) фиксированы;
в защищенном режиме (и в его частном случае — режиме V86) таблица содер$ жит 8$байтные дескрипторы прерываний, которые могут быть шлюзами преры$ ваний (Interrupt Gate), ловушек (Trap Gate) или задач (Task Gate). Размер таблицы может быть уменьшен (максимальный — 256 × 8 байт), положение таб$ лицы может меняться (определяется содержимым регистра IDT процессора). Код обработчика прерываний должен быть не менее привилегированным, чем код прерываемой задачи (иначе сработает исключение защиты). По этой причине обработчики прерываний должны работать на уровне ядра ОС (на нулевом уров$ не привилегий). Смена уровня привилегии при вызове обработчика приводит к дополнительным затратам времени на переопределение стека. Прерывания, вызывающие переключение задач (через Task Gate), расходуют значительное время на переключение контекста — выгрузку регистров процессора в сегмент состояния старой задачи и их загрузку из сегмента состояния новой.
Номера векторов, используемых для аппаратных прерываний в операционных си$ стемах защищенного режима, отличаются от номеров, используемых в ОС реаль$ ного режима, чтобы исключить их конфликты с векторами, используемыми для исключений процессора.
На немаскируемое прерывание (NMI — Non$Maskable Interrrupt) процессор реаги$ рует всегда (если обслуживание предыдущего NMI завершено); этому прерыва$
нию соответствует фиксированный вектор 2. Немаскируемые прерывания в PC используются для сигнализации о фатальных аппаратных ошибках. Сигнал на линию NMI приходит от схем контроля памяти (четности или ECC), от линий кон$ троля шины ISA (IOCHK) и шины PCI (SERR#). Сигнал NMI блокируется до входа процессора установкой в 1 бита 7 порта 070h, отдельные источники разрешаются
иидентифицируются битами порта 061h:
бит 2 R/W — ERP — разрешение контроля ОЗУ и сигнала SERR# шины PCI;
бит 3 R/W — EIC — разрешение контроля шины ISA;
бит 6 R — IOCHK — ошибка контроля на шине ISA (сигнал IOCHK#);
бит 7 R — PCK — ошибка четности ОЗУ или сигнал SERR# на шине PCI.
Реакция процессора на маскируемые прерывания может быть задержана сбросом его внутреннего флага IF (инструкция CLI запрещает прерывания, STI — разреша$ ет). Маскируемые прерывания используются для сигнализации о событиях в уст$ ройствах. По возникновении события, требующего реакции, адаптер (контроллер) устройства формирует запрос прерывания, который поступает на вход контролле ра прерываний. Задача контроллера прерываний — довести до процессора запрос прерывания и сообщить вектор, по которому выбирается программная процедура обработки прерываний.
Процедура обработки прерывания от устройства должна выполнить действия по обслуживанию данного устройства, включая сброс его запроса для обеспечения возможности реакции на следующие события, и послать команды завершения в кон$ троллер прерываний. Вызывая процедуру обработки, процессор автоматически сохраняет в стеке значение всех флагов и сбрасывает флаг IF, что запрещает мас$ кируемые прерывания. При возврате из этой процедуры (по инструкции IRET) процессор восстанавливает сохраненные флаги, в том числе и установленный (до прерывания) IF, что снова разрешает прерывания. Если во время работы обработ$ чика прерываний требуется реакция на иные прерывания (более приоритетные), то в обработчике должна присутствовать инструкция STI. Особенно это касается длинных обработчиков; здесь инструкция STI должна вводиться как можно рань$ ше, сразу после критической (не допускающей прерываний) секции. Следующие прерывания того же или более низкого уровня приоритета контроллер прерыва$ ний будет обслуживать только после получения команды завершения прерывания EOI (End Of Interrupt).
В IBM PC$совместимых компьютерах применяется два основных типа контрол$ леров прерываний:
PIC (Peripheral Interrupt Controller) — периферийный контроллер прерываний, программно совместимый с «историческим» контроллером 8259A, применяв$ шимся еще в первых моделях IBM PC. Со времен IBM PC/AT применяется связка из пары каскадно соединенных PIC, позволяющая обслуживать до 15 ли$ ний запросов прерываний;
APIC (Advanced Peripheral Interrupt Controller) — усовершенствованный пери$ ферийный контроллер прерываний, введенный для поддержки мультипроцес$
сорных систем в компьютеры на базе процессоров 4–5 поколений (486 и Pen$ tium) и используемый поныне для более поздних моделей процессоров. Кроме поддержки мультипроцессорных конфигураций современный APIC позволяет увеличивать число доступных линий прерываний и обрабатывать запросы пре$ рываний от устройств PCI, посылаемые через механизм сообщений (MSI). Ком$ пьютер, оснащенный контроллером APIC, обязательно имеет возможность фун$ кционировать и в режиме, совместимом со стандартной связкой пары PIC. Этот режим включается по аппаратному сбросу (и включению питания), что позво$ ляет использовать старые ОС и приложения MS DOS, «не знающие» APIC и мультипроцессирования.
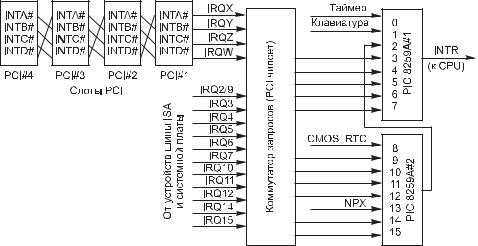
Традиционная схема формирования запросов прерываний с использованием пары PIC изображена на рис. 3.1.
Рис. 3.1. Коммутация запросов прерываний
На входы контроллеров прерываний поступают запросы от системных устройств (клавиатура, системный таймер, CMOS$таймер, сопроцессор), периферийных кон$ троллеров системной платы и карт расширения. Традиционно все линии запросов, не занятые перечисленными устройствами, присутствуют на всех слотах шины ISA/ EISA. Эти линии обозначаются как IRQx и имеют общепринятое назначение (табл. 3.1). Часть этих линий отдается в распоряжение шины PCI. В таблице отра$ жены и приоритеты прерываний — запросы расположены в порядке их убывания. Номера векторов, соответствующих линиям запросов контроллеров, система прио$ ритетов и некоторые другие параметры задаются программно при инициализации контроллеров. Эти основные настройки остаются традиционными для обеспече$ ния совместимости с программным обеспечением, но различаются для ОС реаль$ ного и защищенного режимов. Так, например, в ОС Windows базовые векторы для ведущего и ведомого контроллеров — 50h и 58h соответственно.