

AISD
.pdfвого поддерева (для достижения этого |
нонаправленном |
списке, |
т.е. |
придется |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
элемента необходимо перейти в следую- |
перебирать |
N/2 элементов.Наибольшего |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
щий узел по правой ветви, а затем дви- |
эффекта использования дерева достига- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
гаться только по левой ветви этого узла |
ется в том случае, когда дерево сбаланси- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
до тех пор, пока очередная ссылка не |
ровано. В этом случае для поиска придет- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
будет равна nil. |
|
|
|
ся |
|
перебрать |
|
не |
больше |
log 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Предшественником удаляемого узла (12) |
Nэлементов.Строго |
|
сбалансированное |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
является самый правый узел левого под- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
дерево - это дерево, в котором каждый |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
дерева (11). Преемником узла (12) - са- |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
узел имеет левое и правое поддеревья, |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
мый левый узел правого поддерева (13). |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
отличающиеся по уровню не более чем на |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
Будем разрабатывать |
алгоритм для пре- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
единицу.Поиск элемента в бинарном де- |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
емника (узел 13), который будет постав- |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
реве называется бинарным поиском по |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
лен на место удаляемого узла 12. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
дереву.Такое дерево называют деревом |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
Введем указатели: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
бинарного поиска.Суть поиска заключает- |
32. |
Понятие |
сортировки, |
ее |
эффек- |
|||||||||||||||||||||
p - рабочий указатель; |
|
|
|||||||||||||||||||||||||||
|
|
ся в следующем. Анализируем вершину |
тивность; |
классификация |
методов |
||||||||||||||||||||||||
q - отстает от р на один шаг; |
|
||||||||||||||||||||||||||||
|
очередного поддерева. Если ключ меньше |
сортировки |
|
|
|
|
|
|
|
|
|
||||||||||||||||||
v - указывает на преемника удаляемого |
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
информационного поля вершины, то ана- |
Сортировка - это расположение данных в |
||||||||||||||||||||||||||||
узла; |
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
лизируем левое поддерево, больше - пра- |
памяти в регулярном виде по выбранному |
||||||||||||||||||||||||
t - отстает от v на один шаг; |
|
||||||||||||||||||||||||||||
|
вое. |
|
|
|
|
|
|
|
|
|
параметру. Регулярность рассматривают |
||||||||||||||||||
s - на один шаг впереди v (указывает на |
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
31. Алгоритмы прохождения бинар- |
как |
возрастание |
(убывание) |
значения |
|||||||||||||||||||||||||
левого сына или пустое место). |
|
||||||||||||||||||||||||||||
|
ных деревьев |
|
|
|
|
|
|
параметра от |
начала |
к концу |
|
массива |
|||||||||||||||||
В итоге работы алгоритма на узел 13 дол- |
|
|
|
|
|
|
|
||||||||||||||||||||||
В зависимости от последовательности об- |
данных. |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
жен указывать указатель v, а указатель s |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
хода |
поддеревьев |
различают |
три |
вида |
Если сортируемые записи занимают боль- |
||||||||||||||||||||||||
- на пустое место (как показано на ри- |
|||||||||||||||||||||||||||||
обхода (прохождения) деревьев (рис.4.9): |
шой |
объем памяти, |
то их перемещение |
||||||||||||||||||||||||||
сунке). |
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
Рис. 4.9. Прохождение бинарных деревьев |
требует больших затрат. Для того, чтобы |
||||||||||||||||||||||||
q = nil |
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
1. Сверху вниз А, В, С. |
|
|
|
|
их уменьшить, |
сортировку производят в |
|||||||||||||||||||
p = tree |
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
2. Слева направо или симметричное про- |
таблице адресов ключей, то есть делают |
||||||||||||||||||||||||
while (p <> nil) and (k(p) <> key) do |
|
||||||||||||||||||||||||||||
|
хождение В, А, С. |
|
|
|
|
|
перестановку указателей, а сам массив не |
||||||||||||||||||||||
q = p |
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
3. Снизу вверх В, С, А. |
|
|
|
|
перемещается. |
Это |
- |
метод |
сортировки |
||||||||||||||||
if key < k(p) then |
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
Неформальный |
итерационный |
алгоритм |
таблицы адресов. |
|
|
|
|
|
|
|
|||||||||||||||||
|
|
p = left(p) |
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
обхода дерева: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
else |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
1. Если обработка производится после 1- |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
p = right(p) |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
го захода в узел, то это – обход сверху |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
endif |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
вниз.ABDECF |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
endwhile |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
2. Если обработка производится после 2- |
|
При |
сортировке |
|
могут |
встретиться |
|||||||||||||||||||
if p = nil then „Ключненайден‟ |
|
|
|
||||||||||||||||||||||||||
|
го |
захода |
в |
узел, |
то |
это |
– обход |
слева |
|
|
|||||||||||||||||||
|
одинаковые ключи. В этом случае жела- |
||||||||||||||||||||||||||||
|
return |
|
|
|
|||||||||||||||||||||||||
|
|
|
|
направо.DBEACF |
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
тельно |
после |
сортировки |
расположить |
||||||||||||||||
endif |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
3. Если обработка производится после 3- |
|||||||||||||||||||||||||
|
|
|
|
одинаковые ключи в том же порядке, что |
|||||||||||||||||||||||||
if left(p) = nil then v = right(p) |
|
||||||||||||||||||||||||||||
|
го |
захода |
в |
узел, |
то |
это |
– обход |
снизу |
|||||||||||||||||||||
|
и |
|
в |
|
|
исходном |
|
|
|
файле. |
|||||||||||||||||||
|
else if right(p) = nil |
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
вверх.DEBFCA |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
Это - устойчивая сортировка. |
|
|
|
|
|||||||||||||||||
|
then v = left(p) |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
Наиболее часто применяется второй спо- |
|
|
|
|
|||||||||||||||||||||||
|
|
|
Мы будем рассматривать только сорти- |
||||||||||||||||||||||||||
else |
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
|
соб. Ниже приведены рекурсивные алго- |
|
||||||||||||||||||||||||
|
|
|
|
ровки, не использующие дополнительную |
|||||||||||||||||||||||||
„Уnod(p) - два сына‟ |
|
|
|
||||||||||||||||||||||||||
|
|
|
ритмы прохождения бинарных деревьев. |
||||||||||||||||||||||||||
|
|
|
оперативную |
память. |
Такие |
сортировки |
|||||||||||||||||||||||
