12 Статистическое кодирование. Кодирование алфавита источника информации кодом Фано-Шеннона и Хаффмена. Избыточность, коэффициент сжатия и информативность сообщений
Энтропия источника максимальна и Hмакс = log2k, если знаки равновероятны и независимы. В остальных случаях энтропия Н < 1оg2k. Следовательно, количество информации, приходящееся на один знак, обычно меньше того количества информации, которое мог бы этот знак нести. Иными словами, информационная нагрузка на знак часто оказывается меньше максимально возможной. Степень недоиспользования информационных возможностей сообщения характеризуется избыточностью, то есть наличием в сообщении большего числа знаков, чем это минимально необходимо для передачи определенного количества информации.
Численно
избыточность
x
определяется относительной разностью
максимально возможной и реальной
энтропии:
![]() ,
(16) где отношение
,
(16) где отношение![]() ,
а
,
а![]() (17)
Ксж
– коэффициент сжатия.
(17)
Ксж
– коэффициент сжатия.
Избыточность изменяется от 0 до 1. Ее численное значение показывает, насколько можно сократить объем сообщения без потери информации за счет более рационального использования знаков источника. Причинами избыточности являются неравные вероятности появления знаков на выходе источника и наличие вероятностных связей между ними.
Для
сравнения между собой различных
источников сообщений применяется
система, содержащейся в сообщении,
определяется через изменение энтропии
рассматриваемой системы, обусловленное
получением сообщения:
![]() , (1),
гдеНapr
и Нaps
– соответственно априорная и апостериорная
энтропия системы. Априорная энтропия
полностью характеризуется распределением
вероятностей состояний системы с учетом
статистических связей.
, (1),
гдеНapr
и Нaps
– соответственно априорная и апостериорная
энтропия системы. Априорная энтропия
полностью характеризуется распределением
вероятностей состояний системы с учетом
статистических связей.
Апостериорная энтропия характеризует ту неопределенность системы, которая остается после приема сообщений. Если сообщение однозначно определяет состояние системы, то Нaps = 0, в противном случае Нaps > 0.
Количественной
мерой неопределенности состояния
системы служит энтропия,
которая полностью определяется законом
распределения вероятностей состояний
случайной системы. Если знаки на выходе
К-значного
источника встречаются равновероятно
и взаимонезависимо, то количество
информации, бит/знак, переносимое одним
знаком максимально, определяется из
соотношения
![]() .
Если знакиК
– значного источника встречаются на
выходе неравновероятно и независимо
друг от друга, то энтропия рассчитывается
по формуле
.
Если знакиК
– значного источника встречаются на
выходе неравновероятно и независимо
друг от друга, то энтропия рассчитывается
по формуле
![]() .
.
Код Фано-Шеннона
Кодирование
сообщений, при котором достигается
наибольшая скорость передачи информации,
называется эффективным или статистическим.
Эффективность кодирования тем выше,
чем меньше отличается средняя длина
кодовой комбинации
![]() от величиныH(x)/log2
m,
где m
– основание кода. Задача статистического
кодирования состоит в том, чтобы
преобразовать последовательность
знаков сообщения с избыточностью в
последовательность, не имеющую
избыточности, либо имеющую значительно
меньшую избыточность. Если отдельные
знаки сообщения следуют независимо
друг от друга, то избыточность может
быть уменьшена (или устранена полностью)
при кодировании путем представления
наиболее вероятных знаков сообщения
короткими кодовыми комбинациями, а
менее вероятных – более длинными.
Получаемый при этом код является
неравномерным, кодовые комбинации для
различных знаков имеют разные длины.
от величиныH(x)/log2
m,
где m
– основание кода. Задача статистического
кодирования состоит в том, чтобы
преобразовать последовательность
знаков сообщения с избыточностью в
последовательность, не имеющую
избыточности, либо имеющую значительно
меньшую избыточность. Если отдельные
знаки сообщения следуют независимо
друг от друга, то избыточность может
быть уменьшена (или устранена полностью)
при кодировании путем представления
наиболее вероятных знаков сообщения
короткими кодовыми комбинациями, а
менее вероятных – более длинными.
Получаемый при этом код является
неравномерным, кодовые комбинации для
различных знаков имеют разные длины.
При декодировании на приемной стороне поступающую последовательность необходимо однозначно разделить на кодовые комбинации. Для этого необходимо, чтобы ни одна более короткая комбинация не являлась началом более длинной комбинации (свойство неприводимости). Например, если один из знаков сообщения закодирован двоичным кодом в виде последовательности 01101, то ни один из ее префиксов, то есть 0110, 011, 01 и 0 не должен применяться для кодирования других знаков сообщения.
