

Ковалевский. Книжки по геостатистике / EAGE_Kovalevsky_SLTRU_2011_Geological_Modelling_on_the_Base_of_Geostatistics
.pdfРис. 45. Стохастическая интерполяция скважинных значений APS.
Рис. 46. Последовательно – гистограммы, горизонтальные вариограммы, вертикальные вариограммы. Красные линии – для исходных скважинных данных, зеленые линии – для куба стохастической реализации.
77

В чем мы убедились в результате последнего расчета? Мы убедились в том, что в достаточно типичной ситуации (при интерполяции скважинных данных) мы не смогли получить приемлемый результат. Основной причиной нашей неудачи является, по-видимому, категориальный характер геологической среды. Что делать, отказаться от геостатистики? Ни в коем случае, поскольку идея расчета стохастических реализаций чрезвычайно ценна! Геостатистику надо «спасать», она стоит того.
Для «спасения» геостатистики в ситуациях, подобных вышеописанной, предложено два подхода. Первый подход – разделение среды на категории посредством индикаторного стохастического моделирования. Второй подход – формальное превращение исходной гистограммы в гауссовскую посредством преобразования «Normal Score». Мы рассмотрим сначала первый подход, а затем второй.
5.5. Последовательное индикаторное стохастическое моделирование (ПИСМ)
Индикаторное стохастическое моделирование решает задачу разделения объема среды на категории пород. При этом каждому из многих миллионов элементарных объемов присваивается целый индекс той или иной категории, например «1» – глины, «2» – песчаники, «3» – известняки и т.д. Мы рассчитываем, что после разделения среды на категории гистограммы скважинных значений целевого параметра (APS, пористости и т.п.) в пределах каждой из категорий будут похожи на гауссовскую. Реализации целевого параметра в пределах выделенных категорий воспроизведут эти гистограммы, что позволит нам принять полученное решение.
Исходное состояние у нас следующее. Мы имеем пространственную стратиграфическую сетку и значения индексов категорий в ячейках, которые лежат на траекториях скважин. На основании этих данных нам необходимо рассчитать значения индексов категорий во всех ячейках нашей сети.
Отметим, что число используемых категорий не должно быть большим. В противном случае уменьшается приходящийся на одну категорию объем исходных данных, от чего страдает качество вариограмм. Кроме того, чем больше категорий, тем больше у нас будет искусственных контрастов в значениях целевого параметра, так как последние рассчитываются в пределах категорий независимо и не коррелируют. Очень часто среду разделяют только на две категории пород – «коллектор» и «неколлектор», после чего реализации пористости (если решается задача интерполяции пористости) рассчитывают только в коллекторе.
Алгоритм ПИСМ позволяет разделять объем среды только на две категории. Поэтому, если число категорий больше двух, некоторые из них временно объединяют друг с другом таким образом, чтобы свести задачу к разделению среды именно на две категории. На следующем этапе выделенную в пространстве одну объединенную категорию разделяют на две подкатегории, и так далее. С учетом сказанного дополним характеристику исходного состояния: значения индексов в ячейках на траекториях скважин имеют значения или 0, или 1.
Описание метода ПИСМ мы дадим на примере двумерной сетки. В трехмерном случае все делается точно так же. Исходное состояние показано на рис. 47: имеется сетка, в некоторых ячейках которой стоят известные (скважинные) значения индексов – 0 или 1.
78

