

AISD
.pdf1. ТИПЫ ДАННЫХ
Вматематике принято классифицировать переменные в соответствие с некоторыми важными характеристиками. Мы различаем вещественные, комплексные и логические переменные, переменные, представляющие собой отдельные значения, множества значений или множества множеств. В обработке данных понятие классификации играет такую же, если не большую роль. Мы будем придерживаться того принципа, что любая константа, переменная, выражение или функция относятся к некоторому типу.
Фактически тип характеризует множество значений, которые может принимать некоторая переменная или выражение и которые может формировать функция.
Вбольшинстве языков программирования различают стандартные типы данных и типы, заданные пользователем. К стандартным относят 5 типов:
a) целый (INTEGER);
b) вещественный (REAL) ; c) логический (BOOLEAN); d) символьный (CHAR);
e) указательный (POINTER).
К пользовательским относят 2 типа: a) перечисляемый;
b) диапазонный.
Любой тип данных должен быть охарактеризован областью значений и допустимыми операциями над этим типом Данных.
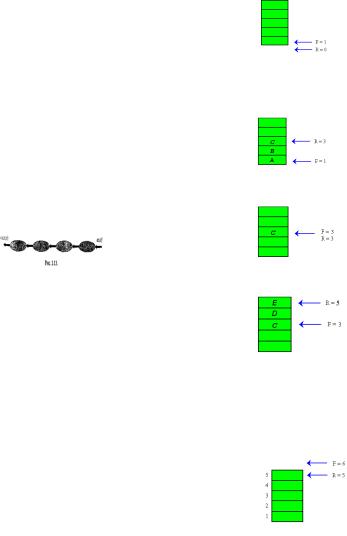
Целый тип - INTEGER
Этот тип включает некоторое подмножество целых, размер которого варьируется от машины к машине. Если для представления целых чисел в машине используется n разрядов, причем используется дополнительный код, то допустимые числа должны удовлетворять условию -2
'<= х< 2 .
Считается, что все операции над данными этого типа выполняются точно и соответствуют обычным правилам арифметики. Если результат выходит за пределы представимого множества, то вычисления будут прерваны. Такое событие называется переполнением.
Числа делятся на знаковые и беззнаковые. Для каждого из них имеется свой диапазон значений:
а)(0..2n-1) для без знаковых чисел
Рис. 1.1
При обработке машиной чисел, используется формат со знаком. Если же машинное слово используется для записи и обработки команд и указателей, то в этом случае используется формат без знака.
Операции над целым типом:
a)Сложение.
b)Вычитание.
c)Умножение.
d)Целочисленное деление.
e)Нахождение остатка по модулю.
f) Нахождение экстремума числа (минимума и максимума)
g) Реляционные операции (операции сравнения) (<,>,<=,>=, =,<>)
Примеры: Adiv В = С
Amod В = D С* B + D = A 7 div 3 = 2
7 mod 3 = 1
Во всех операциях, кроме реляционных, в результате получается целое число.
Вещественный тип - REAL
Вещественные типы образуют ряд подмножеств вещественных чисел, которые представлены в машинных форматах с плавающей точкой. Числа
в формате с плавающей точкой характеризуются целочисленными значениями мантиссы и порядка, которые определяют диапазон изменения и количество верных знаков в представ-
лении чисел вещественного типа.
X = +/- М * q(+/-P) - полулогарифмическая форма представления числа, показана на рисунке 2.
937,56 = 93756 * 10-2 = 0,93756 * 103
Рис. 1.2
Удвоенная точность необходима для того, чтобы увеличить точность мантиссы.
Логический тип - BOOLEAN
Стандартный логический тип Boolean (размер-1 байт) представляет собой тип данных, любой элемент которого может принимать лишь 2 значения: True и False.
Над логическими элементами данных выполняются логические операции. Основные из них:
a) Отрицание (NOT) b) Конъюнкция (AND) c) Дизъюнкция (OR)
Логические значения получаются также при реляционных операциях с целыми числами.
Символьный тип – CHAR
Тип CHAR содержит 26 прописных латинских букв и 26 строчных, 10 арабских цифр и некоторое число других графических символов, например, знаки пунктуации.
Подмножества, букв и цифр упорядочены и "соприкасаются", т.е.
("А"<= х)&(х <= "Z") - х представляет собой прописную букву
("0"<= х)&(х <= "9") - х представляет собой цифру Тип CHAR содержит некоторый непечатаемый символ, пробел, его можно использовать как разделитель. Операции:
a)Присваивания
b)Сравнения
c)Определения номера данной литеры в системе кодирования. ORD(Wi)
d)Нахождение литеры по номеру. CHR(i)
e)Вызов следующей литеры. SUCC(Wi)
f)Вызов предыдущей литеры. PRED(Wi)
Указательный тип -POINTER
Переменная типа указатель является физическим носителем адреса величины базового типа. Стандартный типуказатель Pointer дает указатель, не связанный ни с каким конкретным базовым типом. Этот тип совместим с любым другим типом-указателем. Операции:
a)Присваивания
b)Операции с беззнаковыми целыми числами.
При помощи этих операций можно вычислить адрес данных. В машинном виде эти типы занимают максимально возможную длину.
Например:
ABCD:1234 - значение указателя в шестнадцатеричной системе счисления - относительный адрес. Первое число (ABCD) - адрес сегмента Второе число
.(1234) - адрес внутри сегмента.
Получение абсолютного адреса из относительного:
Для получения абсолютного адреса необходимо произвести сдвиг адреса сегмента влево, и к полученному числу прибавить адрес внутреннего сегмента.
Например:
1) Сдвигаем ABCD на один разряд влево. Получаем ABCD0.
2) Прибавляем 1234. Полученный результат и является абсолютным адресом.
ABCD0 1234
---------
ACF04 – абсолютный адрес данного числа.
Наиболее важной характеристикой является изменчивость структуры во времени.
По признаку физического размещения структуры данных различают оперативные и файловые структуры. Структуры данных, размещаемые в оперативной памяти, называют оперативными структурами. Файловые структуры соответствуют структурам данных внешней памяти. Оперативная память является быстрой, а внешняя — медленной.
2. СТАНДАРТНЫЕ и пользовательские типы Все типы данных можно разделить на две
группы: скалярные и структурированные (составные). Скалярные типы, в свою очередь, делятся на стандартные и пользовательские.
Стандартные типы данных предлагаются пользователям разработчиками системы. К ним относятся целочисленные, вещественные, литерные, булевские типы данных и указатели.
Пользовательские типы данных разрабатываются пользователями системы программирования.
3. СТРУКТУРЫ ДАННЫХ
Структуры данных - это совокупность элементов данных и отношений между ними. При этом под элементами данных может подразумеваться как простое данное так и структура данных. Под отношениями между данными понимают функциональные связи между ними и указатели на то, где находятся эти данные.
Графическое представление элемента структуры данных.
Элемент отношений - это совокупность всех связей элемента с другими элементами данных, рассматриваемой структуры.
S:=(D,R)
Где S - структура данных, D - данные и R - отношения.
Как бы сложна ни была структура данных, в конечном итоге она состоит из простых данных.
Внутренний мир ЭВМ далеко не так прост, как мы думаем. Память машины состоит из миллионов триггеров, которые обрабатывают поступающую информацию.
Мы, занося инф-цию в компьютер, представляем еѐ в каком-то виде, который на наш взгляд упорядочивает данные и придаѐт им смысл. Машина отводит поле для поступающей инф-ции и задаѐт ей какой-то адрес. Т.о. получается, что мы обрабатываем данные на логическом уровне, как бы абстрактно, а машина делает это на физическом уровне.
4. КЛАССИФИКАЦИЯ СТРУКТУР ДАННЫХ
Структуры данных классифицируются: 1. По связанности данных в структуре:
- если данные в структуре связаны очень слабо, то такие структуры называются

несвязанными (вектор, массив, строки, |
В графическом виде, так и в табличном. |
||||||||||||||||
стеки) |
|
|
|
|
|
|
|
|
|
|
Операции над записями: |
|
|||||
- если данные в структуре связаны, то |
1.Прочтение содержимого поля записи. |
||||||||||||||||
такие структуры называются связанными |
2. Занесение информации в поле записи. |
||||||||||||||||
(связанные списки) |
|
|
|
|
|
|
|
|
3. Все операции, которые разрешаются |
||||||||
2. По изменчивости структуры во време- |
над полем записи, соответствующего |
||||||||||||||||
ни или в процессе выполнения програм- |
типа. |
|
|
|
|
|
|||||||||||
мы: |
|
|
|
|
|
|
|
|
|
|
При задании таблицы указывается коли- |
||||||
- статические структуры - структуры, |
чество содержащихся в ней записей. |
||||||||||||||||
неменяющиеся |
до |
|
конца |
выполнения |
Пример: |
|
|
|
|
|
|||||||
программы (записи, массивы, строки, |
Type ST = Record |
|
|
|
|
||||||||||||
вектора) |
|
|
|
|
|
|
|
|
|
|
Num: Integer; Name: String[15]; |
|
|||||
- полустатические структуры (стеки, де- |
Fak: String[5]; Group: String[10]; |
||||||||||||||||
ки, очереди) |
|
|
|
|
|
|
|
|
|
Angl: Integer; Physic: Integer; |
|
||||||
- динамические структуры - происходит |
var Table: Array [1...19] of St; |
|
|||||||||||||||
полное изменение при выполнении про- |
Элементом |
данных |
таблицы |
является |
|||||||||||||
граммы |
|
|
|
|
|
|
|
|
|
|
запись. Поэтому операции, которые про- |
||||||
3. По упорядоченности структуры: |
|
|
изводятся с таблицей - это операции, |
||||||||||||||
- линейные (вектора, массивы, стеки, |
производимые с записью. |
|
|
||||||||||||||
деки, записи) |
|
|
|
|
|
|
|
|
|
Операции с таблицами: |
|
|
|||||
- нелинейные (многосвязные списки, |
1. Поиск записи по заданному ключу. |
||||||||||||||||
древовидные структуры, графы) |
|
|
|
2. Занесение новой записи в таблицу. |
|||||||||||||
Наиболее важной характеристикой явля- |
Ключ - это идентификатор записи. Для |
||||||||||||||||
ется изменчивость структуры во времени. |
хранения этого идентификатора отводит- |
||||||||||||||||
Векторы |
|
|
|
|
|
|
|
|
|
|
ся специальное поле. |
|
|
||||
Самая простая статическая структура - |
Составной ключ - ключ, содержащий бо- |
||||||||||||||||
это вектор. Вектор - это чисто линейная |
лее двух полей. |
|
|
|
|
||||||||||||
упорядоченная структура, где отношение |
|
|
|
|
|
|
|||||||||||
между ее элементами есть строго выра- |
34. Сортировка методом прямого |
||||||||||||||||
женная |
последовательность |
элементов |
включения |
|
|
|
|
||||||||||
структуры (рис. 2.5). |
|
|
|
|
|
|
|
Элементы мысленно делятся на уже гото- |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
вую последовательность |
a1,...,ai-1 и ис- |
|||||
Каждый элемент вектора имеет свой ин- |
ходную последовательность. При каждом |
||||||||||||||||
шаге, начиная с |
i |
= 2 |
и увеличивая i |
||||||||||||||
декс, определяющий положение данного |
|||||||||||||||||
каждый раз на единицу, из исходной по- |
|||||||||||||||||
элемента в векторе. |
Поскольку индексы |
||||||||||||||||
следовательности извлекается i-й элемент |
|||||||||||||||||
являются |
целыми |
числами, |
над |