На возможность такого кодирования, учитывающего статистические свойства сообщений, указал К. Шеннон, а удобный алгоритм кодирования предложил Р. Фано. Алгоритм статистического кодирования Фано-Шеннона заключается в следующем:
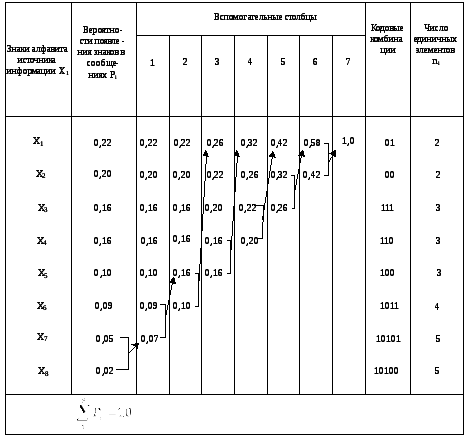
1 Подлежащие кодированию знаки сообщений располагаются в порядке убывания вероятностей их появления (таблица 4).
|
Знаки алфавита источника информации хi |
Вероятности знаков в сообщениях Pi |
Единичные элементы кодовых комбинаций |
Кодовые комбинации |
Число единичных элементов ni |
Средняя длина кодовой комбинации
| ||||
|
1 |
2 |
3 |
4 |
5 | |||||
|
x1 |
0,30 |
0 |
1 |
|
|
|
01 |
2 |
|
|
x2 |
0,17 |
0 |
0 |
|
|
|
00 |
2 |
|
|
x3 |
0,15 |
1 |
1 |
1 |
|
|
111 |
3 |
|
|
x4 |
0,12 |
1 |
1 |
0 |
|
|
110 |
3 |
2,74 |
|
х5 |
0,11 |
1 |
0 |
0 |
|
|
100 |
3 |
|
|
х6 |
0,09 |
1 |
0 |
1 |
1 |
|
1011 |
4 |
|
|
х7 |
0,04 |
1 |
0 |
1 |
0 |
1 |
10101 |
5 |
|
|
x8 |
0,02 |
1 |
0 |
1 |
0 |
0 |
10100 |
5 |
|
|
| |||||||||
3 Знаки, входящие в каждую из групп, вновь разбиваются на две группы с примерно равными суммарными вероятностями.
Группе знаков сообщений с большей суммой вероятностей в качестве второго элемента кодовой комбинации приписывается 1, а группе знаков сообщений с меньшей суммой вероятностей – 0.
4 Этот
процесс продолжается, пока в каждой из
групп не останется по одному знаку.
Энтропия данного источника информации
Н
= 2,6948 бит/знак и меньше
![]() = 2,74 ед. элем./знак
(имп./знак).
= 2,74 ед. элем./знак
(имп./знак).
Это
получилось потому, что вероятности
появления знаков на выходе источника
не удовлетворяют условию
![]() .
При невыполнении этого условия разбитие
на строго равномерные группы и подгруппы
невозможно и тогда
.
При невыполнении этого условия разбитие
на строго равномерные группы и подгруппы
невозможно и тогда![]() >Н(х).
Особенно заметным может быть снижение
эффективности статистического кодирования
при небольшом числе знаков и значительном
отличии их вероятностей. В таких случаях
увеличение эффективности достигается
путем кодирования не отдельных знаков,
а укрупненных блоков, которые представляют
собой набор всех возможных комбинаций
из 2, 3 и более знаков.
>Н(х).
Особенно заметным может быть снижение
эффективности статистического кодирования
при небольшом числе знаков и значительном
отличии их вероятностей. В таких случаях
увеличение эффективности достигается
путем кодирования не отдельных знаков,
а укрупненных блоков, которые представляют
собой набор всех возможных комбинаций
из 2, 3 и более знаков.
Код Хаффмена
Статистический
код Хаффмена по своим идеям аналогичен
статистическому коду Фано-Шеннона.
Однако алгоритм кодирования иной. Знаки
алфавита сообщений выписываются в
основной столбец в порядке убывания
вероятностей. Два последних знака
объединяются в один вспомогательный,
которому присваивается суммарная
вероятность. Вероятность знаков, не
участвовавших в объединении, и полученная
суммарная вероятность снова располагаются
в порядке убывания вероятностей во
вспомогательном столбце, а два последних
знака опять объединяются. Процесс
продолжается до тех пор, пока не будет
получен единственный знак с вероятностью,
равной единице (таблица 6).