Рис. 47. Последовательный обход узлов сетки по случайной траектории.
Первое, что мы делаем при индикаторном моделировании – мы рассчитываем вариограмму индикатора. Однако надо иметь в виду, что никакого «вариограммного облака» (как это было на рис. 13) мы не получим. Усредняемые точки будут лежать на двух уровнях – на уровне 0 и на уровне 0.5 (рис. 48). Кривая (экспериментальная вариограмма), рассчитанная в результате осреднения точек на двух уровнях, весьма условна.
Рис. 48. Экспериментальная индикаторная вариограмма.
Индикаторные вариограммы всегда крутые и аппроксимируются или сферической, или экспоненциальной моделью. Понятно, что плавно изменяться значения индикатора не могут. Легко показать, что порог индикаторной вариограммы равен произведению P0 (доли в пространстве категории 0) на P1 (доли категории 1).
Алгоритм ПИСМ в основных чертах повторяет алгоритм ПГСМ (рис. 49). Мы последовательно обходим точки на сетке (те, в которых у нас нет значений) по случайной траектории. В каждой очередной точке мы рассчитываем значение кригинга, используя для этого известные данные
79
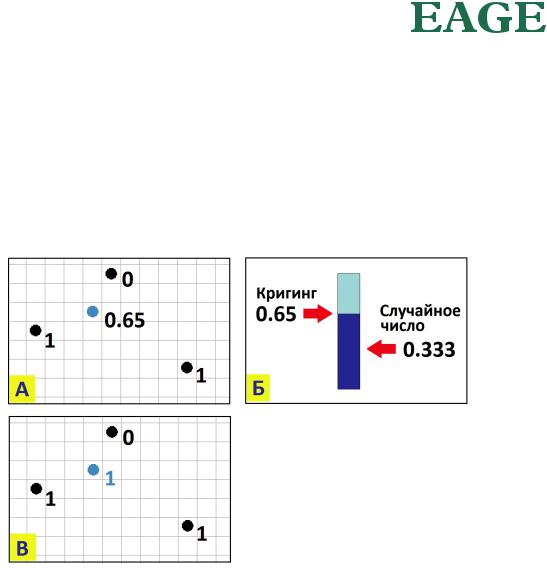
(рис. 49 а). Полученное значение кригинга (в нашем примере это 0.65) мы интерпретируем как вероятность иметь в рассматриваемой точке категорию «1». Далее мы реализуем эту вероятность. Для этого мы генерируем случайное число из равномерного распределения на интервале [0,1]. Если это случайное число оказывается меньше значения кригинга, в рассматриваемую точку заносится значение 1; в противном случае в рассматриваемую точку заносится значение 0. Определенное таким образом значение присоединяется к числу известных данных, то есть получает статус «значение в скважине». После этого на сетке выбирается следующая случайная точка, которая не должна совпадать ни с одной из уже определенных. Для новой точки все повторяется, но с одним изменением – в расчете кригинга участвует уже на одну точку больше, чем на предыдущем шаге. После того, как мы заполняем значениями все ячейки сетки, расчет реализации индикатора считается завершенным.
Рис. 49. Расчет реализации методом ПИСМ: а – значение кригинга в очередной точке прогноза; б – случайное число, равномерно распределенное на интервале [0, 1], сравнивается со значением кригинга; в – если случайное число меньше значения кригинга, в точку заносится 1, в противном случае заносится 0.
Расчет следующей реализации начинается с того, что мы оставляет на плане только истинные исходные значения... (дальнейшее повторяет сказанное в отношении ПГСМ). Отметим только самое важное. Если наряду со скважинными данными у нас есть карта или куб вспомогательной переменной, то мы можем каждое значение на этой карте интерпретировать в терминах вероятности категории «1». После этого значение вероятности, рассчитанное на очередном шаге кригингом, мы можем по формуле Байеса сложить с вероятностью, определяемой картой, и получить суммарную вероятность в точке категории «1». И именно эту суммарную вероятность мы можем дальше реализовывать (выбрасывать случайное число и т.д.). В результате карта (куб) пространственного распределения категорий будет коррелировать с картой (кубом) вспомогательной переменной.
80
Покажем теперь, что можно получить при помощи индикаторного стохастического моделирования в нашем примере 3D.
5.6. Расчет реализаций параметра с разделением на категории
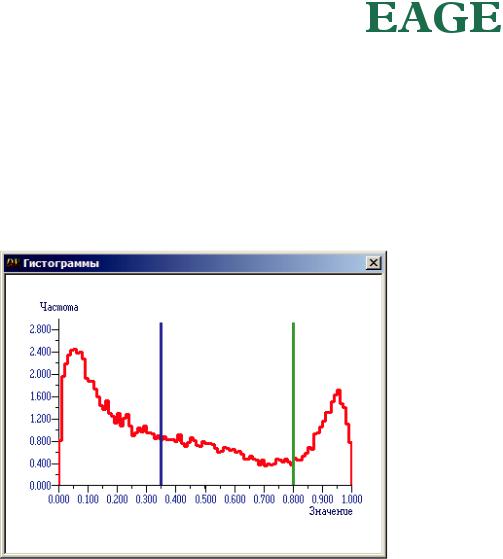
Прежде всего, мы должны разделить на категории пород элементарные объемы на скважинах. Посмотрим еще раз на распределение значений APS в объемах на траекториях скважин (рис. 50). Мы должны, посредством пороговых значений, разделить это распределение на фрагменты таким образом, чтобы каждый фрагмент стал похож на распределение Гаусса. Пороговые значения APS определят нужные нам категории.
Рис. 50. Разделение на категории распределения значений APS на скважинах.
Очень часто для разделения среды на коллектор и неколлектор используют значение APS равное 0.35 (синяя линия на рис. 50). Но сейчас такое разделение нас никак не устроит. Причина в том, что распределение APS в интервале «больше, чем 0.35» совершенно не похоже на гауссовское, и мы не сможем его воспроизвести при расчете реализаций. Прямо скажем, подходящий нам вариант разделения на категории на гистограмме на рис. 50 не просматривается.
Сделаем следующее замечание. Искусство применения геостатистики заключается не в том, чтобы в той или иной программной системе нажимать на кнопку «Рассчитать 100 реализаций». Искусство применения геостатистики (здесь мы выражаем частное мнение) заключается в умении находить и устранять причины деформации нормального распределения. Каждая негауссовская гистограмма говорит о чем-то важном и интересном, надо только понять, что именно она говорит. Даже наш самый первый пример с яблоками (п. 2.3) показывает, что, восстанавливая гауссовское распределение, мы не отходим от сути проблемы, а приближаемся к ней.
Что надо сделать в ситуации, показанной на рис. 50? Надо рассмотреть горизонты AV1 – AV5 по отдельности. У каждого горизонта будет своя гистограмма и свои причины ее деформации. Что-то
81