ними |
|||||||||||||
и перекладывается |
в готовую последова- |
||||||||||||||||
можно производить |
операции и, |
таким |
|||||||||||||||
тельность, |
при этом он |
вставляется на |
|||||||||||||||
образом, вычислять положение элемента |
|||||||||||||||||
нужное место. |
|
|
|
|
|||||||||||||
в структуре на логическом уровне досту- |
|
|
|
|
|||||||||||||
Алгоритм этой сортировки таков: |
|
||||||||||||||||
па. Для доступа к элементу вектора, дос- |
|
||||||||||||||||
|
|
|
|
|
|
||||||||||||
таточно |
просто указать |
имя |
вектора |
fori = 2 to n |
|
|
|
|
|||||||||
(элемента) и его индекс . |
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
x = a(i) |
|
|
|
|
||||||||
Для доступа к этому элементу использу- |
|
|
|
|
|||||||||||||
находим |
место |
среди |
а(1)…а(i) |
||||||||||||||
ется функция |
адресации, |
которая |
фор- |
||||||||||||||
для включения х |
|
|
|
|
|||||||||||||
мирует из значения индекса адрес слота, |
|
|
|
|
|||||||||||||
nexti |
|
|
|
|
|
||||||||||||
где находится значение исходного эле- |
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
||||||||||||
мента. Для объявления в программе век- |
Алгоритм сортировки методом прямо- |
||||||||||||||||
тора необходимо указать его имя, коли- |
|||||||||||||||||
го включения без барьера |
|
||||||||||||||||
чество элементов и их тип (тип данных) |
|
||||||||||||||||
for i = 2 to n |
|
|
|
|
|||||||||||||
Пример: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
x = a(i) |
|
|
|
|
|
||
var |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
for j = i - 1downto1 |
|
|
|||||
Ml: Array |
[1..100] |
of |
integer; |
M2: Array |
|
|
|||||||||||
if x < a(j) |
|
|
|
|
|||||||||||||
[1...10] of real; |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
then |
a( j + 1) = a(j) |
|
|||||||
Вектор состоит из совершенно однотип- |
|
||||||||||||||||
else |
go to |
L |
|
|
|
||||||||||||
ных данных и количество их строго оп- |
|
|
|
||||||||||||||
endif |
|
|
|
|
|
||||||||||||
ределено. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
next j |
|
|
|
|
|
|||
2.3.2 Массивы |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
L: a( j + 1) = x |
|
|
|
|
|||||
В общем случае элемент массива - |
это |
|
|
|
|
||||||||||||
next i |
|
|
|
|
|
||||||||||||
есть элемент |
вектора, который |
сам |
по |
|
|
|
|
|
|||||||||
return |
|
|
|
|
|
||||||||||||
себе тоже является элементом структуры |
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
||||||||||||
(рис. 2.6). |
|
|
|
|
|
|
|
|
|
Недостатком приведенного алгоритма яв- |
|||||||
Для доступа к элементу двумерного мас- |
|||||||||||||||||
ляется нарушение технологии структурно- |
|||||||||||||||||
сива необходимы значения пары индек- |
|||||||||||||||||
го программирования, при которой неже- |
|||||||||||||||||
сов (номер строки |
и номер |
столбца, а |
|||||||||||||||
лательно применять безусловные перехо- |
|||||||||||||||||
пересечении |
которых |
находится |
эле- |
||||||||||||||
ды. Если же внутренний цикл организо- |
|||||||||||||||||
мент). На физическом ровне двумерный |
|||||||||||||||||
вать как цикл while , то необходима по- |
|||||||||||||||||
массив выглядит также, |
как и одномер- |
||||||||||||||||
становка «барьера», без которого при |
|||||||||||||||||
ный вектор), причем трансляторы пред- |
|||||||||||||||||
отрицательных значениях ключей проис- |
|||||||||||||||||
ставляют |
массивы |
либо |
в виде |
строк, |
|||||||||||||
ходит потеря значимости и «зависание» |
|||||||||||||||||
либо в виде столбцов. |
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
компьютера. |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
Алгоритм сортировки методом прямо- |
||||||
5. ЗАПИСИ И ТАБЛИЦЫ. |
|
|
|
|
|
го включения с барьером |
|
||||||||||
|
|
|
|
|
for i = 2 to n |
|
|
|
|
||||||||
Запись представляет |
из |
себя |
структуру |
|
|
|
|
||||||||||
x = a(i) |
|
|
|
|
|
||||||||||||
данных |
последовательного |
типа, |
где |
|
|
|
|
|
|||||||||
a(0) = x |
{a(0) - барьер} |
|
|||||||||||||||
элементы |
структуры |
расположены |
один |
|
|||||||||||||
j = i - 1 |
|
|
|
|
|
||||||||||||
за другим как в логическом, так и в фи- |
|
|
|
|
|
||||||||||||
while x < a(j ) |
do |
|
|
|
|||||||||||||
зическом представлении. Запись предпо- |
|
|
|
||||||||||||||
a( j +1) = a(j ) |
|
|
|||||||||||||||
лагает множество элементов разного ти- |
j = j - 1 |
|
па. Элементы данных в записи часто на- |
||
endwhile |
||
зывают полями записи. |
||
a( j +1) = x |
||
Логическая структура записи может быть |
||
nexti |
||
представлена как |
||
|
return
Эффективность
Минимальные оценки числа сравнений Cminи перемещений Mmin встречаются в случае уже упорядоченной исходной последовательности элементов, наихудшие же оценки Сmax и Mmax- когда они первоначально расположены в обратном порядке.
Количество сравнений в худшем случае, когда массив отсортирован противоположным образом,
Сmax = n(n - 1)/2, то есть порядок
О(n2). Количество перестановок Mmax = Cmax + 3(n-1), то есть порядок
О(n2). Если же массив уже отсортирован, то число сравнений и перестановок минимально: Cmin = n-1; Mmin = 3(n-
1).
6. ПОНЯТИЕ СПИСКОВОЙ СТРУКТУРЫ. СТЕК.
К полустатическим структурам данных относят стеки, деки и очереди.
Списки
Это набор связанных элементов данных, которые в общем случае могут быть разного типа.
Пример списка:
Е1, Е2,......... Еn,... n> 1 и не зафиксировано.
Количество элементов списка может меняться в процессе выполнения программы. Различают 2 вида списков:
1)Несвязные
2)Связные
Внесвязных списках связь между элементами данных выражена неявно. В связных списках в элемент данных заносится указатель связи с последующим или предыдущим элементом списка.
Стеки, деки и очереди - это несвязные списки. Кроме того, они относятся к последовательным спискам, в которых неявная связь отображается их последовательностью.
Стеки
Очередь вида LIFO (LastInFirstOut - По-
следним пришел, первым ушел), при которой на обслуживание первым выбирается тот элемент очереди, который поступил в нее последним, называется стеком. Это одна из наиболее употребляемых структур данных, которая оказывается весьма удобной при решении различных задач.
Всилу указанной дисциплины обслуживания, в стеке доступна единственная его позиция, которая называется вершиной стека - это позиция, в которой находится последний по времени поступления в стек элемент. Когда мы заносим новый элемент в стек, то он помещается поверх прежней вершины и теперь уже сам находится в вершине стека. Выбрать элемент можно только из вершины стека; при этом выбранный элемент исключается из стека, а в его вершине оказывается элемент, который был занесен в стек перед выбранный из него элементом (структура с ограниченным доступом данным).
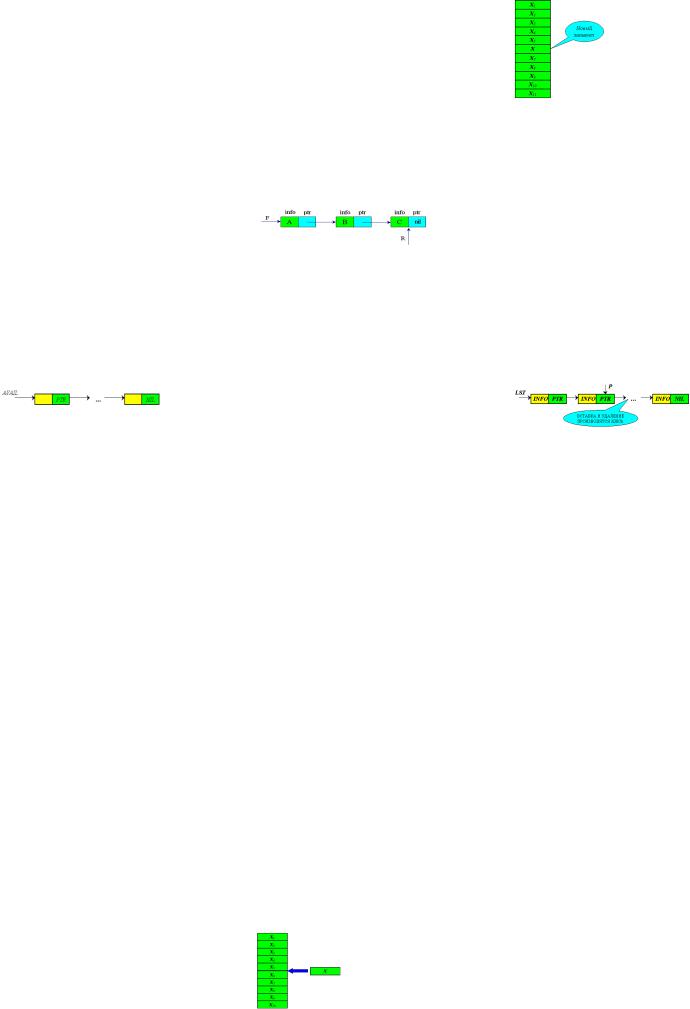
Графически стек можно представить следующим образом:
Рис. 2.12
Первый элемент заносится вниз стека . Выборка из стека осуществляется с вер-
шины, поэтому стек является структурой с ограниченным доступом
Операции, производимые над стеками:
1. Занесение элемента в стек.
Push(S,x),
где S - идентификатор стека, x - заносимый элемент.
2.Выборка элемента из стека.
Pop(S)
3.Определение пустоты стека.
Empty(S)
4.Прочтение элемента без его выборки из стека.
StackTop(S)
5.Определение переполнения стека (для полустатических структур)
Full(S)
i = указательвершины
Push(S,x) i = i+1 S(i) = x return
Pop(S) x = S(i) i = i -1 return
Empty(S) if i = 0
then ―пусто‖
Stop return
endif
Full(S)
if i = maxS
then ―переполнение‖
Stop return
endif
StackTop(S) x = S(i) return
Pop(S)
if i = 0 then ―пусто‖
Stop return
endif
X = S(i) i = i -1 return
Empty(S)
if i = 0 then empty = true
else empty = false
endif return
Pop(S)
Empty(S)
if empty = true
then ―пусто‖
Stop return
endif
x = S(i) i = i -1 return
Push(S,i)
if i = maxS
then ―переполнение‖
Stop return
endif
i = i+1 S(i) = x return
7. ОЧЕРЕДЬ.
Понятие очереди всем хорошо известно из повседневной жизни. Элементами очереди в общем случае являются заказы на то или иное обслуживание. В программировании имеется структура данных, которая называется очередью. Эта структура данных используется например, для моделирования реальных очередей с целью определения их характеристик при данном законе поступления заказов и дисциплине их обслуживания. По своему существу очередь является полустатической структурой - с течением времени и длина очереди, и состав могут изменяться.
На рис. 2. 13 приведена очередь, содержащая четыре элемента — А, В, С и D. Элемент А расположен в начале очереди, а элемент D — в ее конце. Элементы могут удаляться только из начала очереди, то есть первый помещаемый в очередь элемент удаляется первым. По этой причине очередь часто называют списком, организованным по принципу «первый размещенный первым удаляется» в противоположность принципу стековой организации — «последний размещенный первым удаляется».
Дисциплину обслуживания, в которой заказ, поступивший в очередь первым, выбирается первым для обслуживания (и удаляется из очереди), называется FIFO (FirstInFirstOut - Первым пришел, первым ушел). Очередь открыта с обеих сторон.
Таким образом, изъятие компонент происходит из начала очереди, а запись - в конец. В этом случае вводят два указателя: один - на начало очереди, второй - на ее конец.
Реальная очередь создается в памяти ЭВМ в виде одномерного массива с конечным числом элементов, при этом необходимо указать тип элементов очереди, а также необходима переменная в работе с очередью.
return
Empty (q)
if R < F then empty = true else empty = false
endif return
Insert (q, x)
Full (q)
if full = true then ‗переполнение‘ stop
return
endif
R = R + 1 q(R) = x return
Remove (q)
Empty (q)
if empty = true then ‗пусто‘ stop return
endif
x = q(F) F = F + 1 return
Пример работы с очередью с использованием стандартных процедур. maxQ = 5
R= 0, F = 1
Условие пустоты очереди R<F (0 < 1)
Произведем вставку элементов A, B и C в очередь:
Insert (q, A);
Insert (q, B);
Insert (q, C);
Убираем элементы A и B из очереди:
Remove (q);
Remove (q);
Физически очередь занимает сплошную область памяти и элементы следуют друг за другом, как в последовательном списке.
Операции, производимые над очередью:
Операция insert (q,x) - помещает элемент х в конец очереди q.
Операция remove (q) удаляет элемент из начала очереди q и присваивает его значение переменной х.