„Введем два указателя (t отстает от v на 1 |
|||||||||||||||||||||||||||||
|
Procedure pretrave (tree tnode) Begin if |
||||||||||||||||||||||||||||
|
называются «на том же месте». |
|
|
|
|||||||||||||||||||||||||
шаг, s - опережает)‟ |
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
tree <> nil then begin WriteL(Tree^.Info); |
|
|
|
|||||||||||||||||||||||
|
|
|
|
Эффективность |
|
сортировки |
можно |
||||||||||||||||||||||
|
|
t = p |
|
|
|
||||||||||||||||||||||||
|
|
|
Pretrave(Tree^.left); |
|
|
|
Pre- |
|
|
||||||||||||||||||||
|
|
|
|
|
|
рассматривать по нескольким критериям: |
|||||||||||||||||||||||
|
|
v = right(p) |
|
|
|
||||||||||||||||||||||||
|
|
trave(Tree^.right);End;end; |
|
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
время, |
затрачиваемое на |
сорти- |
|||||||||||||||||||
|
|
s = left(v) |
|
|
|
|
|
• |
|
||||||||||||||||||||
|
|
|
|
procedure |
intrave (tree: tnod) begin if |
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
ровку; |
|
|
|
|
|
|
|
|
||||||||||||||
while s <> nil do |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
tree |
<> |
|
nil |
then |
begin |
in- |
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
объем |
оперативной памяти, тре- |
|||||||||||||||||||||
|
t = v |
|
|
|
|
|
• |
|
|||||||||||||||||||||
|
|
|
|
trave(Tree^.left);writeLn(Tree^.info);intrav |
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
буемой для сортировки; |
|
|
|
|||||||||||||||||||
|
v = s |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
e(Tree^.right);end;end; |
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
время, |
затраченное |
программи- |
|||||||||||||||||
|
s = left(v) |
|
|
|
|
|
|
• |
|
||||||||||||||||||||
|
|
|
Рис. 4.10 Обход дерева А, В, С |
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
стом на написание программы. |
|||||||||||||||||||||
|
endwhile |
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
Поясним подробнее рекурсию |
алгоритма |
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
ift<>pthen |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
обхода дерева слева направо. |
|
|
|
Выделяем |
первый |
критерий. |
|
Эквива- |
||||||||||||||||||
„v не является сыном p‟ |
|
|
|
|
|
||||||||||||||||||||||||
|
Пронумеруем |
строки |
алгоритмаintrave |
|
|
||||||||||||||||||||||||
|
лентом затраченного на сортировку вре- |
||||||||||||||||||||||||||||
|
left(t) = right(v) |
|
|||||||||||||||||||||||||||
|
|
(tree): |
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
мени |
можно |
считать количество сравне- |
|||||||||||||||||
|
right(v) = right(p) |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
1 if tree <> ml |
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
ний и количество перемещений при вы- |
|||||||||||||||||||||
|
endif |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
2 |
then intrave (left(tree)) |
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
полнении сортировки. |
|
|
|
|
|
|||||||||||||||||
|
left(v) = left(p) |
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
3 |
|
print info (tree) |
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
Порядок |
числа сравнений |
и пе- |
|||||||||||||||||
endif |
|
|
|
|
|
|
|
|
|
|
• |
|
|||||||||||||||||
|
|
|
|
4 |
|
intrave (right (tree)) |
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
ремещений при сортировке лежит |
||||||||||||||||||
endif |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
5 |
endif |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
в пределах |
|
|
|
|
|
|
||||||||
if q = nil then „p - корень‟ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
6 |
return |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
от О (n log n) |
до О (n2); |
|
|
|
|||||||||||||
|
tree = v |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
Обозначимуказатели: t → tree; l → left; r |
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
О (n) - идеальный и недостижимый |
|||||||||||||||||||||||
else |
if p = left(q) |
|
|
|
|
||||||||||||||||||||||||
|
|
→ right |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
случай. |
|
|
|
|
|
|
|
|
|
|
|||||||||
|
then |
left(q) = v |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
На приведенном рис. |
4.11 |
проиллюстри- |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
Различают |
следующие методы |
сорти- |
||||||||||||||||||||||||
else |
right(q) = v |
|
|
|
|||||||||||||||||||||||||
|
|
рована |
последовательность |
вызова |
|
||||||||||||||||||||||||
|
|
ровки: |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
endif |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
процедурыintrave (tree) по мере обхода |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
строгие (прямые) методы; |
|
|||||||||||||||||||||
endif |
|
|
|
|
|
• |
|
|
|||||||||||||||||||||
|
|
|
|
узлов простейшего дерева, изображенно- |
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
улучшенные методы. |
|
|
|
|
||||||||||||||||||
freenode(p) |
|
|
|
|
|
• |
|
|
|
|
|
||||||||||||||||||
|
|
|
|
го на рис. 4. 10. |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
Строгие методы: |
|
|
|
|
|
|
||||||||||||
return |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
Рис. 4.11. Иллюстрация рекурсивной ра- |
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
метод прямого включения; |
|
|||||||||||||||||||||
|
|
|
|
|
|
• |
|
|
|||||||||||||||||||||
|
|
|
|
|
боты процедуры intrave (tree) при обхо- |
|
|
|
|||||||||||||||||||||
28. Эффективность поиска по бинар- |
|
• |
|
метод прямого выбора; |
|
|
|
||||||||||||||||||||||
де дерева на рис.4.10. |
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
метод прямого обмена. |
|
|
|
|||||||||||||||||||
ному дереву |
|
|
|
|
|
|
|
|
|
• |
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Эффективность |
|
строгих |
|
методов |
||||||||
Эффективность поиска по бинарному |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
примерно одинакова. |
|
|
|
|
|
|||||||||||||
дереву |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Назначение его в том, чтобы по заданно- |
|
|
|
|
|
|
|
|
|
|
|
35. Сортировка методом прямого об- |
|||||||||||||||||
му ключу осуществить поиск узла дерева. |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
мена (пузырьковая). |
|
|
|
|
||||||||||||||
Длительность операции зависит от струк- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
Оба разбиравшихся до этого метода мож- |
||||||||||||||||||
туры дерева. |
Действительно, дерево мо- |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
но тоже рассматривать как "обменные" |
||||||||||||||||||
жет быть вырождено в однонаправленный |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
сортировки. В данном же, однако, разделе |
||||||||||||||||||
список, как правое на рис. 5.8.Рис. 5.8. |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
описан метод, где обмен местами двух |
||||||||||||||||||
Бинарные деревья.В |
этом |
случае |
время |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
элементов представляет собой характер- |
||||||||||||||||||
поиска будет |
такое |
же, |
как и |
в од- |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||

нейшую особенность процесса. Изложенный ниже алгоритм прямого обмена основывается на сравнении и смене мест для пары соседних элементов и продолжении этого процесса до тех пор, пока не будут упорядочены все элементы.