прояснится. Надо также посоветоваться с геологом. Он подскажет, какие должны быть категории пород. Вот тогда все получится.
Мы же, для иллюстрации метода ПИСМ, сделаем следующее. Мы выделим интервал APS «больше, чем 0.8», соответствующий коллекторам самого высокого качества (правее зеленой линии на рис. 50). На указанном участке гистограмма исходных значений близка к гауссовской.
Результат выделения в пространстве категории «высококачественный коллектор» показан на рис. 51. Это одна из реализаций, рассчитанных методом ПИСМ. Гистограмма и две вариограммы индикатора в исследуемом объеме (в сравнении с аналогичными характеристиками скважинных данных) показаны на рис. 52.
Рис. 51. Рассчитанная методом ПИСМ реализация категории «высококачественный коллектор». На вертикальном сечении показаны скважины, отстоящие от плоскости сечения не более чем на 100 м.
82

Рис. 52. Последовательно – гистограммы, горизонтальные вариограммы, вертикальные вариограммы. Красные линии – для исходных скважинных данных, зеленые линии – для куба стохастической реализации. Пунктиры на правом графике показывают пороги вариограмм, соответствующие долям категорий на скважинах и в объеме среды.
Что можно сказать о результатах расчета? Пропорции категорий в скважинных данных и в объеме среды практически совпадают. Радиусы вертикальных вариограмм совпадают. Радиусы горизонтальных вариограмм также примерно совпадают. Пропорции категорий на вертикалях близки к пропорциям в объеме среды, что видно по порогам вертикальных вариограмм. Пропорции категорий в слоях сетки отличаются от пропорций во всем объеме, причем для скважин сильнее, чем для куба. В целом результат разделения объема среды на две заданные категории выглядит вполне удовлетворительным.
После выделения в пространстве целевой категории мы переходим к интерполяции относящихся к ней скважинных данных APS. Но обратите внимание – мы получили в пространстве множество изолированных фрагментов (линз), относительно которых мы не имеем никаких скважинных данных. Как мы будем определять свойства в пределах этих фрагментов? Ответ простой – мы будем считать, что значения свойств в изолированных фрагментах коррелируют согласно нашим вариограммам. То есть, мы будем интерполировать скважинные данные (в отношении целевой категории) в сплошной среде, но результат возьмем только в пределах нужной нам категории. Предположение о коррелированности свойств изолированных фрагментов есть некоторая «натяжка», но на нее закрывают глаза.
На рис. 53 показана реализация параметра APS в пределах категории «высококачественный коллектор». На рис. 54 показаны соответствующие гистограммы и вариограммы. При моделировании радиус горизонтальной вариограммы значений APS задавался равным 750 м, то есть как рассчитанный по всем (то есть не фильтрованным) скважинным значениям APS. С этой небольшой оговоркой можно заключить, что гистограмма и вариограммы интерполированных значений соответствуют аналогичным характеристикам исходных данных. Мы получили то, что хотели. Результат интерполяции значений APS в пределах категории «высококачественный коллектор» нас вполне устраивает.
83