Операция, empty (q) - вводитсясцельюпредотвращения возможности выборки из пустой очереди.
Операция full (q) - вводитсясцельюпредотвращения возможности переполненияодномерного массива, на которомреализуется полустатическая очередь.
Алгоритмы основных операций с очередью
Full (q)
if R = maxQ then full = true else full = false
endif
Добавляем элементы D и E:
Insert (q, D);
Insert (q, E);
Убираем элементы С,D и E из очереди:
Remove (q);
Remove (q);
Remove (q).
Возникла абсурдная ситуация, при которой очередь является пустой (R < F), однако новый элемент разместить в ней нельзя, так как R = maxQ.
Одним из решений возникшей проблемы может быть модификация операции Remove (q) таким образом, что при удалении очередного элемента вся очередь смещается к началу массива.
Переменная F больше не требуется, поскольку первый элемент массива всегда является началом очереди.
Пустая очередь представлена

очередью, для которой значение R равно нулю.
Произведем вставку элементов A, B и C в очередь:
Insert (q, A);
Insert (q, B);
Insert (q, C);
Убираем элемент A из очереди:
Remove (q)
Операция remove (q) может быть в этом случае реализована следующим образом:
Remove (q) x = q(1)
for i =1 to R-1
q(i) = q(i+1)
next i R =R-1 return
1.8. Недостатки полустатической очереди, методы их исправления. Очередь со сдвигом.
Однако этот метод весьма непроизводителен. Каждое удаление требует перемещения всех оставшихся в очереди элементов. Кроме того, операция удаления элемента из очереди логически предполагает манипулирование только с одним элементом, т. е. с тем, который расположен в начале очереди.
Другой способ предполагает рассматривать массив, который содержит очередь в виде замкнутого кольца. Это означает, что даже в том случае, если последний элемент занят, новое значение может быть размещено сразу же за ним на месте первого элемента, если этот первый элемент пуст.
Предположим, что очередь содержит три элемента - в позициях 3, 4 и 5 пятиэлементного массива. Хотя массив и не заполнен, последний элемент очереди занят.
Если теперь делается попытка поместить
вочередь элемент G, то он будет записан
впервую позицию массива. Первый элемент очереди есть q(3), за которым следуют элементы q (4), q(5) и q(1).
К сожалению, условие R<F больше не годится для проверки очереди на пустоту Одним из способов решения этой проблемы является введение соглашения, при котором значение F есть индекс эле-
мента массива, немедленно предшествующего (по кольцу) первому элементу очереди, а не индекс самого первого элемента.
Вэтом случае, поскольку R содержит индекс последнего элемента очереди, условие F = R подразумевает, что очередь пуста.
9.КОЛЬЦЕВЫЕ ПОЛУСТАТИЧЕСКИЕ ОЧЕРЕДИ. ОПЕРАЦИИ НАД КОЛЬЦЕВОЙ ОЧЕРЕДЬЮ
Рис. 2.17
Рассмотрим пример. Предположим, что очередь содержит три элемента - в позициях 3, 4 и 5 пятиэлементного массива. Этот случай, показанный на рис. 2.17. Хотя массив и не заполнен, последний элемент очереди занят.
Если теперь делается попытка поместить
вочередь элемент G, то он будет записан
впервую позицию массива, как это показано на рис. 2.17. Первый элемент очереди есть Q(3), за которым следуют элементы Q (4), Q(5) и Q(l).
К сожалению, при таком представлении довольно трудно определить, когда очередь пуста. Условие R<F больше не годится для такой проверки, поскольку на рис. 2. 17 показан случай, при котором данное условие выполняется, но очередь при этом не является пустой.
Одним из способов решения этой проблемы является введение соглашения, при котором значение F есть индекс элемента массива, немедленно предшествующего первому элементу очереди, а не индексу самого первого элемента. В этом случае, поскольку R содержит индекс последнего элемента очереди, условие F = R подразумевает, что очередь пуста.
Отметим, что перед началом работы с очередью, в F и R устанавливается значение последнего индекса массива, а не О и 1, поскольку при таком представлении очереди последний элемент массива немедленно предшест-
вует первому элементу. Поскольку R = F, то очередь изначально пуста.
Основные операции с кольцевой очередью:
1.Вставка элемента q в очередь x
Insert(q,x);
2.Извлечение элемента из очереди x
Remove(q);
3.Проверка очереди на пустоту
Empty(q);
4.Проверка очереди на переполнение
Full(q).
Операция Empty(q) if F = R
then empty = true else empty = false
endif return
ОперацияRemove(q) empty (q)
if empty = true
then ―пусто‖ stop
endif
if F =maxQ
then F =1 else F = F+1
endif
x = q(F) return
Отметим, что значение F должно быть модифицировано до момента извлечения элемента.
Переполнение очереди происходит в том случае, если весь массив уже занят элементами очереди, и при этом делается попытка разместить в ней еще один элемент.
Исходное состояние очереди Поместим в очередь элемент G.
Если произвести следующую вставку, то массив становится целиком заполненным, и попытка произвести еще одну вставку приводит к переполнению. Это регистрируется тем фактом, что F = R, то есть это соотношение как раз и указывает на переполнение. Очевидно, что при такой реализации нет возможности сделать различие между пустой и заполненной очередью.
Одно из решений состоит в том, чтобы пожертвовать одним элементом массива и позволить очереди расти до объема, на единицу меньшего максимального. Предыдущий рисунок иллюстрирует именно это соглашение. Попытка разместить в очереди еще один элемент приведет к переполнению.
Проверка на переполнение в подпрограмме insert производится после установления нового значения для R, в то время как проверка на потерю значимости в подпрограмме remove производится сразу же после входа в подпрограмму до момента обновления значения
F.
Подпрограмма Insert(q,x) может быть записана следующим образом:
if R = maxQ
then R = 1 else R = R+1
endif
‗проверка на переполнение‘ if R = F
thenprint «переполнение
очереди»
stop
endif
q (R) =x return
Дек
От английского DEQ - DoubleEndedQueue
(Очередь с двумя концами)
Особенностью деков является то, что запись и считывание элементов может производиться с двух концов (рис. 2.18).
Рис. 2.18.
Дек можно рассматривать и в виде двух стеков, соединенных нижними границами. Возьмем пример, иллюстрирующий принцип построения дека. Рассмотрим состав на железнодорожной станции. Новые вагоны к составу можно добавлять либо к его концу, либо к началу. Аналогично, чтобы отсоединить от состава вагон, находящийся в середине, нужно
сначала отсоединить все вагоны или |
мента списка. Поле указателя по послед- |
сти какую-либо обработку элементов, |
|||||||||||||||||||||||||
вначале, или в конце состава, отсоеди- |
него элемента в списке является пустым |
предшествующих элементу с заданным |
|||||||||||||||||||||||||
нить нужный вагон, а затем присоеди- |
(NIL). LST указатель на начало списка. |
свойством. Однако после нахождения |
|||||||||||||||||||||||||
нить из снова. |
|
|
|
|
|
|
Список может быть пустым, то тогда LST |
элемента с этим свойством в односвязном |
|||||||||||||||||||
Операции над деками: |
|
|
|
|
будет равен NIL. |
|
|
|
|
|
|
|
списке у нас нет возможности получить |
||||||||||||||
|
|
Insert(d, x) - вставка элемента. |
Доступ к элементу списка осуществляет- |
достаточно удобный и быстрый доступ к |
|||||||||||||||||||||||
|
|
Remove(d) - извлечение эле- |
ся только от его начала, то есть обратной |
предыдущим элементам - для достижения |
|||||||||||||||||||||||
|
|
мента из дека. |
|
|
|
|
связи в этом списке нет. |
|
|
|
|
|
этой цели придется усложнить алгоритм, |
||||||||||||||
|
|
Empty(d) - проверка на пустоту. |
Терминология: |
|
|
|
|
|
|
|
|
что неудобно и нерационально. |
|||||||||||||||
|
Full(d) - |
проверка на перепол- |
|
p - указатель |
|
|
|
|
|
|
Для устранения этого неудобства доба- |
||||||||||||||||
|
|
нение. |
|
|
|
|
|
|
|
node(p) – узел, на который |
вим в каждое звено списка еще одно по- |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
ссылается указатель p(при этом |
ле, значением которого будет ссылка на |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
неважно в какое место изобра- |
предыдущее звено списка. Динамическая |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
жения элемента (узла) списка он |
структура, состоящая из элементов тако- |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
направлен на рисунке) |
|
|
|
|
го типа, называется двунаправленным |
||||||||||
|
|
|
|
|
|
|
|
|
|
ptr(p) – ссылка на последующий |
или двусвязным списком. |
|
|||||||||||||||
10.ПОНЯТИЕ Динамических структур |
|
|
элемент узла node(p) |
|
|
|
|
Двусвязный список характеризуется тем, |
|||||||||||||||||||
данных. Организация односвяз. и |
|
ptr(ptr(p)) – ссылка последую- |
что у любого элемента есть два указате- |
||||||||||||||||||||||||
двусвяз. списков. Простейшие опе- |
|
|
щего для node(p) узла на после- |
ля. Один указывает на предыдущий эле- |
|||||||||||||||||||||||
рации над односвяз списками |
|
|
|
дующий для него элемент |
|
|
мент (обратный), другой указывает на |
||||||||||||||||||||
До сих пор мы рассматривали только ста- |
|
|
|
|
|
|
|
|
|
|
|
|
|
следующий элемент (прямой) (рис. 3.4). |
|||||||||||||
тические программные объекты. Однако |
Кольцевой односвязный список |
|
|
|
|
|
|||||||||||||||||||||
использование |
при |
программировании |
Кольцевой односвязный список |
получа- |
Фактически двусвязный |
список это два |
|||||||||||||||||||||
только статических объектов может вы- |
ется |
из |
обычного |
односвязного |
|
списка |
|||||||||||||||||||||
|
односвязных списка с одинаковыми эле- |
||||||||||||||||||||||||||
звать определенные трудности, особенно |
путем |
присваивания указателю |
послед- |
||||||||||||||||||||||||
ментами, записанных в противоположной |
|||||||||||||||||||||||||||
с точки зрения получения эффективной |
него элемента списка значение указате- |
||||||||||||||||||||||||||
последовательности. |
|
||||||||||||||||||||||||||
машинной программы. |
Дело в том, что |
ля начала списка (рис |
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
Кольцевой двусвязный список |
|||||||||||||||||||||
иногда мы заранее не знаем не только |
13). |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
В программировании двусвязные списки |
|||||||||||||||
размера |
значения |
того |
или иного про- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
часто обобщают следующим образом: в |
||||||||||||||