Как и в упоминавшемся методе прямого выбора, мы повторяем проходы по массиву, сдвигая каждый раз наименьший элемент оставшейся последовательности к левому концу массива. Если мы будем рассматривать массивы как вертикальные, а не горизонтальные построения, то элементы можно интерпретировать как пузырьки в чане с водой, причем вес каждого соответствует его ключу. В этом случае при каждом проходе один пузырек как бы поднимается до уровня, соответствующего его весу (см. иллюстрацию на следующем слайде).
Такой метод широко известен под именем "пузырьковая сортировка".
Алгоритм: for i = 2 to n
for j = n to i step -1
if a(j) < a(j - 1) then
x = a(j - 1) a(j - 1) = a(j) a(j) = x
endif nextj
nexti return
В нашем случае получился один проход ―вхолостую‖. Чтобы лишний раз не просматривать элементы, а значит проводить сравнения, затрачивая на это время, можно ввести флажок fl, который остается в значенииfalse , если при очередном проходе не будет произведено ни одного обмена.
fl = true
for i = 2 to n
if fl = false then return endif
fl = false
for j = n to i step -1
if a(j) < a(j - 1) then fl = true
x = a(j - 1) a(j - 1) = a(j) a(j) = x
endif nextj
nexti return
Улучшением пузырькового метода является шейкерная сортировка, где после каждого прохода меняют направление во внутреннем цикле.
Эффективность алгоритма сортировки прямым обменом
Число сравнений Cmax = n(n-1)/2, порядок О(n2).
Число перемещений Мmax= 3Cmax= 3n(n-1)/2, порядок О(n2).
Если массив уже отсортирован и применяется алгоритм с флажком, то достаточно всего одного прохода по массиву, и тогда получаем минимальное число сравнений
Cmin = n - 1, порядок О(n), а перемещения вообще отсутствуют Сравнительный анализ прямых методов сортировок показывает, что обменная
"сортировка" в классическом виде представляет собой нечто среднее между сортировками с помощью включений и с помощью выбора. Если же в нее внесены приведенные выше усовершенствования, то для достаточно упорядоченных массивов пузырьковая сортировка даже имеет преимущество.
36. Быстрая сортировка
Относится к методам обменной сортировки. В основе лежит методика разделения ключей по отношению к выбранному.
Слева от 6 располагают все ключи с меньшими, а справа - с большими или равными 6.
Sub Sort (L, R)
i = L j = R
x = a((L + R) div 2) repeat
while a(i) < x do i = i + 1
endwhile
while a(j) > x do j = j - 1
endwhile
if i <= j then y = a(i) a(i) = a(j) a(j) = y
i = i + 1 j = j - 1
endif until i > j
if L < j then
sort (L, j)
endif
if i < R then
sort (i, R)
endif return
SubQuickSort
Sort (1, n) return
Эффективность алгоритмаQuickSort
Из всех существующих методов сортировки QuickSortсамый эффективный.
Его эффективность имеет порядок О(n log2 n)
37. Сортировка Шелла
В 1959 году Д. Шеллом было предложено усовершенствование сортировки с помощью метода прямого включения. Иллюстрация его сортировки с начальным шагом, равным 4, представлена на нижеследующем рисунке.
Сначала отдельно группируются и в группах сортируются элементы, отстоящие друг от друга на расстоянии 4. Такой процесс называется четверной сортировкой. В нашем примере 8 элементов, и каждая
группа состоит из двух элементов, то есть 1-й и 5-й элементы, 2-й и 6-й, 3-й и 7-й и, наконец, 4-й и 8-й элементы. После четверной сортировки элементы перегруппировываются - теперь каждый элемент группы отстоит от другого на 2 позиции - и вновь сортируются. Это называется двойной сортировкой. И наконец, на третьем проходе идет обычная или одинарная сортировка.
На первый взгляд можно засомневаться: если необходимо несколько процессов сортировки, причем в каждый включаются все элементы, то не добавят ли они больше работы, чем сэкономят? Однако, на каждом этапе либо сортируется относительно мало элементов, либо элементы уже довольно хорошо упорядочены и требуют сравнительно немного перестановок. Ясно, что такой метод в результате дает упорядоченный массив, и, конечно, сразу же видно, что каждый проход от предыдущих только выигрывает; также очевидно, что расстояния в группах можно уменьшать по разному, лишь бы последнее было единичным, ведь в самом плохом случае последний проход и сделает всю работу.
Приводимый ниже алгоритм не ориентирован на некую определенную последовательность расстояний и использует метод прямой вставки с условным переходом. При использовании метода барьера каждая из сортировок нуждается в постановке своего собственного барьера, поэтому приходится расширять массив с [0..N ] до
[-h1..N ].
Не доказано, какие расстояния дают наилучший результат, но они не должны быть множителями один другого. Д. Кнут предлагает такую последовательность шагов h (в обратном порядке): 1, 3, 7, 15, 31, …
То есть:
hm = 2hm-1 + 1, а количество шагов t = (log 2 n) - 1.