Рис. 53. Стохастическая интерполяция скважинных значений APS в пределах категории «высококачественный коллектор».
Рис. 54. Последовательно – гистограммы, горизонтальные вариограммы, вертикальные вариограммы. Красные линии – для исходных скважинных данных, синие линии – для реализации APS. Все – в пределах категории «высококачественный коллектор».
84

Таким же образом мы должны проинтерполировать скважинные данные в пределах всех других категорий. Но, напомним, без серьезного анализа (выходящего за рамки данного курса) никакие другие категории в нашем примере мы выделить не смогли. Поэтому мы вынуждены завершить описание интерполяции с использованием разделения на категории и перейти к обсуждению второго «спасательного круга» геостатистики – преобразования «Normal Score (NS)». Метод NS позволит нам получить желаемый результат.
5.7. Расчет реализаций параметра с использованием преобразования «Normal Score»
Вернемся в исходную точку. Наша проблема состоит в том, что распределение известных значений параметра (на скважинах) является негауссовским. В этой ситуации формальный расчет стохастических реализаций коренным образом меняет исходную гистограмму, что нас никак не устраивает. Разделение среды на категории в принципе позволяет решить проблему должным образом, но этот путь, во-первых, требует глубокого анализа исходных данных и, во-вторых, является очень сложным технически. Даже в демонстрационном примере мы не смогли пройти его до конца.
Но есть еще и второй путь решения той же проблемы, гораздо более легкий. Он состоит в том, что мы просто меняем шкалу, при помощи которой измеряется наш параметр (APS, пористость и т.п.). Новая шкала выбирается таким образом, чтобы значения параметра на скважинах, измеренные в новых единицах, оказались распределенными по Гауссу. Отсюда и название – метод нормального преобразования («Normal Score»). Дальше мы действуем на совершенно законных основаниях – по известным значениям параметра (в новых единицах) рассчитываем вариограмму и выполняем стохастическую интерполяцию. Последняя, как мы знаем, сохраняет гауссовское распределение (в новых единицах). На заключительном этапе выполняется обратное преобразование NS, и мы получаем значения в объеме, гистограмма которых точно совпадает с гистограммой исходных данных.
Описанный процесс (и его издержки) легче всего пояснить при помощи рис. 55. Для простоты показан пример 1D – интерполяция точечных значений (пористости) вдоль координатной оси Х. Рис. 55 разделен на четыре фрагмента – «а», «б», «в» и «г». Прокомментируем их последовательно.
Фрагмент «а». В правой части показаны неизвестные нам истинные значения пористости (непрерывная линия) вдоль координаты X. У нас есть только значения пористости в отдельных точках (данные по скважинам). На вертикальной оси показана исходная равномерная шкала пористости P (с одинаковыми интервалами). Рядом со шкалой пористости помещена гистограмма известных значений пористости – она показывает частоту, с которой точки попадают в интервалы на шкале P. Гистограмма имеет двугорбый вид – у нас много высоких значений пористости (песчаные тела), много низких значений (глинистые тела), и почти нет промежуточных значений.
В левой части фрагмента «а» помещена измененная, неравномерная шкала пористости P*(с интервалами разной ширины). Интервалы на шкале изменены так, чтобы в центральный интервал попадало больше всего точек, а дальше, по мере удаления от центра, число точек, попадающих в интервалы, постепенно уменьшалось (точно так, как в распределении Гаусса).
Фрагмент «б». Значения пористости вдоль координаты X показаны теперь в единицах P*. В новых единицах часть точек, попадавших в прежние максимумы, смещается ближе к среднему значению.
85

При этом разница между песчаниками и глинами в единицах P* уменьшается, а малые флуктуации пористости в пределах песчаников и глин, наоборот, увеличиваются. Но зато теперь известные значения (в единицах P*) распределены по Гауссу. Для известных точечных значений (в единицах P*) рассчитывается вариограмма.
Фрагмент «в». На основании полученной вариограммы выполняется стохастическая интерполяция известных точечных значений. Результат получается в единицах P*. Гистограмма и вариограмма интерполированных значений в точности соответствует гистограмме и вариограмме данных в единицах P*.
Фрагмент «г». Производится обратное преобразование интерполированных значений к исходным единицам P. После этого гистограмма интерполированных значений точно совпадает с исходной двугорбой гистограммой данных. Но вариограмма интерполированных значений не воспроизводит исходную вариограмму данных, поскольку песчаные тела получают размер, близкий к размеру малых флуктуаций пористости в песчаниках и глинах.
86