граммного объекта, но также и того, бу- |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
качестве значения поля Rptr последнего |
||||||||||||||
дет ли существовать этот объект или нет. |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
звена |
принимают ссылку на заглавное |
|||||||||||||
Такого рода программные объекты, кото- |
Рнс. 3.3 |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
звено, |
а в качестве значения поля Lptr |
||||||||||||||||
рые возникают уже в процессе выполне- |
Простейшие |
операции, |
производи- |
||||||||||||||||||||||||
заглавного звена - ссылку на полнее |
|||||||||||||||||||||||||||
ния программы или размер значений ко- |
мые над односвязными списками |
|
|||||||||||||||||||||||||
|
звено. |
Список замыкается в своеобраз- |
|||||||||||||||||||||||||
торых |
определяется |
при |
выполнении |
1) Вставка в |
начало односвязного |
спи- |
|||||||||||||||||||||
ное кольцо: двигаясь по ссылкам, можно |
|||||||||||||||||||||||||||
программы, |
называются динамическими |
ска. Надо вставить в начало односвязно- |
|||||||||||||||||||||||||
от |
последнего звена переходить к за- |
||||||||||||||||||||||||||
объектами. |
|
|
|
|
|
|
|
го списка элемент с |
информационным |
||||||||||||||||||
|
|
|
|
|
|
|
главному и наоборот. |
|
|||||||||||||||||||
Динамические структуры данных имеют 2 |
полем D. Для этого необходимо сгенери- |
|
|||||||||||||||||||||||||
|
|
|
|
||||||||||||||||||||||||
особенности: |
|
|
|
|
|
|
ровать пустой элемент (P=GetNode). Ин- |
|
|
|
|
||||||||||||||||
1) Заранее |
не |
определено количество |
формационному |
полю |
этого |
элемента |
Рис. 3.5 |
|
|||||||||||||||||||
элементов в структуре. |
|
|
|
присвоить значение D (INFO(P)=D), зна- |
|
||||||||||||||||||||||
|
|
|
Операции над двусвязными списками: |
||||||||||||||||||||||||
2) Элементы динамических структур не |
чению |
указателя |
на этот |
элемент |
при- |
||||||||||||||||||||||
- создание элемента списка; |
|||||||||||||||||||||||||||
имеют жесткой линейной упорядоченно- |
своить |
значение |
указателя на |
|
начало |
||||||||||||||||||||||
|
- поиск элемента в списке; |
||||||||||||||||||||||||||
сти. Они могут быть разбросаны по памя- |
списка (Ptr(P) = Lst), значению указате- |
||||||||||||||||||||||||||
- вставка элемента в указанное место |
|||||||||||||||||||||||||||
ти. |
|
|
|
|
|
|
|
|
|
ля начата списка присвоить |
значение |
||||||||||||||||
|
|
|
|
|
|
|
|
|
списка; |
|
|||||||||||||||||
Чтобы |
связать |
элементы |
динамических |
указателя Р (Lst = Р). |
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
- удаление из списка заданного элемен- |
|||||||||||||||||||||
структур между собой в состав элементов |
Вставка в начало списка |
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
та. |
|
|
|
|||||||||||||||||||
помимо |
информационных |
полей |
входят |
P=GetNode |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
поля указателей (рис. 3.1) (связок с дру- |
Info(P)=x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
гими элементами структуры). |
|
Ptr(P) = Lst |
|
|
|
|
|
|
|
|
|
11. РЕАЛИЗАЦИЯ СТЕКОВ С ПОМО- |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
Lst = P |
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЩЬЮ (ОДНОСВЯЗНЫХ) СПИСКОВ |
||||||
|
|
|
|
|
|
|
|
|
|
return |
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Любой односвязный список может рас- |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
2) Удаление |
элемента |
из |
начала одно- |
сматриваться в виде стека. Однако спи- |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
сок по сравнению со стеком в виде одно- |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
связного |
списка. |
Надо |
удалить |
|
первый |
||||||||||||
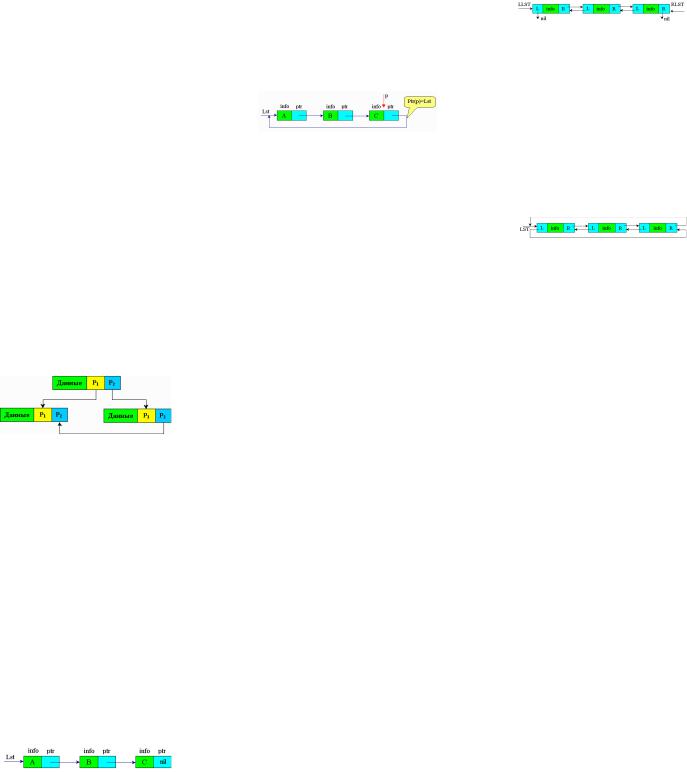
РИС.3.1 |
|
|
|
|
|
|
|
|
|
|
мерного массива имеет |
преимущества, |
|||||||||||||||
|
|
|
|
|
|
|
|
|
элемент |
списка, |
но |
запомнить |
ин- |
||||||||||||||
P1и Р2 это указатели, содержащие адреса |
так как заранее не эадан его размер. |
||||||||||||||||||||||||||
формацию, содержащуюся |
в |
поле |
Info |
||||||||||||||||||||||||
элементов, с которыми они связаны. Ука- |
Стековые операции, применимые к спи- |
||||||||||||||||||||||||||
этого элемента. Для этого введем указа- |
|||||||||||||||||||||||||||
затели содержат номер слота. |
|
скам. |
|
|
|||||||||||||||||||||||
|
тель Р, который будет указывать на уда- |
|
|
||||||||||||||||||||||||
Связные списки |
|
|
|
|
|
|
1). |
Чтобы добавить элемент в стек, надо |
|||||||||||||||||||
|
|
|
|
|
|
ляемый элемент (Р = Lst). В переменную |
|||||||||||||||||||||
Наиболее распространенными динамиче- |
в |
алгоритме вставки в |
начало списка |
||||||||||||||||||||||||
X занесем значение |
информационного |
||||||||||||||||||||||||||
скими |
структурами являются связанные |
заменить указатель Lst |
на указатель S |
||||||||||||||||||||||||
поля |
|
Info |
|
удаляемого |
элемента |
||||||||||||||||||||||
списки. |
С |
точки |
зрения |
логического |
|
|
(операция Push(S, x)). |
|
|||||||||||||||||||
(X=Info(P)). Значению указателя на на- |
|
||||||||||||||||||||||||||
представления |
различают |
линейные и |
P = GetNode |
|
|||||||||||||||||||||||
чало списка присвоим значение указате- |
|
||||||||||||||||||||||||||
нелинейные списки. |
|
|
|
|
Info(P) = x |
|
|||||||||||||||||||||
|
|
|
|
ля следующего за удаляемым |
элемента |
|
|||||||||||||||||||||
В линейных списках связи строго упоря- |
Ptr(P) = S |
|
|||||||||||||||||||||||||
(Lst |
= |
Ptr(P)). |
Удалим элемент |
(Free- |
|
||||||||||||||||||||||
дочены: указатель предыдущего элемен- |
S = P |
|
|
||||||||||||||||||||||||
Node(P)). |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
та содержит адрес последующей элемен- |
|
|
|
|
|
|
|
|
|
|
return |
|
|
||||||||||||||
Удаление из начала списка |
|
|
|
|
|
|
|||||||||||||||||||||
та или наоборот. |
|
|
|
|
|
|
|
|
|
2). |
Проверка стека на |
пустоту (Empty |
|||||||||||||||
|
|
|
|
|
P = Lst |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
К линейным |
спискам |
|
относятся |
одно- |
|
|
|
|
|
|
|
|
|
|
|
(S)) |
|
|
|||||||||
|
x=Info(P) |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
связные |
и двусвязные |
списки. К |
нели- |
|
|
|
|
|
|
|
|
|
|
if S = Nil |
|
||||||||||||
Lst = Ptr(P) |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
нейным - многосвязные. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
then print “Стекпуст” |
||||||||||||
|
|
|
FreeNode(P) |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
Элемент |
списка |
в |
общем |
случае |
пред- |
|
|
|
|
|
|
|
|
|
|
|
Stop |
|
|||||||||
return |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
ставляет собой после записи и одного |
|
|
|
|
|
|
|
|
|
|
|
endif |
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
или нескольких указателей. |
|
Двусвязный список |
|
|
|
|
|
|
return |
|
|
||||||||||||||||
Односвязные списки |
|
|
|
|
|
|
|
|
|
3) Выборкаэлементаизстека (POP(S)) |
|||||||||||||||||
|
|
|
Использование |
однонаправленных |
спи- |
||||||||||||||||||||||
Элемент |
односвязного |
|
списка содержит |
Empty(S) |
|
||||||||||||||||||||||
|
сков при решении ряда задач может вы- |
|
|||||||||||||||||||||||||
два поля (рис 3.2): информационное по- |
P = S |
|
|
||||||||||||||||||||||||
звать |
определенные трудности. |
|
Дело в |
|
|
||||||||||||||||||||||
ле (INFO) и поле указателя (PTR). |
|
|
X = Info(P) |
|
|||||||||||||||||||||||
|
том, |
что |
по |
однонаправленному |
|
списку |
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
S = Ptr(P) |
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
можно |
двигаться, |
только |
в одном |
на- |
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
FreeNode(P) |
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
правлении, от |
заглавного |
звена |
к |
по- |
|
||||||||||||
Рис. 3.2 |
|
|
|
|
|
|
|
|
return |
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
следнему звену |
списка. Между тем |
не- |
|
|
|||||||||||||||
Особенностью указателя является то, что |
|
|
|
|
|||||||||||||||||||||||
он дает только адрес последующего эле- |
редко возникает необходимость произве- |
|
12. СМЫСЛ И ОРГАНИЗАЦИЯ ОПЕРА- |
(метод маркера). Если с каким-то эле- |
начиная с X6 - увеличить их индексы на |
||||||||||||||||||||||||
ЦИЙ СОЗДАНИЯ И УДАЛЕНИЯ ЭЛЕ- |
ментом установлена связь, то однобито- |
единицу. В результате вставки получаем |
||||||||||||||||||||||||
МЕНТА ДИНАМИЧЕСКОЙ СТРУКТУРЫ. |
вое поле элемента (маркер) устанавли- |
следующий массив: |
|
|
|
|
||||||||||||||||||||
ПОНЯТИЕ |
СВОБОДНОГО |
СПИСКА |
И |
вается в "1", иначе - в "О". По сигналу |
|
|
|
|
|
|
|
|||||||||||||||
ПУЛА СВОБОДНЫХ ЭЛ-ОВ. УТИ- |
переполнения ищутся элементы, у кото- |
|
|
|
|
|
|
|
||||||||||||||||||
ЛИЗАЦИЯ |
ОСВОБОДИВШИХСЯ |
ЭЛЕ- |
рых маркер установлен в ноль, т. е. |
|
|
|
|
|
|
|
||||||||||||||||
МЕНТОВ |
|
|
|
|
|
|
|
|
включается программа сборки мусора, |
|
|
|
|
|
|
|
||||||||||
Для более эффективного использования |
которая просматривает всю отведенную |
|
|
|
|
|
|
|
||||||||||||||||||
памяти компьютера (для исключения |
память и возвращает в список свободных |
|
|
|
|
|
|
|
||||||||||||||||||
мусора, то есть неиспользуемых эле- |
элементов все элементы, не помеченные |
|
|
|
|
|
|
|
||||||||||||||||||
ментов) при работе его со списками соз- |
маркером. |
|
|
|
|
|
Данная |
процедура |
|
в больших |
массивах |
|||||||||||||||
дается свободный список, имеющий тот |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
может занимать значительное время. |
|
|||||||||||||||||
же |
формат |
полей, |
что и |
у |
функцио- |
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
В противоположность этому, в связанном |
||||||||||||||||||
нальных списков. |
|
|
|
|
|
13. Очередь и операции над ней при |
||||||||||||||||||||
|
|
|
|
|
списке операция вставки состоит в изме- |
|||||||||||||||||||||
Если у функциональных списков разный |
реализации со связными списками. |
|||||||||||||||||||||||||
нении значения 2-х указателей и генера- |
||||||||||||||||||||||||||
формат, |
то |
надо создавать |
свободный |
Указатель |
начала |
списка |
принимаем за |
|||||||||||||||||||
ции свободного элемента. Причѐм время, |
||||||||||||||||||||||||||
список |
каждого |
функционального спи- |
указатель начала очереди F, а указатель |
|||||||||||||||||||||||