При такой организации алгоритма его эффективность имеет порядок O ( n1,2 )
Алгоритм сортировки Шелла
Обозначим
h[1..t] - массив размеров шагов
a[1..n] - сортируемый массив
k - шаг сортировки
x - значение вставляемого элемента
Subroutine ShellSort const t = 3
h(1) = 7
h(2) = 3
h(3) = 1 for m = 1 to t
k = h(m)
for i = 1 + k to n x = a(i)
for j = i - k to 1 step -k if x < a(j) then
a( j+k) = a(j) else goto L endif
next j
L: a(j+k) = x next i
next m return
38. Сортировка с помощью бинарного дерева
При обработке данных в ЭВМ важно знать и информационное поле элемента, и его размещение в памяти машины. Для этих целей используется сортировка. Итак, сортировка - это расположение данных в

памяти в регулярном виде по их ключам. |
v:=maketree(key); while p<>nil do begin |
1) |
метод прямого включения. |
|
|
|||||||||||||||
Регулярность рассматривают как возрас- |
q:=P; if key<k(p) then p:=left(p) else |
Число сравнений ключей Ci при i- м про- |
||||||||||||||||||
тание значения ключа от начала к концу в |
p:=right(p); end; if p=nil then begin wri- |
сеивании самое большее равно i-1, самое |
||||||||||||||||||
массиве.Различают следующие типы сор- |
teln('Этокорень'); tree:=v; end else if |
меньшее - 1; если предположить, что все |
||||||||||||||||||
тировок:• внутренняя сортировка - это |
key<k(q) then |
left(p):=v else righ(p):=v; |
перестановки из N ключей равновероят- |
|||||||||||||||||
сортировка, происходящая в оперативной |
end; |
|
|
|
|
|
ны, то среднее число сравнений = i/2. |
|||||||||||||
памяти машины• внешняя сортировка - |
При обходе дерева слева - направо |
Число же пересылок Mi=Ci+3 (включая |
||||||||||||||||||
сортировка |
во |
внешней |
памя- |
получаем отсортированный массив 20, 30, |
барьер). Минимальные оценки встречают- |
|||||||||||||||
ти.Схематичное представление двоично- |
35, 45, 60, 70, 82, 85, 86, 87, 88, 90. Эле- |
ся в случае уже упорядоченной исходной |
||||||||||||||||||
го дерева: имеется набор вершин, соеди- |
мент дерева заносится в массив при вто- |
последовательности элементов, наихуд- |
||||||||||||||||||
ненных стрелками. Из каждой вершины |
ром заходе в него (на рисунке вторые |
шие же оценки - когда они первоначально |
||||||||||||||||||
выходит не более двух стрелок (ветвей), |
заходы показаны зелеными стрелками). |
расположены в обратном порядке. В неко- |
||||||||||||||||||
направленных влево - вниз или вправо - |
Обходдереваслева - направо |
|
тором смысле сортировка с помощью |
|||||||||||||||||
вниз. Должна существовать единственная |
procedure InTree(tree); |
|
|
включения демонстрирует истинно естест- |
||||||||||||||||
вершина, в которую не входит ни одна |
begin |
if |
Tree |
= |
nil |
then |
венное поведение. Ясно, что приведенный |
|||||||||||||
стрелка - эта вершина называется корнем |
writе('Деревопусто') else with Tree^ do |
алгоритм |
описывает процесс |
устойчивой |
||||||||||||||||
дерева. В каждую из оставшихся вершин |
begin if left <> nil then InTree(left); if right |
сортировки: порядок элементов с равны- |
||||||||||||||||||
входит одна стрелка. |
|
|
|
|
<> nil then InTree(right); end; end; |
|
ми ключами при нем остается неизмен- |
|||||||||||||
Существует множество способов упорядо- |
|
|
|
|
|
|
ным. |
|
|
|
|
|
||||||||
чивания дерева. Рассмотрим один из них : |
39. Сравнительный анализ эффектив- |
Количество сравнений в худшем случае, |
||||||||||||||||||
«Левый» сын имеет ключ меньше, чем |
ности методов сортировки |
|
|
когда массив отсортирован противопо- |
||||||||||||||||
ключ "Отца" "Правый" сын имеет ключ |
При обработке данных важно знать ин- |
ложным образом, Cmax = n(n - 1)/2, т. е. |
||||||||||||||||||
больше, чем ключ «Отца»Получили би- |
формационное поле данных и размещение |
- О (n2). Количество перестановок Mmax |
||||||||||||||||||
нарное упорядоченное дерево с мини- |
их в машине. |
|
|
|
|
= Cmax + 3(n-1), т.е. - О (n2). Если же |
||||||||||||||
мальным числом уровней. Строго сбалан- |
Различают внутреннюю и внешнюю сор- |
массив уже отсортирован, то число срав- |
||||||||||||||||||
сированное дерево: дерево, в котором ле- |
тировку: |
|
|
|
|
|
нений и перестановок минимально: Cmin |
|||||||||||||
вое и правое поддерево имеют уровни, |
- внутренняя сортировка - сортировка в |
= n-1; Мmin = 3(n-1). |
|
|
|
|||||||||||||||
отличающиеся не более чем на единицу. |
оперативной памяти (по внутренним клю- |
2) |
метод прямого выбора. |
|
|
|
||||||||||||||
Рассмотрим |
принцип построения |
дерева |
чам); |
|
|
|
|
|
Число сравнений ключей Сi, очевидно, не |
|||||||||||
при занесении элементов в массив:Пусть |
- внешняя сортировка - сортировка во |
зависит от начального порядка ключей. |
||||||||||||||||||
в первоначально пустой массив заносятся |
внешней памяти (по внешним ключам). |
Можно сказать, что в этом смысле пове- |
||||||||||||||||||
последовательно поступающие элементы: |
Мы будем рассматривать методы сорти- |
дение этого метода менее естественно, |
||||||||||||||||||
70, 60, 85, 87, 90, 45, 30, 88, 35, 20, 86; |
ровки по внешним ключам; на том же |
чем поведение прямого включения. Для С |
||||||||||||||||||
Т.к. это еще пустое дерево, то ссылки left |
месте; методы устойчивой сортировки. |
при любом расположении ключей имеем: |
||||||||||||||||||
и right равны nil (left - указатель на лево- |
Сортировка - это расположение данных в |
С=n(n-1)/2 |
|
|
|
|
||||||||||||||
го сына (элемент), right - указатель на |
памяти в регулярном виде по их ключам. |
Порядок числа сравнений (эффективно- |
||||||||||||||||||
правого сына (элемент)). |
|
|
|
Регулярность рассматривают как возрас- |
сти), таким образом, O(n 2 ) |
|
|
|
||||||||||||
Четвертый из поступающих элементов 87. |
тание (убывание) значения ключа от на- |
Число перестановок минимально М min = |
||||||||||||||||||
Т.к. этот ключ больше ключа 70 (корень), |
чала к концу в массиве. |
|
|
3(n - 1) в случае изначально упорядочен- |
||||||||||||||||
то новая вершина должна размещаться на |
|
|
|
|
|
|
ных ключей и максимально, M max |
= 3(n - |
||||||||||||
правой ветви дерева. Чтобы определить |
|
|
|
|
|
|
1) + С, т.е. порядок O(n 2 ), если первона- |
|||||||||||||
ее место, спускаемся по правой стрелке к |
|
|
|
|
|
|
чально ключи располагались в обратном |
|||||||||||||
очередной вершине (с ключом 85), и если |
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
порядке. |
|
|
|
|
|
|||||||||
поступивший ключ больше 85, то новую |
|
|
|
|
|
|
|
|
|
|
|
|||||||||
Рис. 6.1. Сортировка. |
|
|
|
В худшем случае сортировка прямым вы- |
||||||||||||||||
вершину делаем правым сыном вершины с |
|
|
|
|||||||||||||||||
Если сортируемые записи занимают боль- |
|
|
|
2 |
|
для числа |
||||||||||||||
ключом 85 . |
|
|
|
|
|
бором дает порядок n , как |
||||||||||||||
|
|
|
|
|
шой объем |
памяти, то их перемещение |
сравнений, так и для числа перемещений. |
|||||||||||||
В рассмотренном примере ПРИНЦИП ПО- |
||||||||||||||||||||
требует больших затрат. Для того чтобы |
3) |
метод прямого обмена. |
|
|
|
|||||||||||||||
СТРОЕНИЯ ДЕРЕВА имеет следующий вид: |
|
|
|
|||||||||||||||||
их уменьшить, |
сортировку производят в |
Число сравнений Сmах = n(n-1)/2, O(n 2 ). |
||||||||||||||||||
если поступает очередной элемент масси- |
таблице адресов ключей, делают переста- |
Число перемещений Mmax=3Cmax=3n(n- |
||||||||||||||||||
ва, то начиная с корня дерева (в зависи- |
||||||||||||||||||||
новку указателей, т.е. сам массив не пе- |
l)/2, O(n 2 ). |
|
|
|
|
|||||||||||||||
мости от сравнения текущего элемента с |
ремещается. Это метод сортировки табли- |
Если массив уже отсортирован и применя- |
||||||||||||||||||
очередной вершиной) |
идем |
влево или |
||||||||||||||||||
цы адресов. |
|
|
|
|
ется алгоритм с флажком, |
то достаточно |
||||||||||||||
вправо от нее до тех пор, пока не найдем |
|
|
|
|
||||||||||||||||
При сортировке могут встретиться одина- |
всего одного прохода, и тогда получаем |
|||||||||||||||||||
подходящую |
вершину, |
к |
которой |
можно |
||||||||||||||||
ковые ключи. В этом случае при сорти- |
минимальное число сравнений |
|
|
|||||||||||||||||
подключить новую вершину с текущим |
|
|
||||||||||||||||||
ровке желательно расположить после сор- |
Cmin=n-l, |
O(n 2 ),а перемещения |
вообще |
|||||||||||||||||
ключом. |
В |
зависимости |
от |
результата |
тировки одинаковые ключи в том же по- |
отсутствуют. |
|
|
|
|
||||||||||
сравнения ключей, новую вершину дела- |
|
|
|
|
||||||||||||||||
рядке, что и в исходном файле. Это - ус- |
Сравнительный |
анализ прямых |
сортиро- |
|||||||||||||||||
ем левой или правой для найденной вер- |
||||||||||||||||||||
тойчивая сортировка (взаимное располо- |
вок показывает, что обменная "сортиров- |
|||||||||||||||||||
шины. |
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
жение одинаковых ключей не меняется). |
ка" |
в классическом виде |
представляет |
|||||||||||
Алгоритм |
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
Эффективность |
сортировки можно |
рас- |
собой нечто среднее между сортировками |
||||||||||||
Для создания дерева необходимо соз- |
||||||||||||||||||||
сматривать с нескольких критериев: |
|
с помощью включений и с помощью выбо- |
||||||||||||||||||
дать в памяти элемент следующего типа: |
|
|||||||||||||||||||
- время, затрачиваемое на сортировку; |
ра. Если же в нее внесены приведенные |
|||||||||||||||||||
Тип на ПАСКАЛе: |
|
|
|
|
||||||||||||||||
|
|
|
|
- объем оперативной |
памяти, |
требуемой |
выше усовершенствования, |
то для доста- |
||||||||||||
typepelem = ^еlem; |
|
|
|
|
||||||||||||||||
|
|
|
|
для сортировки; |
|
|
|
точно упорядоченных массивов пузырько- |
||||||||||||
elem = record |
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
- время, затраченное |
программистом на |
вая сортировка даже имеет преимущест- |
||||||||||||||
left : pointer; |
|
|
|
|
||||||||||||||||
|
|
|
|
написание программы. |
|
|
|
во. |
|
|
|
|
|
|
||||||
right: pointer; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
Выделяем |
первый критерий, |
поскольку |
Эффективность |
этих трех |
методов при- |
|||||||||||
К : integer; |
|
|
|
|
||||||||||||||||
|
|
|
|
будем рассматривать только методы сор- |
мерно одинакова. |
|
|
|
||||||||||||
end; |
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
тировки «на том же месте», то есть, не |
Улучшенные методы: |
|
|
|
||||||||||
К - элемент массива, V - указатель на |
|
|
|
|||||||||||||||||
резервируя для процесса сортировки до- |
1) быстрая сортировка. |
|
|
|
||||||||||||||||
созданный элемент. |
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
полнительную |
память. |
Эквивалентом |
за- |
|
О(nlogn) - самый эффективный метод. |
|||||||||||
В процедуре создания дерева бинарного |
|
|||||||||||||||||||
траченного на сортировку времени можно |
2) сортировка Шелла. |
|
|
|
||||||||||||||||
поиска |
будут использованы |
следующие |
|
|
|
|||||||||||||||
считать количество сравнений при выпол- |
He доказано, какие расстояния дают наи- |
|||||||||||||||||||
указатели: |
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
нении сортировки и количество переме- |
лучший результат, но они не должны быть |
||||||||||||||
tree - указатель на корень дерева;р - |
||||||||||||||||||||
щений. |
|
|
|
|
|
множителями один другого. Д. Кнут пред- |
||||||||||||||
рабочий указатель;q - |
указатель отстаю- |
|
|
|
|
|
||||||||||||||
Порядок числа сравнения при сортировке |
лагает такую последовательность шагов |
|||||||||||||||||||
щий на шаг от р;key - новый элемент мас- |
||||||||||||||||||||
лежит в пределах от О (nlogn) до О (n2); |
(в обратном порядке): 1, 3, 7, 15, 31, ... |
|||||||||||||||||||