затраченное на выполнение этой опера- |
||||||||||||||||||||||||||
ска. |
|
|
|
|
|
|
|
|
|
|
R, |
указывающий |
на последний элемент |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
ции, является постоянным и не зависит от |
||||||||||||||||
Количество элементов в свободном спи- |
списка - за указатель конца очереди. |
|||||||||||||||||||||||||
количества элементов в списке. |
|
|
||||||||||||||||||||||||
ске |
должно |
|
быть определено задачей, |
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
Вставка и извлечение элементов |
из |
||||||||||||||||
которую решает программа. Как правило, |
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
списка |
|
|
|
|
|
|
||||||||||||
свободный |
список |
создается |
в |
памяти |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
Сначала |
определяем |
элемент, |
|||||||||||||||
машины |
как |
стек, |
При этом создание |
1) |
Операция |
удаления из |
очереди |
|||||||||||||||||||
|
после которого необходимо про- |
|||||||||||||||||||||||||
(GetNode) нового элемента эквивалент» |
(Remove(Q, X)). |
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
вести операцию вставки или уда- |
|||||||||||||||||||||
выборке элемента свободного стека, а |
Операция удаления из очереди |
должна |
|
|||||||||||||||||||||||
|
ления. |
|
|
|
|
|
||||||||||||||||||||
операция FreeNodeдобавлению в свобод- |
проходить из ее начала. |
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
Вставка производится с помощью |
||||||||||||||||||||||
ный стек освободившегося элемента. |
|
If F = nil |
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
процедуры InsAfter(P, x), а уда- |
||||||||||||||||||
Пусть нам |
необходимо создать |
пустой |
|
then print “Очередьпуста” |
|
|||||||||||||||||||||
|
|
ление - DelAfter(P). |
|
|
||||||||||||||||||||||
список по тип; стека (рис. 3.6) с указа- |
|
|
|
Stop |
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
При этом |
рабочий |
указатель P |
|||||||||||||||||
телем начала списка - AVAIL. Разработа- |
endif |
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
должен указывать |
на |
элемент, |
|||||||||||||||||
ем |
процедуры, которые позволят нам |
P = F |
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
после которого необходимо про- |
|||||||||||||||||||
создавать пусто элемент списка и осво- |
F = Ptr(P) |
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
извести вставку или удаление. |
|||||||||||||||||||
бождать элемент из списка. |
|
|
|
|
X = Info(P) |
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
FreeNode(P) |
|
|
|
|
|
|
|
|
|
|
|
|
|||
AVAIL |
|
|
|
|
|
|
|
|
|
return |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
2) |
Проверка |
очереди |
на |
пустоту. |
|
|
|
|
|
|
|
||||||
Операция GetNode |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
(Empty (Q)) |
|
|
|
|
|
ВставкаInsAfter(P, x) |
|
|
|
||||||||||||
Разработаем |
процедуру, которая |
будет |
|
|
|
|
|
|
|
|
||||||||||||||||
If F = nil |
|
|
|
|
|
|
Пусть необходимо вставить новый элемент |
|||||||||||||||||||
создавать пустой элемент списка с ука- |
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
then |
|
|
с информационным |
полем |
x после |
эле- |
|||||||||||||||||
зателем Р. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
“Очередьпуста” |
|
|
|
|
мента, |
на который |
указывает |
рабочий |
||||||||||
Для реализации операции GetNode необ- |
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
Stop |
|
указатель P. |
|
|
|
|
|
||||||||||||||
ходимо |
указателю |
сгенерированного |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
endif |
|
|
|
|
|
|
Q = GetNode |
|
|
|
|
|
||||||||||||||
элемента присвоить значение указатель |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
return |
|
|
|
|
|
|
info(Q) = x |
|
|
|
|
|
||||||||||||||
начала |
свободного |
списка, |
а |
указатель |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
3) |
Операция вставки в очередь. (In- |
ptr(Q) = ptr(P) |
|
|
|
|
|
|||||||||||||||||||
начала перенести следующему элементу. |
|
|
|
|
|
|||||||||||||||||||||
sert(Q, X)) |
|
|
|
|
|
ptr(P) = Q |
|
|
|
|
|
|||||||||||||||
Р = Avail |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
Операция |
вставки в |
очередь |
должна |
return |
|
|
|
|
|
|
||||||||
Avail = Ptr(Avail) |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
осуществляться к ее концу. |
|
|
|
|
|
|
|
|
||||||||||||
Перед этим надо проверить, есть ли эле- |
|
|
|
|
|
|
|
|
||||||||||||||||||
P = GetNode |
|
|
|
|
|
УдалениеDelAfter(P) |
|
|
|
|||||||||||||||||
менты в списке. Пустота свободного спи- |
|
|
|
|
|
|
|
|
||||||||||||||||||
Info(P) = x |
|
|
|
|
|
Пусть необходимо |
удалить |
элемент |
спи- |
|||||||||||||||||
ска (Avail = Nil), эквивалентна пер пере- |
|
|
|
|
|
|||||||||||||||||||||
Ptr(P) = Nil |
|
|
|
|
|
ска, который следует после элемента, на |
||||||||||||||||||||
полнению функционального списка. |
|
|
|
|
|
|
||||||||||||||||||||
|
Ptr(R)= P |
|
|
|
|
|
|
который указывает рабочий указатель P. |
||||||||||||||||||
If Avail = Nil |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
R = P |
|
|
|
|
|
|
Q = ptr(P) |
|
|
|
|
|
||||||
|
|
then |
|
Print “Переполнение” |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
Return |
|
|
|
|
|
|
X = info(Q) |
|
|
|
|
|
||||||||||
|
|
|
|
|
|
Stop |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ptr(P) = ptr(Q) |
|
|
|
|
|
||||
|
|
else |
|
|
|
P = Avail |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
FreeNode(Q) |
|
|
|
|
|
||||||
|
|
|
|
|
|
Avail |
|
|
= |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
14. |
Операции вставки и извлечения |
return |
|
|
|
|
|
|
||||||||||
Ptr(Avail) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
элементов из списка. Сравнение этих |
|
|
|
|
|
|
|
|||||||||||
endif |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
операций с аналогичными массивами. |
Просмотр односвязного |
списка |
при |
||||||||||||||
return |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
Недостаток связного списка по срав- |
вставке и удалении |
|
|
|
|||||||||||||
Операция FreeNode |
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
нению с массивом. |
|
|
|
|
Обозначим через P - рабочий |
|
||||||||||||||||
При |
освобождении |
элемента |
Nod(P) |
из |
|
|
|
|
||||||||||||||||||
Просмотр |
односвязного |
списка может |
|
указатель; в начале процедуры |
||||||||||||||||||||||
функционального |
списка |
|
операцией |
|
||||||||||||||||||||||
|
производиться только |
последовательно, |
|
P = Lst. |
|
|
|
|
|
|||||||||||||||||
FreeNode(P), |
он |
заносится |
в |
свободный |
|
|
|
|
|
|
||||||||||||||||
начиная с головы (с начала) списка. Если |
Введем также указатель Q, кото- |
|||||||||||||||||||||||||
список. |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
необходимо |
просмотреть |
предыдущий |
|
рый отстает на один элемент от P |
|||||||||||||
Ptr(P) = Avail |
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
элемент, |
то |
надо |
снова возвращаться к |
|
; в начале процедуры Q = nil. |
||||||||||||||
Avail = Р |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
началу списка. Это – недостаток по срав- |
|
Когда указатель P получит зна- |
||||||||||||||||
return |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
нению с массивами. |
|
|
|
|
чение nil , цикл просмотра закан- |
||||||||||||
Утилизация |
освободившихся |
эле- |
|
|
|
|
||||||||||||||||||||
Списковая структура проявляет свои дос- |
|
чивается. |
|
|
|
|
|
|||||||||||||||||||
ментов в многосвязных списках |
|
|
|
|
|
|
|
|||||||||||||||||||
|
тоинства по сравнению с массивами тогда, |
Q =Nil |
|
|
|
|
|
|
||||||||||||||||||
Стандартные операции возвращения ос- |
|
|
|
|
|
|
||||||||||||||||||||
когда число элементов списка велико, а |
P = Lst |
|
|
|
|
|
|
|||||||||||||||||||
вободившегося |
элемента списка |
в |
пул |
|
|
|
|
|
|
|||||||||||||||||
вставку или удаление необходимо произ- |
while (P <> nil) do |
|
|
|
|
|
||||||||||||||||||||
свободных |
элементов не |
всегда дают |
|
|
|
|
|
|||||||||||||||||||
вести внутри списка. |
|
|
|
|
Q = P |
|
|
|
||||||||||||||||||
эффект, |
если используются нелинейные |
|
|
|
|
|
|
|
||||||||||||||||||
Пример |
Необходимо вставить элемент X |
|
P = ptr(P) |
|
|
|
||||||||||||||||||||
многосвязные списки. |
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
в существующий массив между 5-м и 6-м |
endwhile |
|
|
|
|
|
||||||||||||||||
Первый способ утилизации - метод счет- |
|
|
|
|
|
|||||||||||||||||||||
элементами. |
|
|
|
|
|
return |
|
|
|
|
|
|
||||||||||||||
чиков. В каждый элемент многосвязного |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
списка |
вставляется |
поле счетчика, |
ко- |
|
|
|
|
|
|
|
|
15. Примералгреш зад извлечения эл- |
||||||||||||||
торый считает |
количество |
ссылок |
на |
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
ов из списка по заданному признаку. |
||||||||||||||||||
данный элемент. Когда счетчик элемента |
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
Задача 1 Требуется просмотреть список и |
||||||||||||||||||
оказывается в нулевом состоянии, а поля |
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
удалить элементы, у которых информаци- |
||||||||||||||||||
указателей элемента находятся в состоя- |
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
онные поля равны 4. |
|
|
|
|||||||||||||||
нии nil, этот элемент может быть возвра- |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
Для проведения данной операции в мас- |
Обозначим P - рабочий указатель; в на- |
|||||||||||||||||||||||||
щен в пул свободных элементов. |
|
|
||||||||||||||||||||||||
|
|
сиве нужно сместить ―вниз‖ все элементы, |
чале процедуры P = Lst. |
|
|
|
||||||||||||||||||||
Второй |
способ |
- метод сборки |
мусора |
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||

Введем также указатель Q, который отстает на один элемент от P.
Когда указатель P найдет элемент, последний будет удален относительно указателя Q как последующий элемент.
x = 4 Q = nil P = Lst
while P <> nil do
if info(P) = x then
if Q = nil then
Pop(Lst)
|
P = Lst |
else |
|
|
DelAf- |
ter(Q) |
endif |
|
else |
|
Q = P |
|
P= Ptr(P) |
endif |
|
endwhile |
|
return |
|
16. Пример алг решения зад. вставки заданных элементов в упорядоченный список.
Задача 2 Дан упорядоченный по возрастанию info - полей список. Необходимо вставить в этот список элемент со значением X, не нарушив упорядоченности списка.Пусть X = 16. Начальные условия:
Q = Nil, P = Lst
X = 16
Q =Nil
P = Lst
while (P <> nil) and (X > info(P)) do Q = P
P = Ptr(P)
endwhile
if Q = nil then
Push(Lst, X)
endif InsAfter(Q, X) return
следования элементов (рис.3.13). |
|
|
|
|
|
признаками: |
|
||||
|
|
|
|
|
|
|
|
- дерево |
имеет |
1 |
|
|
|
|
|
|
|
|
|
элемент, на которого |
|||
LST1 - указатель на начало 1 - ого списка |
|
|
нет ссылок от других |
||||||||
|
|
элементов. Этот эле- |
|||||||||
(ориентированного |
указателем |
Р1). |
Он |
|
|
||||||
|
|
мент |
называется |
||||||||
линейный и состоит из 5-и элементов: |
|
|
|
||||||||
|
|
|
корнем дерева; |
|
|||||||
2-ой список образован из этих же самых |
|
|
|
||||||||
- в дереве можно обратиться к любому |
|||||||||||
элементов, но в произвольной последова- |
|||||||||||
элементу |
путем |
прохождения |
конечного |
||||||||
тельности. Началом 2-ого списка является |
|||||||||||
числа ссылок (указателей); |
|
|
|||||||||
3-ий элемент, а концом 2-ой элемент. |
|
|
|
||||||||
|
- каждый элемент дерева связан только с |
||||||||||
В общем случае элемент списочной струк- |
|||||||||||
одним предыдущим элементом. Любой |
|||||||||||
туры может содержать сколь угодно много |
|||||||||||
узел дерева может быть промежуточным |
|||||||||||
указателей, то есть может указывать на |
|||||||||||
либо терминальным (листом). На рис. 4.2 |
|||||||||||
любое количество элементов. |
|
|
|
||||||||
|
|
|
промежуточными являются элементы М1, |
||||||||
Можно выделить З признака отличия не- |
|||||||||||
М2, листьями - А, В, С, В, Е. Характерной |
|||||||||||
линейной структуры: |
|
|
|
|
|||||||
|
|
|
|
особенностью терминального узла являет- |
|||||||
1) Любой элемент структуры может ссы- |
|||||||||||
ся отсутствие ветвей. |
|
|
|||||||||
латься на любое число других элементов |
|
|
|||||||||
Высота - это количество уровней дерева. |
|||||||||||
структуры, то есть |
может |
иметь |
любое |
||||||||
У дерева на рис. 4.2 высота равна двум. |
|
||||||||||
число полей-указателей. |
|
|
|
|
|
||||||
|
|
|
|
Количество ветвей, растущих из узла де- |
|||||||
2) На данный элемент структуры |
может |
||||||||||
рева, называется степенью исхода узла |
|||||||||||
ссылаться любое число других элементов |
|||||||||||
(на рис. 4.2 для М1 степень исхода 2, для |
|||||||||||
этой структуры. |
|
|
|
|
|
||||||
|
|
|
|
|
М2 - З). |
|
|
|
|
||
З) Ссылки могут иметь вес, то есть подра- |
|
|
|
|
|||||||
Деревья |
могут |
классифицироваться |
по |
||||||||
зумевается иерархия ссылок. |
|
|
|
||||||||
|
|
|
степени исхода : |
|
|
||||||
Пример моделирования |
с помощью |
|
|
||||||||
1) если |
максимальная степень исхода |
||||||||||
нелинейного списка |
|
|
|
|
|||||||
|
|
|
|
равна m то это – m-арное дерево; |
|
||||||
Представим, что имеется дискретная сис- |
|
||||||||||
2) если степень исхода равна либо 0, ли- |
|||||||||||
тема, в графе состояния которой узлы – |
|||||||||||
бо m то это - полное m-арное дерево; |
|
||||||||||
это состояния, а ребра – переходы из со- |
|
||||||||||
З) если |
максимальная степень исхода |
||||||||||
стояния в состояние (рис. 3.14). |
|
|
|
||||||||
|
|
|
равна 2, то это - бинарное дерево; |
|
|||||||
|
|
|
|
|
|
|
|||||
Входной сигнал в систему это X. |
4) если степень исхода равна либо 0, ли- |
||||||||||
бо 2, то это - полное бинарное дерево. |
|
||||||||||
Реакцией на входной сигнал яв- |
|
||||||||||
Для описание связей между узлами дере- |
|||||||||||
ляется выработка выходного сиг- |
|||||||||||
ва применяют также следующую термино- |
|||||||||||
нала Y и |
переход в соответст- |
||||||||||
логию: М1 - ―отец‖ для элементов А и В. А |
|||||||||||
вующее состояние. |
|
|
|
|
|||||||
|
|
|
|
и В - ―сыновья‖ узла М1. |
|
|
|||||
Граф состояния дискретной сис- |
|
|
|||||||||
Представление деревьев |
|
|
|||||||||
темы можно представит |
в |
виде |
|
|
|||||||
Наиболее удобно деревья представлять в |
|||||||||||
комбинации одного двусвязного и |
|||||||||||
памяти ЭВМ в виде связанных списков. |
|||||||||||
трех односвязных списков, |
кото- |
||||||||||
Элемент списка должен содержа инфор- |
|||||||||||
рые вместе составляют нелиней- |
|||||||||||
мационные поля, в которых содержится |
|||||||||||
ный двусвязный список. При этом |
|||||||||||
значение узла и степень исхода, а также - |
|||||||||||
в информационных полях должна |
|||||||||||
поля число которых равно степени исхода |
|||||||||||
записываться информация |
о |
со- |
|||||||||
(рис4.З). То есть, любой указатель эле- |
|||||||||||
стояниях системы и ребрах. Ука- |
|||||||||||
мента ориентирует данный элемент с сы- |
|||||||||||
затели элементов должны форми- |
|||||||||||
новьями этого узла. |
|
|
|||||||||
ровать логические ребра |
систе- |
|
|
||||||||
Представление дерева в виде нели- |
|||||||||||
мы. |
нейного списка |
|
Реализация графа в виде нели- |
||
|
||
нейного списка |
|
17. Элементы заголовков в списках; |
|
|
|
|
|
|
|
|
|
|||||||
нелинейные связные структуры. |
|
|
|
|
|
|
|
|
|
|
||||||
Элементы заголовков в списках. |
|
|
|
|
|
|
19. Алгоритм сведения m-арного де- |
|||||||||
Для создания списка с заголовком в нача- |
|
|
|
|
|
|||||||||||
|
|
|
|
|
рева к бинарному; |
основные опера- |
||||||||||
ло списка вводится дополнительный эле- |
|
|
|
|
|
|||||||||||
|
|
|
|
|
ции над деревьями; виды обхода |
|||||||||||
мент, который может содержать информа- |
18. Понятие рекурсивных структур |
|||||||||||||||
Бинарные деревья |
|
|
||||||||||||||
цию о списке (рис. 3.11). |
|
|
|
данных. |
Деревья, их |
признаки и |
|
|
||||||||
|
|
|
Бинарные |
деревья |
являются |
наиболее |
||||||||||
|
|
|
|
|
|
|
представления |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
используемой разновидностью деревьев. |
||||||
|
|
|
|
|
|
|
Рекурсия - процесс, протекание которого |
|||||||||
|
|
|
|
|
|
|
Согласно представлению деревьев в па- |
|||||||||
В заголовок списка часто помещают ди- |
связано с обращением к самому себе (к |
|||||||||||||||
мяти ЭВМ каждый элемент будет записью, |
||||||||||||||||
этому же процессу). |
|
|||||||||||||||
намическую |
переменную, |
содержащую |
|
|||||||||||||
|
содержащей 4 поля. Значения этих полей |
|||||||||||||||
Пример рекурсивной структуры данных - |
||||||||||||||||
количество элементов в списке (не считая |
||||||||||||||||
будут соответственно ключ записи, ссыл- |
||||||||||||||||
структура данных, |
элементы которой яв- |
|||||||||||||||
самого заголовка). |
|
|
|
|||||||||||||
|
|
|
ка на элемент влево-вниз, на элемент |
|||||||||||||
|
|
|
ляются такими |
же |
структурами данных |
|||||||||||
Если список пуст, то остается только за- |
||||||||||||||||
вправо-вниз и на текст записи. |
|
|||||||||||||||
(рис. 4.1). |
|
|
|
|
||||||||||||
головок списка (рис. 3.12). |
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
При построении необходимо помнить, что |
||||||||||
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
левый сын имеет ключ меньший, чем у |
||||
Также удобно занести в информационное |
|
|
|
|
|
отца, а значение ключа правого сына |
||||||||||
поле заголовка значение указателя конца |
|
|
|
|
|
больше значения ключа отца. Например, |
||||||||||
списка. Тогда, если список используется |
|
|
|
|
|
построим бинарное дерево из следующих |
||||||||||
как очередь, то Fr=Lst, а re=Info(Lst). |
Деревья |
входят |
в |
состав |
рекурсивных |
элементов: 50, 46, 61, 48, 29, 55, 79. Оно |
||||||||||
Информационное |
поле заголовка |
можно |
имеет следующий вид: |
|
||||||||||||
использовать для хранения рабочего ука- |
структур данных. |
|
|
|
|
|
|
|||||||||
Дерево – нелинейная связанная структу- |
|
|
|
|
||||||||||||
зателя |
при |
просмотре |
списка |
Р = |
|
|
|
|
||||||||
ра данных (рис. 4.2). |
|
|
|
|
|
|||||||||||
Info(Lst). То есть заголовок – |
это деск- |
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
||||||||
риптор структуры данных. |
|
|
|
|
|
|
|
|
|
|
|
|
||||
Нелинейные связанные структуры |
|
|
|
|
|
Получили упорядоченное бинарное дере- |
||||||||||
Двусвязный список может быть нелиней- |
|
|
|
|
|
|||||||||||
|
|
|
|
|
во с одинаковым числом уровней в левом |
|||||||||||
ной структурой данных, если вторые ука- |
|
|
|
|
|
|||||||||||
|
|
|
|
|
и правом |
поддеревьях. Это - |
идеально |
|||||||||
затели |
задают |
произвольный |
порядок |
Дерево |
характеризуется |
следующими |
||||||||||
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||

сбалансированное дерево, то есть дерево, |
C-D-F-E-B-G-A – снизу вверх |
производится последовательный просмотр |
||||||||||
в котором левое и правое поддеревья |
В зависимости от того, какой по счету |
по всей таблице начиная от младшего |
||||||||||
имеют уровни, отличающиеся не более |
заход в узел приводит к обработке узла, |
адреса в оперативной памяти и кончая |
||||||||||
чем на единицу. |
|
получается реализация одного из трех |
самым старшим. |
|
|
|
|
|||||
Для создания бинарного дерева надо соз- |
видов обхода. Если обработка идет после |
Пусть k - массив ключей. Для каждого |
||||||||||
давать в памяти элементы типа (рис. 4.5): |
первого захода в узел, то сверху вниз, |
k(i) существует r(i) - данное. Key - аргу- |
||||||||||
|
|
|
если после второго, то слева направо, |
мент поиска. Ему соответствует информа- |
||||||||
|
|
|
если после третьего, то снизу вверх |
ционная запись rec. |
|
|
|
|||||
Операция V= MakeTree(Key, Rec) - созда- |
Операция исключения поддерева. Необ- |
|
|
|
|
|
|
|||||
ходимо указать узел, к которому подсое- |
|
|
|
|
|
|
||||||
ет элемент (узел дерева) с двумя указате- |
|
|
|
|
|
|
||||||
диняется исключаемое поддерево и ин- |
|
|
|
|
|
|
||||||
лями и двумя полями (ключевым и ин- |
|
|
|
|
|
|
||||||
декс этого поддерева. Исключение подде- |
|
|
|
|
|
|
||||||
формационным). |
|
|
|
|
|
|
|
|||||
|
рева состоит в том, что разрывается связь |
|
|
|
|
|
|
|||||
ВидпроцедурыMakeTree: |
|
|
|
|
|
|
|
|||||
|
с исключаемым поддеревом, т. е. указа- |
|
|
|
|
|
|
|||||
p = getnode |
|
|
|
|
|
|
|
|
||||
|
|
тель элемента устанавливается в nil, а |
|
|
|
|
|
|
||||
r (p) = rec |
|
|
Алгоритм: |
|
|
|
|
|
||||
|
|
степень исхода данного узла уменьшается |
|
|
|
|
|
|||||
k (p) = key |
|
|
|
|
|
|
|
|||||
|
|
Переменная |
search |
хранит |
номер |
|||||||
|
|
на единицу. |
|
|||||||||
v = p |
|
|
|
|||||||||
|
|
|
найденного элемента. |
|
|
|||||||
|
|
Вставка поддерева - операция, обратная |
|
|
||||||||
left (v)= nil |
|
|
|
|
||||||||
|
|
for i = 1 to n |
|
|
|
|
|
|||||
|
|
исключению. Надо знать индекс включае- |
|
|
|
|
|
|||||
right (v) = nil |
|
|
|
|
|
|
|
|||||
|
|
if k(i) = key then |
|
|
|
|||||||
|
|
мого поддерева, узел, к которому подве- |
|
|
|
|||||||
return |
|
|
|
|
|
|||||||
|
|
|
|
search = i |
|
|
||||||
|
|
шивается дерево, |
установить указатель |
|
|
|
|
|||||
Сведение m-арного дерева к бинар- |
|
|
|
|
||||||||
|
|
return |
|
|
|
|||||||
этого узла на корень поддерева, а степень |
|
|
|
|
|
|||||||
ному |
|
|
|
|
|
|
|
|||||
|
|
endif |
|
|
|
|
|
|||||
|
|
исхода данного узла увеличивается на |
|
|
|
|
|
|||||
Неформальный алгоритм: |
|
|
|
|
|
|
||||||
|
next i |
|
|
|
|
|
||||||
|
единицу. При этом в общем случае необ- |
|
|
|
|
|
||||||
1.В любом узле дерева отсекаются все |
|
|
|
|
|
|||||||
search = 0 |
|
|
|
|
|
|||||||
ходимо произвести перенумерацию сыно- |
|
|
|
|
|
|||||||
ветви, кроме крайней левой, |
соответст- |
|
|
|
|
|
||||||
return |
|
|
|
|
|
|||||||
вей узла, к которому подвешивается под- |
|
|
|
|
|
|||||||
вующей старшим сыновьям. |
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