сива;Создание дерева бинарного поиска |
О(n) - идеальный и недостижимый случай. |
То есть: h |
= h |
+ 1, t = log |
n - 1. При |
|||||||||||||||
(псевдокод) |
|
|
|
|
||||||||||||||||
|
|
|
|
Различают |
следующие |
методы |
сортиров- |
|
|
m 1 |
m |
|
2 |
|
||||||
writeln(' |
|
|
|
|
|
такой организации алгоритма его эффек- |
||||||||||||||
|
|
|
|
|
ки: |
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
тивность имеет порядок О (n 1.2 ). |
|
|||||||||
Введитеэлементмассива');readln(key); |
|
|
|
|
|
|
||||||||||||||
- строгие (прямые) методы; |
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||
tree:=maketree(key); p:=tree; while not |
|
|
|
|
|
|
|
|
|
|||||||||||
- улучшенные методы. |
|
|
|
|
|
|
|
|
|
|
||||||||||
eof |
do |
begin |
|
readln(key); |
|
|
|
|
|
|
|
|
|
|
||||||
|
Строгие методы: |
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
40. Нерекурсивный алгоритм обхода |
|
|
|
которая хешируется в позицию 397 (с |
|||||||||||
дерева в прямом порядке |
|
|
р = bucket (i) |
|
таким ключом, как 8764397) или в пози- |
||||||||||
Пусть T – указатель на бинарное дерево; |
|
|
|
цию 398 (с таким ключом, как 2194398), |
|||||||||||
А – стек, в который заносятся адреса еще |
while p <>nil do |
|
вставляется в |
следующую |
свободную |
||||||||||
не пройденных вершин; TOP – вершина |
|
|
|
позицию, которая в данном случае равна |
|||||||||||
стека; P – рабочая переменная. |
|
if k(p) = key |
|
400. |
|
|
|
|
|||||||
1.Начальная установка: TOP:=0; P:=T. |
|
|
|
|
|
|
|
|
|||||||
2.Если P=nil, то перейти на 4. {конец |
then search = p |
|
Этот метод еще называется методом ли- |
||||||||||||
ветви} |
|
|
|
|
|
|
|
|
|
нейных проб, он является примером не- |
|||||
3.Вывести P^.info. Вершину заносим в |
return |
|
|
которого |
общего |
метода |
разрешения |
||||||||
стек: TOP:=TOP+1; A[TOP]:=P; шаг по |
|
|
|
коллизий при хешировании, который |
|||||||||||
левой ветви: P:=P^.llink; перейти на 2. |
endif |
|
|
называется повторным хешированием. |
|||||||||||
4.Если TOP=0, то КОНЕЦ. |
|
|
|
|
|
|
|
|
|
|
|||||
5.Достаем вершину из стека: P:=A[TOP]; |
q = p |
|
|
В общем случае функция повторного хе- |
|||||||||||
TOP:=TOP-1; |
|
|
|
|
|
|
|
|
ширования |
rh воспринимает один ин- |
|||||
Шаг по правой связи: P:=P^.rlink; пе- |
p = nxt(p) |
|
декс в массиве и выдает другой индекс. |
||||||||||||
рейти на 2. |
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Реализация |
нерекурсивного |
алгоритма |
endwhile |
|
Если ячейка массива h(key) уже занята |
||||||||||
поиска может выглядеть следующим обра- |
|
|
|
некоторой записью с другим ключом, то |
|||||||||||
зом: |
|
|
|
|
|
|
{ключ не найден, вставляем |
новую за- |
функция rh применяется к значению |
||||||
Function Locate(x: integer; T: Link):Link; |
пись} |
|
|
h(key) для того, чтобы найти другую |
|||||||||||
var found: boolean; begin found:= false; |
|
|
|
ячейку, куда может быть помещена эта |
|||||||||||
while (T <> nil) and not found do if T^.elem |
s = getnode |
|
запись. Если ячейка rh(h(key)) также |
||||||||||||
= |
x |
then |
found |
:= |
true |
|
|
|
занята, то хеширование выполняется еще |
||||||
else if T^.elem> x then T:=T^. left else |
k(s) = key |
|
раз и проверяется ячейка rh(rh(h(key))) |
||||||||||||
T:=T^.right; Locate := T end; |
|
|
|
|
|
и т.д. |
|
|
|
|
|||||
Для упрощения процедуры поиска можно |
nxt(s) = nil |
|
|
|
|
|
|
||||||||
использовать |
дерево с |
узлом-барьером |
|
|
|
Алгоритмы метода открытой адресации |
|||||||||
(последний пустой узел z, в который за- |
if q = nil |
|
|
|
|
|
|
||||||||
сылается элемент для поиска x) |
|
|
|
|
Function h(key) – хешфункция |
||||||||||
function Locate(x: integer; T: Link):Link; |
then bucket (i) = s |
|
|
|
|
|
|
||||||||
begin z^.elem:=x; while T^.elem<> x do if |
|
|
|
h = key mod n |
|
|
|
||||||||
T^.elem> x then T:=T^. left else |
else nxt(q) = s |
|
|
|
|
|
|
||||||||
T:=T^.right; Locate := T end; |
|
|
|
|
|
return |
|
|
|
|
|||||
|
|
|
|
|
|
|
|
endif |
|
|
|
|
|
|
|
44.Разрешение коллизий при хеши- |
|
|
|
Function |
rh(i) |
- |
функцияповторногохе- |
||||||||
ровании методом цепочек. Алгорит- |
search = s |
|
ширования |
|
|
|
|||||||||
мы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Метод представляет собой организацию |
return |
|
|
rh = i+1 mod n |
|
|
|||||||||
связанного списка из всех записей, чьи |
|
|
|
|
|
|
|
|
|||||||
ключи хешируются в одно и то же значе- |
Удаление узла из таблицы, которая по- |
return |
|
|
|
|
|||||||||
ние. |
|
|
|
|
|
|
строена по методу цепочек, заключается |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
просто в исключении узла из связанного |
Procedure insert(key) – процедуравстав- |
||||||
Предположим, что хеш-функция выдает |
списка. Удаленный узел никак не влияет |
киключавхеш-таблицу |
|
||||||||||||
значения в диапазоне от 0 до n-1. Тогда |
на эффективность алгоритма поиска. |
|
|
|
|
|
|||||||||
описывается |
некоторый |
массив |
bucket, |
Алгоритм будет работать так, как если бы |
i = h(key) {хешируемключ} |
|
|||||||||
имеющий размер n и состоящий из узлов |
этот узел никогда не вставлялся в табли- |
|
|
|
|
|
|||||||||
заголовков. Элемент bucket (i) указывает |
цу. Отметим, что эти списки могут быть |
while ((k(i)<>key) and (k(i)<> nullkey )) |
|||||||||||||
на список всех записей, чьи ключи хе- |
динамически переупорядочены для по- |
do |
|
|
|
|
|||||||||
шируются в i. При поиске записи осуще- |
лучения большей эффективности поиска. |
|
|
|
|
|
|||||||||
ствляется доступ к заголовку списка, |
|
|
|
i = rh(i) { повторное хеширование} |
|||||||||||
который занимает позицию i в массиве |
Основным недостатком метода цепочек |
|
|
|
|
|
|||||||||
узлов. Если запись не найдена, то она |
является то, что для узлов указателей |
if k(i) = nullkeythen {вставляем ключ в |
|||||||||||||