||||||
|
дерево. |
|
|
|
|
|
|
|
|
|||
2.Соединяется горизонтальными линиями |
|
|
Если элемент в таблице не найден и необ- |
|||||||||
|
|
|
||||||||||
все сыновья одного родителя; |
|
|
|
|
||||||||
|
20. Понятие поиска, ключей; назна- |
ходимо произвести вставку, то последние |
||||||||||
З. Старшим сыном в любом узле получен- |
||||||||||||
два оператора заменяются на |
|
|
||||||||||
чение и структура алгоритмов поиска |
|
|
||||||||||
ной структуры |
будет узел, находящийся |
|
|
|||||||||
n = n + 1 |
|
|
|
|
|
|||||||
Поиск |
|
|
|
|
|
|
|
|||||
под данным узлом (если он есть). |
|
|
|
|
|
|
|
|||||
|
|
k(n) = key |
|
|
|
|
|
|||||
Поиск является одной из основных опера- |
|
|
|
|
|
|||||||
Последовательность действий |
алгоритма |
|
|
|
|
|
||||||
r(n) = rec |
|
|
|
|
|
|||||||
ций при обработке информации в ЭВМ. Ее |
|
|
|
|
|
|||||||
приведена на рис. 4.6. |
|
|
|
|
|
|
||||||
|
search = n |
|
|
|
|
|
||||||
|
назначение |
- по |
заданному аргументу |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|||||
|
|
|
return |
|
|
|
|
|
||||
|
|
|
найти среди массива данных те данные, |
|
|
|
|
|
||||
|
|
|
Поиск в односвязном списке |
|
|
|||||||
|
|
|
которые соответствуют этому аргументу. |
|
|
|||||||
|
|
|
Если таблица |
задана в |
виде списка, |
то |
||||||
|
|
|
Набор данных (любых) будем называть |
|||||||||
|
|
|
производится |
последовательный |
поиск |
в |
||||||
|
|
|
таблицей или файлом. Любое данное (или |
|||||||||
|
|
|
списке |
|
|
|
|
|
||||
|
|
|
элемент структуры) отличается каким-то |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
||||
|
|
|
признаком от других данных. Этот при- |
|
|
|
|
|
|
|||
|
|
|
знак называется ключом. Ключ может |
|
|
|
|
|
|
|||
|
|
|
быть уникальным, т. е. в таблице сущест- |
|
|
|
|
|
|
|||
|
|
|
вует только одно данное с этим ключом. |
|
|
|
|
|
|
|||
Реализация |
полученного |
бинарного |
Такой уникальный ключ называется пер- |
|
|
|
|
|
|
|||
вичным. Вторичный ключ в одной таблице |
|
|
|
|
|
|
||||||
дерева с помощью нелинейного дву- |
|
|
|
|
|
|
||||||
может повторяться, но по нему тоже мож- |
|
|
|
|
|
|
||||||
связного списка |
|
|
|
|
|
|
|
|||||
|
но организовать поиск. Ключи данных |
Алгоритм: |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|||||
|
|
|
могут быть собраны в одном месте (в дру- |
q = nil |
|
|
|
|
|
|||
|
|
|
гой таблице) или представлять собой за- |
p = table |
|
|
|
|
|
|||
|
|
|
пись, в которой одно из полей - это ключ. |
while (p <> nil) do |
|
|
|
|||||
|
|
|
Ключи, которые выделены из таблицы |
if k(p) = key then |
|
|
|
|||||
|
|
|
данных и организованы в свой файл, на- |
|
|
|
search = p |
|
||||
|
|
|
зываются внешними ключами.. Если ключ |
|
|
|
return |
|
|
|||
Основные операции с деревьями |
находится |
в записи, то он называется |
endif |
|
|
|
|
|
||||
внутренним. |
|
q = p |
|
|
|
|
|
|||||
1. Обход дерева. |
|
|
|
|
|
|
|
|||||
|
Поиском по заданному аргументу называ- |
p = nxt(p) |
|
|
|
|||||||
2. Удаление поддерева. |
|
|
|
|
||||||||
|
ется алгоритм, определяющий соответст- |
endwhile |
|
|
|
|
|
|||||
3. Вставка поддерева. |
|
|
|
|
|
|
||||||
|
вие ключа |
с заданным аргументом. Ре- |
s = getnode |
|
|
|
|
|
||||
Для выполнения обхода дерева необхо- |
|
|
|
|
|
|||||||
зультатом работы алгоритма поиска может |
k(s) = key |
|
|
|
|
|
||||||
димо выполнить три процедуры: |
|
|
|
|
|
|||||||
быть нахождение |
этого данного или от- |
r(s) = rec |
|
|
|
|
|
|||||
1 .Обработка корня. |
|
|
|
|
|
|
||||||
|
сутствие его в таблице. В случае отсутст- |
nxt(s) = nil |
|
|
|
|
|
|||||
2.Обработка левой ветви. |
|
|
|
|
|
|
||||||
|
вия данного возможны две операции: |
if q = nil then |
|
|
table = s |
|||||||
3.Обработка правой ветви. |
|
|
|
|||||||||
|
1. индикация того, что данного нет |
|
|
else |
|
|
|
|||||
Обход дерева – это последовательная |
|
|
|
|
|
|||||||
2. вставка данного в таблицу |
|
|
|
nxt(q) = s |
|
|||||||
обработка информации в узлах дерева. В |
|
|
|
|
||||||||
|
|
|
endif |
|
|
|
|
|
||||
зависимости от того, в какой последова- |
|
|
|
|
|
|
|
|
||||
|
|
|
search = s |
|
|
|
|
|
||||
тельности выполняются эти три процеду- |
|
|
|
|
|
|
|
|
||||
|
|
|
return |
|
|
|
|
|
||||
ры, различают три вида обхода. |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
||||
1 .Обход сверху вниз. Процедуры выпол- |
|
|
|
Эффективность |
последовательного |
|||||||
няются в последовательности 1-2-3. |
|
|
|
|||||||||
|
|
|
поиска |
|
|
|
|
|
||||
2.Обход слева |
направо. Процедуры вы- |
|
|
|
|
|
|
|
|
|||
|
|
|
Эффективность любого поиска может оце- |
|||||||||
полняются в последовательности 2-1-3. |
|
|
|
|||||||||
|
|
|
ниваться по количеству сравнений С ар- |
|||||||||
3.Обход снизу вверх. Процедуры выпол- |
|
|
|
|||||||||
|
|
|
гумента поиска с ключами таблицы дан- |
|||||||||
няются в последовательности 2-3-1. |
|
|
|
|||||||||
|
|
|
ных. Чем меньше количество сравнений, |
|||||||||
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
тем эффективнее алгоритм поиска. |
|
|||||
A |
|
|
|
|
|
Эффективность последовательного поиска |
||||||
|
|
|
|
|
|
|||||||
B |
G |
|
|
|
|
в массиве |
|
|
|
|
|
|
C E
D F
A-B-C-E-D-F-G – сверхувниз C-B-D-E-F-A-G – слева направо
21. Последовательный поиск и его эффективность
Последовательный поиск применяется в том случае, если неизвестна организация данных или данные неупорядочены. Тогда
Cmin =
1, Cmax = n.
Если данные расположены равновероятно во всех ячейках массива, то
Cср ≈
(n + 1)/2. |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
последовательного поиска Q( |
|
n ). |
|||||||||
Эффективность последовательного поиска |
|
|||||||||||||
|
|
|
|
|
|
|||||||||
в списке - то же самое. |
|
|
|
|
|
|
|
|||||||
Порядок |
эффективности последователь- |
|
|
|
|
|
|
|||||||
ного поиска |
|
|
O (n) |
23. Переупорядочивание таблиц с |
||||||||||
Достоинством списковой структуры явля- |
учетом вероятности поиска элемента; |
|||||||||||||
ется ускоренный алгоритм удаления или |
переупорядочивание |
путем переста- |
||||||||||||
вставки элемента в список, причем время |
новки в начало списка |
|
|
|
|
|||||||||
вставки или удаления не зависит от коли- |
Методы оптимизации поиска |
|||||||||||||
чества элементов, а в массиве каждая |
Будем считать, что искомый элемент в |
|||||||||||||
вставка или удаление требуют передви- |
таблице существует. |
|
|
|
|
|||||||||
жения примерно половины элементов. |
Можно говорить о некотором значении |
|||||||||||||
Эффективность последовательного поиска |
вероятности поиска того или иного эле- |
|||||||||||||
можно увеличить. |
|
|
|
мента в таблице. Тогда вся таблица поис- |
||||||||||
|
|
|
|
|
|
|
|
ка может быть представлена как система с |
||||||
22. Индексно-последовательный по- |
дискретными состояниями, а вероятность |
|||||||||||||
иск |
|
|
|
|
|
|
|
поиска там i |
- го элемента - |
это вероят- |
||||
При таком поиске организуется две таб- |
ность p(i) |
i - го состояния системы. |
||||||||||||
лицы: таблица данных со своими ключами |
n |
|
|
|
|
|
||||||||
(упорядоченная по возрастанию) и табли- |
р(i) = 1 |
|
|
|
|
|||||||||
ца |
индексов, которая тоже |
состоит из |
i 1 |
|
|
|
|
|
||||||
ключей данных, но эти ключи взяты из |
|
|
|
|
|
|||||||||
Количество сравнений при поиске в таб- |
||||||||||||||
основной |
таблицы |
через определенный |
||||||||||||
лице, представленной |
как |
дискретная |
||||||||||||
интервал (рис. 5.3). |
|
|
|
|||||||||||
|
|
|
система, представляет собой математиче- |
|||||||||||
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
ское ожидание значения дискретной слу- |
||||||
|
|
|
|
|
|
|
|
чайной величины, определяемой вероят- |
||||||
|
|
|
|
|
|
|
|
ностями состояний и номерами состояний |
||||||
|
|
|
|
|
|
|
|
системы. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Z = C =1p(1) + 2p(2) + 3p(3) +…+ |
||||||
|
|
|
|
|
|
|
|
np(n) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Желательно, чтобы p(1) ≥ p (2) ≥ p (3) ≥ |
||||||
|
|
|
|
|
|
|
|
…≥ p (n). |
|
|
|
|
|
|
Сначала производится последовательный |
Это минимизирует количество сравнений, |
|||||||||||||
поиск в таблице индексов по заданному |
то есть увеличивает эффективность. Так |
|||||||||||||
аргументу поиска. Как только мы прохо- |
как последовательный поиск начинается с |
|||||||||||||
дим ключ, который оказался меньше за- |
первого элемента, то на это место надо |
|||||||||||||
данного, то этим мы устанавливаем ниж- |
поставить элемент, к которому чаще всего |
|||||||||||||
нюю границу поиска. В основной таблице |
обращаются (с наибольшей вероятностью |
|||||||||||||
- low, а затем - верхнюю - hi, на которой |
поиска). |
|
|
|
|
|
||||||||
(kind>key). |
|
|
|
|
|
|
|
|
|
|||||
Например, key = 101 Поиск идет не по |
24) Метод оптимизации поиска путем |
|||||||||||||
всей таблице, а от low до hi. |
|
(Переупорядочивание таблицы) пе- |
||||||||||||
Алгоритм |
|
|
|
|
рестановки |
найденного элемента в |
||||||||
i = 1 |
|
|
|
|
начало списка |
|
|
|
|
|||||
while (i <= m) and (kind(i) <= key) do |
|
|
|
|
|
|
||||||||
|
|
|
i=i+1 |
|
|
|
|
|
|
|
|
|
||
endwhile |
|
|
|
|
|
|
|
|
|
|
||||
if i = 1 then low = 1 |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
else low = pind(i-1) |
|
Суть этого метода заключается в том, что |
||||||||
endif |
|
|
|
|
элемент списка с ключом, равным задан- |
|||||||||
if i = m+1 then hi = n |
|
ному, становится первым элементом спи- |
||||||||||||
|
|
|
|
else hi = pind(i)-1 |
ска, а все остальные сдвигаются. |
|||||||||
endif |
|
|
|
|
Этот алгоритм применим как для списков, |
|||||||||
for j = low to hi |
|
|
|
так и для массивов. Однако не рекомен- |
||||||||||
|
|
|
if key = k(j) then |
|
дуется применять его для массивов, так |
|||||||||
|
|
|
|
|
|
search = j |
как на перестановку элементов массива |
|||||||
|
|
|
|
|
|
return |
затрачивается гораздо больше времени, |
|||||||
|
|
|
endif |
|
|
|
чем на перестановку указателей. |
|||||||
next j |
|
|
|
|
Алгоритм перестановки в начало списка: |
|||||||||
search = 0 |
|
|
|
|
q= nil |
|
|
|
|
|
||||
return |
|
|
|
|
p = table |
|
|
|
|
|
||||
Эффективность |
|
|
индексно- |
while (p <> nil) do |
|
|
|
|
||||||
последовательного поиска |
|
if key = k(p) then |
|
|
|
|
||||||||
Если считать равновероятным появление |
search = p |
|
|
|
|
|||||||||
всех случаев, то эффективность поиска |
ifq = nil |
|
|
|
|
|
||||||||
можно рассчитать следующим образом: |
then 'перестановка не нужна' |
|
|
|
||||||||||
Введем обозначения: m-размер индекса; |
return |
|
|
|
|
|
||||||||
m=n/p, где p-размер шага. |
|
endif |
|
|
|
|
|
|||||||
Тогда: |
|
|
|
|
nxt(q) = nxt(p) |
|
|
|
|
|||||
Q=(m+1)/2+(p+1)/2=(n/p+1)/2 |
nxt(p) = table |
|
|
|
|
|||||||||
+(p+1)/2=n/2p+p/2+1 |
|
table = p |
|
|
|
|
|
|||||||
Продифференцируем Q по p и приравняем |
return |
|
|
|
|
|
||||||||
производную нулю: |
|
|
|
endif |
|
|
|
|
|
|||||
dQ/dp=(d/dp)(n/2p+p/2+1)=-n/2p2 |
q = p |
|
|
|
|
|
||||||||
+1/2=0 |
|
|
|
|
p = nxt(p) |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
endwhile |
|
|
|
|
|
|
Отсюда p2=n; pопт= |
n |
|
|
|
|
|
|
|||||||
|
search = 0 |
|
|
|
|
|
||||||||
Подставим pопт в выражение для Q, полу- |
return |
|
|
|
|
|
||||||||
чим следующее количество сравнений: |
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
25. Метод транспозиции при оптими- |
||||||
Q= |
|
n +1 |
|
|
|
|||||||||
|
|
|
|
зированном поиске(для переупоря- |
||||||||||
|
|
|
|
|
|
|
|
|||||||
Порядок |
эффективности |
индексyо- |
дочивания таблицы поиска |
|
|
|
||||||||
В данном методе найденный элемент пе-
реставляется на один элемент к голове списка. И если к этому элементу обращаются часто, то, перемещаясь к голове списка, он скоро окажется на первом месте.