вставляется в конец списка. |
|
|
требуется дополнительное пространство. |
пустую |
позицию} |
|
|
||||||||
|
|
|
|
|
|
|
|
Однако в алгоритмах, которые использу- |
|
|
|
|
|
||
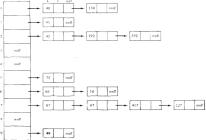
Предположим, что имеется массив из 10 |
ют метод цепочек, первоначальный мас- |
k(i) = key |
|
|
|
||||||||||
элементов и что хеш-функция равна |
сив меньше, чем в алгоритмах, которые |
|
|
|
|
|
|||||||||
keymod 10. Ключи представлены в таком |
используют повторное хеширование. Это |
endwhile |
|
|
|
|
|||||||||
порядке: |
|
|
|
|
|
|
происходит из-за того, что при методе |
|
|
|
|
|
|||
75 |
66 |
42 |
192 |
91 |
40 |
49 |
87 67 |
цепочек не так катастрофично, если весь |
return |
|
|
|
|
||
16 |
417 |
130 372 |
227 |
|
|
|
массив становится заполненным. Всегда |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
имеется возможность выделить дополни- |
|
|
|
|
|
||
Массив узлов заголовков с соответст- |
тельные узлы и добавить их к различным |
|
|
|
|
|
|||||||||
вующими односвязными списками |
|
спискам. Конечно, если эти списки станут |
Subroutine heshtable – функциясоздания- |
||||||||||||
|
|
|
|
|
|
|
|
очень длинными, то теряет смысл вся |
хеш-таблицы |
|
|
|
|||
|
|
|
|
|
|
|
|
идея хеширования - прямая адресация и, |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
как следствие, эффективный поиск. |
while not eof do |
|
|
||||
|
|
|
|
|
|
|
|
43.Функции создания, поиска и по- |
read key |
|
|
|
|||
|
|
|
|
|
|
|
|
иска со вставкой ключа в хеш- |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
таблицу, созданную методом откры- |
insert(key) |
|
|
|
|||
|
|
|
|
|
|
|
|
той адресации. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Разрешение коллизий при хешировании |
endwhile |
|
|
|
|||
|
|
|
|
|
|
|
|
методом открытой адресации |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. |
|
|
|
return |
|
|
|
|
Разрешение коллизий при хешировании |
Самым |
простым методом |
разрешения |
|
|
|
|
|
|||||||
методом цепочек. |
|
|
|
|
коллизий при хешировании является по- |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
мещение данной записи в следующую |
|
|
|
|
|
||
Алгоритм реализации метода цепочек |
свободную позицию в массиве. Напри- |
Subroutine search – функцияпоискавхеш- |
|||||||||||||
|
|
|
|
|
|
|
|
мер, запись с ключом 0596397 помеща- |
таблице |
|
|
|
|
||
i = |
h(key) |
|
|
|
|
|
ется в ячейку 398, которая пока свобод- |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
на, поскольку 397 уже занята. Когда эта |
|
|
|
|
|
||
q = nil |
|
|
|
|
|
|
запись |
будет вставлена, другая запись, |
|
|
|
|
|
||

read key
i = h(key) {хешируемключ}
repeat
if k(i) = key
then {элементнайден}
search = i
return
else if k(i) = nullkey
then {элемента в таблице нет}
search = 0
return
else {конфликт}
i = rh(i) { повторноехеширование}
endif
endif
until (k(i) = key) or (k(i) = nullkey )
return
Поиск и вставка ключа
i = h(key) {хешируем ключ}
while (k(i)<>key) and (k(i)<>nullkey) do
i = rh(i) {повторное хеширование}
endwhile
if k(i)= nullkey
then {вставляем запись в пустую позицию}
k(i)=key
endif
search = i
return
Недостатки метода открытой адресации
Во - первых, он предполагает фиксированный размер таблицы. Если число записей превысит этот размер, то их невозможно вставлять без выделения таблицы большего размера и повторного вычисления значений хеширования для ключей всех записей, находящихся уже в таблице, используя новую хеш-функцию.
Во - вторых, из такой таблицы трудно удалить запись.
41. ПОНЯТИЕ И ВЫБОРА ФУНКЦИИ
ПРЕОБРАЗОВАНИЯ КЛЮ- ЧЕЙ.ХЕШИРОВАНИЕ. ПРИМЕР ХЕШФУНКЦИИ.
Преобразование ключей (расстановка)
Метод расстановок (хеширования) на-
правлен на быстрое решение задачи о |
в некоторый индекс в таблице, называет- |
|||||||
местоположении элемента в структуре |
ся хеш-функцией. |
|
|
|||||
данных. В методе расстановок данные |
В данном случае h(key) = keymod 1000; |
|||||||
организованы как обычный массив. По- |
Хеш-таблица - это обычный массив с не- |
|||||||
этому Н - отображение, преобразующее |
обычной адресацией, задаваемой хеш- |
|||||||
ключи в индексы массива, отсюда и поя- |
функцией. |
|
|
|
|
|
||
вилось название «преобразование клю- |
Рассмотренный метод создания хеш- |
|||||||
чей», обычно даваемое этому методу. |
таблицы имеет один недостаток. |
|||||||
Следует заметить, что нет никакой нуж- |
Предположим, что существуют два ключа |
|||||||
ды обращаться к каким-либо процедурам |
k1 и k2 такие, что h(k1)=h(k2). Когда |
|||||||
динамического размещения, ведь массив |
запись с ключом kl вводится в таблицу, |
|||||||
— это один из основных, статических |
она вставляется в позицию h(k1). Но ко- |
|||||||
объектов. Метод преобразования ключей |
гда хешируется ключ k2, получаемая |
|||||||
часто используется для таких задач, где |
позиция является той же позицией, в |
|||||||
можно с успехом воспользоваться и де- |
которой хранится запись с ключом k1. |
|||||||
ревьями. |
|
Ясно, что две записи не могут занимать |
||||||
|
|
одну и ту же позицию. Такая ситуация |
||||||
Если каждый ключ должен быть извлечен |
называется коллизией при хешировании |
|||||||
за один доступ, то положение записи |
или столкновением. |
|
|
|||||
внутри такой таблицы может зависеть |
В примере с записями о деталях колли- |
|||||||
только от данного ключа. Оно не может |
зия при хешировании произойдет, если в |
|||||||
зависеть от расположения других клю- |
таблицу будет добавлена запись с клю- |
|||||||
чей, как это имеет место в дереве. Наи- |
чом 0596397. |
|
|
|
||||
более эффективным способом организа- |
Следует отметить, что хорошей хеш- |
|||||||
ции подобной таблицы является массив. |
функцией является такая функция, кото- |
|||||||
|
|
рая минимизирует коллизии и распреде- |
||||||
Предположим, что некоторая фирма вы- |
ляет записи равномерно по всей таблице. |
|||||||
пускает детали и кодирует их семизнач- |
Совершенная хеш-функция - эта функ- |
|||||||
ными цифрами. Для применения прямой |
ция, которая не порождает коллизий. |
|||||||
индексации с |
использованием полного |
Разрешить |
|
коллизии при хешировании |
||||
семизначного |
ключа потребовался бы |
можно 2 методами: |
|
|
||||
массив из 10 млн. элементов. Ясно, что |
методом открытой адресации; |
|||||||
это привело бы к потере неприемлемо |
методом цепочек |
|
|
|||||
большого пространства памяти, посколь- |
Основная трудность, связанная с преоб- |
|||||||
ку совершенно невероятно, что какая- |
разованием ключей, заключается в том, |
|||||||
либо фирма может иметь больше чем |
что множество возможных значений зна- |
|||||||
тысячу наименований изделий. Поэтому |
чительно |
шире |
множества |
допустимых |
||||
необходим метод преобразования ключа |
адресов памяти (индексов массива). |
|||||||
в какое-либо целое число внутри ограни- |
Возьмем в качестве примера имена, |
|||||||
ченного диапазона. |
включающие до 16 букв и представляю- |
|||||||
Если в качестве индекса записи об изде- |
щие собой ключи, идентифицирующие |
|||||||
лии в массиве использовать три послед- |
отдельные индивиды из множества в ты- |
|||||||
ние цифры номера изделия, тогда для |
сячу персон. Следовательно, мы имеем |
|||||||
хранения всего файла будет достаточно |
дело с 2616 возможными ключами, кото- |
|||||||
массива из 1000 элементов. Этот массив |
рые нужно отобразить в 103 возможных |
|||||||
индексируется целым числом в диапазо- |
индексов. Поэтому функция Н будет |
|||||||
не от 0 до 999 включительно. |
функцией класса «много значений в одно |
|||||||
Записи о деталях |
значение». Если дан некоторый ключ k, |
|||||||
|
|
то первый шаг операции поиска — вы- |
||||||
|
|
числение связанного с ним индекса h = |
||||||
|
|
H(k), а второй (совершенно необходи- |
||||||
|
|
мый) — проверка, действительно ли h |
||||||
|
|
идентифицирует в массиве (таблице) Т |
||||||
|
|
элемент с ключом k. |
|
|
||||
|
|
\ |
|
|
|
|
|
|
|
|
42. РАЗРЕШЕНИЕ КОЛЛИЗИЙ МЕТО- |
||||||
|
|
ДОМ |
ОТКРЫТОЙ |
АДРЕСАЦИИ ПРИ |
||||
|
|
ХЕШИРОВАНИИ. АЛГОРИТМЫ МЕТО- |
||||||
|
|
ДА ОТКРЫТОЙ АДРЕСАЦИИ. |
||||||
|
|
Разрешение коллизий при хеширо- |
||||||
|
|
вании методом открытой адресации |
||||||
|
|
Самым |
простым |
методом |
разрешения |
|||
|
|
коллизий при хешировании является по- |
||||||
|
|
мещение данной записи в следующую |
||||||
|
|
свободную позицию в массиве. Напри- |
||||||
|
|
мер, запись с ключом 0596397 помеща- |
||||||
Отметим, что два ключа, которые близки |
ется в ячейку 398, которая пока свобод- |
|||||||
друг к другу как числа (такие как |
на, поскольку 397 уже занята. Когда эта |
|||||||
4618396 и 4618996), могут располагаться |
запись будет вставлена, другая запись, |
|||||||
дальше друг от друга в этой таблице, чем |
которая хешируется в позицию 397 (с |
|||||||
два ключа, которые значительно разли- |
таким ключом, как 8764397) или в пози- |
|||||||
чаются как числа (такие как 0000991 и |
цию 398 (с таким ключом, как 2194398), |
|||||||
9846995). Это происходит из-за того, что |
вставляется |
в |
следующую |
свободную |
||||
для определения позиции записи исполь- |
позицию, которая в данном случае равна |
|||||||
зуются только три последние цифры |
400. |
|
|
|
|
|
|
|
ключа. |
|
Этот метод еще называется методом ли- |
||||||
Хеширование - это способ сведения |
нейных проб, он является примером не- |
|||||||
хранения одного большого множества к |
которого |
общего |
метода |
разрешения |
||||
меньшему, или «много значений в одно |
коллизий при хешировании, который |
|||||||
значение» . |
|
называется повторным хешированием. |
||||||
Выбор функции преобразования. |
В общем случае функция повторного хе- |
|||||||
Функция, которая трансформирует ключ |
ширования |
rh |
воспринимает один ин- |
|||||

декс в массиве и выдает другой индекс. |
функцию. |
|
Если ячейка массива h(key) уже занята |
Во - вторых, из такой таблицы трудно |
|
некоторой записью с другим ключом, то |
удалить запись. |
|
функция rh применяется к значению |
|
|
h(key) для того, чтобы найти другую |
|
|
ячейку, куда может быть помещена эта |
|
|
запись. Если ячейка rh(h(key)) также |
|
|
занята, то хеширование выполняется еще |
|
|
раз и проверяется ячейка rh(rh(h(key))) |
|
|
и т.д. |
|
|
Алгоритмы метода открытой адреса- |
|
|
ции |
|
|
Function h(key) – хешфункция |
|
|
h = key mod n |
|
|
return |
|
|
Function |
rh(i) - функцияповторногохе- |
|
ширования |
|
|
rh = i+1 mod n |
|
|
return |
|
|
Procedure insert(key) – процедуравстав- |
|
|
киключавхеш-таблицу |
|
|
i = h(key) {хешируемключ} |
|
|
while ((k(i)<>key) and (k(i)<>nullkey )) |
|
|
do |
|
|
i = rh(i) { повторное хеширование} |
|
|
if k(i) = nullkeythen {вставляем ключ в |
|
|
пустую |
позицию} |
|
k(i) = key endwhile return
Subroutine heshtable –
функциясозданияхеш-таблицы while not eof do
read key insert(key) endwhile return
Subroutine search –
функцияпоискавхеш-таблице
read key
i = h(key) {хешируемключ} repeat
if k(i) = key
then {элементнайден} search = i
return
else if k(i) = nullkey
then {элемента в таблице нет} search = 0
return
else {конфликт}
i = rh(i) { повторноехеширование} endif
endif
until (k(i) = key) or (k(i) = nullkey ) return
Поиск и вставка ключа
i = h(key) {хешируем ключ}
while (k(i)<>key) and (k(i)<>nullkey) do i = rh(i) {повторное хеширование}
endwhile
if k(i)= nullkey
then {вставляем запись в пустую позицию}
k(i)=key endif
search = i return
Недостатки метода открытой адресации
Во - первых, он предполагает фиксированный размер таблицы. Если число записей превысит этот размер, то их невозможно вставлять без выделения таблицы большего размера и повторного вычисления значений хеширования для ключей всех записей, находящихся уже в таблице, используя новую хеш-