p – рабочий указатель;
q – вспомогательный указатель, отстает на один шаг от p;
s – вспомогательный указатель, отстает на два шага от q.
Алгоритм метода транспозиции: s = nil
q = nil
p = table
while (p <> nil) do
ifkey = k(p) then„ нашли, транс-
понируем
ifq = nilthen„ переставлять не на-
до
return endif
nxt(q)= nxt(p) nxt(p) = q
if s = nil then
table = p else
nxt(s) = p search = p
endif return
endif s =q q = p
p = nxt(p) endwhile search = nil return
Этот метод удобен при поиске не только в списках, но и в массивах (так как меняются два стоящих рядом элемента).
26. Бинарный поиск
Метод используется только для отсортированных массивов.
Допустим необходимо найти элемент с ключом 52.
Обозначим:
low - индекс нижней границы интервала поиска
hi - индекс верхней границы интервала поиска
mid - индекс середины интервала поиска
Алгоритм бинарного поиска low = 1
hi = n
while (low <= hi) do
mid = (low + hi) div 2 if key = k(mid) then
search = mid return
endif
if key < k(mid) then hi = mid - 1 else
low = mid + 1
endif
endwhile search = 0 return
Эффективность бинарного поиска
Количество сравнений при бинарном поиске (эффективность) имеет порядок

О(log2N) |
|
|
|
|
сожалению, однако, заранее вероятности |
||||
|
|
|
|
|
аргументов поиска редко известны. |
||||
27. Алгоритм создания упорядоченно- |
|
|
|
|
|
||||
го бинарного дерева |
|
|
|
29. Поиск по бинарному дереву с |
|||||
Пусть заданы элементы с ключами: 14, |
включением |
|
|
|
|||||
18, 6, 21, 1, 13, 15. После выполнения |
Длительность операции поиска зави- |
||||||||
нижеприведенного алгоритма |
получится |
сит от структуры дерева. |
|
||||||
дерево, изображенное на рис.4.6. Если |
|
|
|
|
|
||||
обойти полученное дерево слева направо, |
|
|
|
|
|
||||
то получим упорядочивание: 1, 6, 13, 14, |
|
|
|
|
|
||||
15, 18, 21. |
|
|
|
|
|
|
|
|
|
Паскаль |
|
|
|
|
|
|
|
|
|
read (key, rec); tree:=maketree(key, rec); |
Наибольший эффект использования дере- |
||||||||
p:=tree; q:=tree; while not eof do begin |
|
ва |
достигается |
в |
том |
случае, |
|||
read (key, rec); v:=maketree(key, rec); |
когда дерево сбалансировано. |
|
|||||||
while p<>nil do begin q:=p; if key<p^.k |
Поиск элемента в сбалансированном де- |
||||||||
then |
|
|
|
|
реве называется бинарным поиском по |
||||
p:=p^.left; else p:=p^.right; end; if |
дереву. |
|
|
|
|||||
key<q^.k |
then |
p^.left:=v; |
else |
При бинарном поиске по дереву переби- |
|||||
p^.right:=v; end if q=tree |
|
|
рается не больше log2N элементов. Дру- |
||||||
thenwriteln(‗только корень‘); |
exit |
|
гими словами, эффективность бинарного |
||||||
Если извлекаемые элементы сформирова- |
поиска по дереву имеет порядок O(log2N) |
||||||||
ли некоторое постоянное множество, то |
Алгоритм: |
|
|
|
|||||
может быть выгодным настроить дерево |
Пусть задан аргумент key |
|
|||||||
бинарного поиска для большей эффек- |
p = tree |
|
|
|
|||||
тивности последующего поиска. |
|
whlie p <> nil do |
|
|
|
||||
Рассмотрим деревья бинарного поиска, |
if key = k(p) then |
|
|
|
|||||
приведенные на рисунках a и b. Оба со- |
|
search = p |
|
|
|
||||
держат три элемента – k1, k2, k3, где |
|
return |
|
|
|
||||
k1<k2<k3. Поиск элемента k3 требует |
endif |
|
|
|
|||||
двух сравнений для рисунка 5.6 а), и |
if key < k(p) then |
|
|
|
|||||
только одного –для рисунка 5.6 б). Число |
|
p = left(p) |
|
|
|
||||
сравнений ключей, которые необходимо |
else |
|
|
|
|||||
сделать для извлечения некоторой запи- |
|
p = right(p) |
|
|
|
||||
си, равно уровню этой записи в дереве |
endif |
|
|
|
|||||
бинарного поиска плюс 1. |
|
|
endwhile |
|
|
|
|||
Предположим, что: |
|
|
|
search = nil |
|
|
|
||
p1 – вероятность того, что аргумент поис- |
return |
|
|
|
|||||
ка key=k1; |
|
|
|
|
|
|
|
|
|
p2 – вероятность того, что аргумент поис- |
Поиск со вставкой (с включением) |
||||||||
ка key=k2; |
|
|
|
|
|
Для включения |
новой |
записи в |
|
p3 – вероятность того, что аргумент поис- |
|
дерево, прежде всего нужно найти тот |
|||||||
ка key=k3; |
|
|
|
|
|
узел, к которому можно присоединить |
|||
q0 – вероятность того, что key<k1; |
|
|
новый элемент, не нарушив упорядо- |
||||||
q1 – вероятность того, что k2>key>k1; |
|
ченности дерева. |
|
|
|||||
q2 – вероятность того, что k3>key>k2; |
Модифицируем |
процедуру поиска по |
|||||||
C1 – число сравнений в первом дереве |
|
бинарному дереву так, чтобы фикси- |
|||||||
рисунка 5.6 а); |
|
|
|
|
ровалась ссылка на узел , после обра- |
||||
C2 – число сравнений во втором дереве |
|
ботки которого поиск прекращается. |
|||||||
рисунка 5.6 б). |
|
|
|
С этой целью введем вспомогательный |
|||||
Тогда .р1+р2+р3+q0+q1+q1+q2+q3 = 1 |
|
указатель q,отстающий от |
рабочего |
||||||
Ожидаемое число сравнений в некотором |
|
pна один шаг. |
|
|
|
||||
поиске есть сумма произведений вероят- |
Алгоритм |
|
|
|
|||||
ности того, что данный аргумент имеет |
p = tree |
|
|
|
|||||
некоторое заданное значение, на число |
q = nil |
|
|
|
|||||
сравнений, не обходимых для извлечения |
while p <> nil do |
|
|
|
|||||
этого значения, где сумма берется по всем |
|
q = p |
|
|
|
||||
возможным значениям аргумента поиска. |
|
if key = k(p) then |
|
|
|||||
Поэтому |
|
|
|
|
|
|
|
search = p |
|
С1=2p1+1p2+2p3+2q0+2q1+2q2+2q3 |
|
|
|
|
return |
|
|||
C2=2p1+3p2+1p3+2q0+3q1+3q2+1q3 |
|
|
endif |
|
|
|
|||
Это ожидаемое число сравнений может |
|
if key < k(p) then |
|
|
|||||
быть использовано как некоторая мера |
|
|
|
p = left(p) |
|||||
того, насколько ―хорошо‖ конкретное де- |
|
|
|
else |
|
||||
рево бинарного поиска подходит для не- |
|
|
|
p = right(p) |
|||||
которого данного множества ключей и |
|
endif |
|
|
|
||||
некоторого заданного множества вероят- |
endwhile |
|
|
|
|||||
ностей. Так, для вероятностей, приведен- |
v = maketree(key, rec) |
|
|
||||||
ных далее слева, дерево из а) является |
if q = nil then |
|
|
|
|||||
более эффективным, а для вероятностей, |
|
|
tree = v |
|
|||||
приведенных справа, дерево из б) явля- |
|
|
else |
|
|
||||
ется более эффективным: |
|
|
|
if key < k(q) |
then |
||||
Дерево бинарного поиска, которое мини- |
|
|
|
|
left(q) = |
||||
мизирует |
ожидаемое |
число |
сравнений |
v |
|
|
|
|
|
некоторого заданного множества ключей |
|
|
|
|
else |
||||
и вероятностей, называется оптималь- |
|
|
|
|
right(q) |
||||
ным. Хотя алгоритм создания дерева мо- |
= v |
|
|
|
|||||
жет быть очень трудоемким, дерево, ко- |
|
endif |
|
|
|||||
торое он создает, будет работать эффек- |
endif |
|
|
|
|||||
тивно во всех последующих поисках. К |
search = v |
|
|
|
|||||
return
33. Сортировка методом прямого выбора
Этот метод основан на следующих принципах.
1.Выбирается элемент с наименьшим ключом.
2.Он меняется местами с первым элементом a1.
3.Затем этот процесс повторяется с оставшимися n-1 элементами, n-2 элементами и т.д. до тех пор, пока не останется один, самый "большой" элемент.
Алгоритм:
for i = 1 to n - 1
x= a(i)
k = i
for j = i + 1 to n if a(j) < x then
k = j
x = a(k)
endif next j
a(k) = a(i) a(i) = x
next i return
Эффективность:
►Число сравнений ключей C, очевидно, не зависит от начального порядка ключей. Можно сказать, что в этом смысле поведение этого метода менее естественно, чем поведение прямого включения.
Для C при любом расположении ключей имеем: C = n(n-1)/2
►Порядок числа сравнений, таким образом, О(n2)
►Число перестановок минимально Мmin = 3(n - 1) в случае изначально упорядоченных ключей
►и максимально, Мmax = 3(n - 1) + С, т.е. порядок О(n2), если первоначально ключи располагались в обратном порядке.
►В худшем случае сортировка прямым выбором дает порядок n2, как для числа сравнений, так и для числа перемещений.
30. Поиск по бинарному дереву с удалением
Удаление узла не должно нарушить упорядоченности дерева.
Возможны три варианта. Найденный узел является листом. Тогда он просто удаляется с помощью обычной процедуры удаления.
Найденный узел имеет только одного сына. Тогда сын перемещается на место отца.
У удаляемого узла два сына. Тогда на место отца помещается либо его предшественник при обходе слева направо, либо его преемник при том же обходе.
Предшественник - это самый правый элемент левого поддерева (для достижения этого элемента необходимо перейти в следующий узел по левой ветви, а затем двигаться только по правой ветви этого узла до тех пор, пока очередная ссылка не будет равна nil.
Преемник - это самый левый элемент пра-