

Глава 3. Парный регрессионный анализ взаимодействия уровня безработицы и ввп в Российской Федерации
3.1 Построение модели парной регрессии
Линейная регрессия находит широкое применение в эконометрике ввиду четкой экономической интерпретации ее параметров. Линейная регрессия сводится к нахождению уравнения вида:
![]() или
или![]()
Уравнение
![]() позволяет по заданным значениям фактораx
иметь теоретические значения
результативного признака подстановкой
в него фактических значений фактора x.
позволяет по заданным значениям фактораx
иметь теоретические значения
результативного признака подстановкой
в него фактических значений фактора x.
Расчет параметров уравнения линейной регрессии.
Таблица 1. Исходные данные.
|
|
t |
Уровень безработицы, % |
ВВП, в млрд.руб |
|
|
|
Y |
Х |
|
2000 |
1 |
10,6 |
7305,6 |
|
2001 |
2 |
9,0 |
8943,6 |
|
2002 |
3 |
7,9 |
10830,5 |
|
2003 |
4 |
8,2 |
13208,2 |
|
2004 |
5 |
7,8 |
17027,2 |
|
2005 |
6 |
7,1 |
21609,8 |
|
2006 |
7 |
7,1 |
26917,2 |
|
2007 |
8 |
6,0 |
33247,5 |
|
2008 |
9 |
6,2 |
41276,8 |
|
2009 |
10 |
8,3 |
38807,2 |
|
2010 |
11 |
7,3 |
46308,5 |
|
2011 |
12 |
6,5 |
55644,0 |
|
2012 |
13 |
5,5 |
61810,8 |
|
2013 |
14 |
5,5 |
66689,1 |
Примечание: Данные граф 3, 4 взяты из статистики Госкомстат и Статинфо.
С помощью табличного процессора Excel, вычислим коэффициенты модели парной регрессии и проверим значимость уравнения регрессии (таблица 2).
Таблица 2. Уравнение регрессии y = a + bx
|
Регрессионная статистика | |
|
Множественный R |
0,79108027 |
|
R-квадрат |
0,85994365 |
|
Нормированный R-квадрат |
0,594625327 |
|
Стандартная ошибка |
0,904808628 |
|
Наблюдения |
14 |
|
Дисперсионный анализ |
|
|
|
|
|
|
|
df |
SS |
MS |
F |
Значимость F |
|
Регрессия |
1 |
16,43014187 |
16,43014187 |
20,06909769 |
0,000752611 |
|
Остаток |
12 |
9,824143841 |
0,818678653 |
|
|
|
Итого |
13 |
26,25428571 |
|
|
|
|
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
|
Y-пересечение |
9,146954439 |
0,467008408 |
19,586273552 |
0,000000000178 |
|
Переменная X1 |
-0,000055729 |
0,000012440 |
-4,479854651 |
0,000752611 |
Примечание: режим регрессия, пакет анализа MicrosoftExcel
С помощью СТЬЮДРАСПОБР tкр, tкр= 2,144. Сравнивая значения t- статистики с рассчитанным критерием, получаем: значение всех переменных (X= -4,48) по модулю больше чем tкр= 2,144, а значит, фактор значим. Итоговое уравнение имеет вид:
Y= 9,14695 – 0,00006X.
Коэффициент этого уравнения показывает, что снижение ВВП способствует снижению уровня безработицы.
Далее следует выявить значимость выбранного фактора. Для этого следует определить адекватность построенной модели.
Рассмотрим коэффициент
детерминации ![]() .
Данный коэффициент показывает долю
полной вариации объясняемой переменной,
она детерминирована объясняющими
переменными. Для полученной нами
регрессии коэффициент детерминации
.
Данный коэффициент показывает долю
полной вариации объясняемой переменной,
она детерминирована объясняющими
переменными. Для полученной нами
регрессии коэффициент детерминации![]() это означает что модель примерно на 86%
раскрывает степень влияния фактора, то
есть модель имеет высокую значимость.
это означает что модель примерно на 86%
раскрывает степень влияния фактора, то
есть модель имеет высокую значимость.
Коэффициент множественной регрессии R=0,93, он показывает тесноту связи зависимой переменной (уровень безработицы) с объясняющим фактором, входящим в модель регрессии.
Далее оценим адекватность модели по
F-критерию Фишера. Для
этого воспользуемся функциейFРАСПОБР
в программеMicrosoftExcel.
Получаем![]() ,
,![]() =4,75.
Получаем что табличное значение меньше,
следовательно, модель адекватна и
пригодна для использования.
=4,75.
Получаем что табличное значение меньше,
следовательно, модель адекватна и
пригодна для использования.
Найдем среднюю ошибку аппроксимации. Средняя ошибка аппроксимации – это среднее отклонение расчетных значений от фактических. Для этого воспользуемся остатками модели
Таблица 3. Вывод остатков
|
ВЫВОД ОСТАТКА |
|
|
|
|
|
|
|
|
|
Наблюдение |
Предсказанное Y |
Остатки |
Стандартные остатки |
|
1 |
8,739815768 |
1,860184232 |
2,13983496 |
|
2 |
8,64853471 |
0,35146529 |
0,404302812 |
|
3 |
8,543376129 |
-0,643376129 |
-0,740098056 |
|
4 |
8,410868605 |
-0,210868605 |
-0,242569529 |
|
5 |
8,19804074 |
-0,39804074 |
-0,45788018 |
|
6 |
7,94265699 |
-0,84265699 |
-0,969337798 |
|
7 |
7,646877219 |
-0,546877219 |
-0,629091986 |
|
8 |
7,29409327 |
-1,29409327 |
-1,488640734 |
|
9 |
6,846623869 |
-0,646623869 |
-0,743834045 |
|
10 |
6,984254694 |
1,315745306 |
1,513547828 |
|
11 |
6,566211116 |
0,733788884 |
0,844103009 |
|
12 |
6,045951383 |
0,454048617 |
0,522307999 |
|
13 |
5,702278662 |
-0,202278662 |
-0,232688217 |
|
14 |
5,430416845 |
0,069583155 |
0,080043936 |
Примечание: режим регрессия, пакет анализа MicrosoftExcel
Таблица 4. Расчетная таблица для вычисления средней ошибки аппроксимации.
|
t |
Уровень безработицы, % |
ВВП, в млрд.руб |
|
|
|
|
|
|
Y |
Х |
|
|
|
|
|
1 |
10,6 |
7305,6 |
8,739816 |
1,9 |
1,9 |
0,179245 |
|
2 |
9,0 |
8943,6 |
8,648535 |
0,4 |
0,4 |
0,044444 |
|
3 |
7,9 |
10830,5 |
8,543376 |
-0,6 |
0,6 |
0,055949 |
|
4 |
8,2 |
13208,2 |
8,410869 |
0,2 |
0,2 |
0,02439 |
|
5 |
7,8 |
17027,2 |
8,198041 |
-0,4 |
0,4 |
0,051282 |
|
6 |
7,1 |
21609,8 |
7,942657 |
-0,8 |
0,8 |
0,012676 |
|
7 |
7,1 |
26917,2 |
7,646877 |
-0,5 |
0,5 |
0,070423 |
|
8 |
6,0 |
33247,5 |
7,294093 |
-1,3 |
1,3 |
0,016667 |
|
9 |
6,2 |
41276,8 |
6,846624 |
-0,6 |
0,6 |
0,096774 |
|
10 |
8,3 |
38807,2 |
6,984255 |
1,3 |
1,3 |
0,156627 |
|
11 |
7,3 |
46308,5 |
6,566211 |
0,7 |
0,7 |
0,09589 |
|
12 |
6,5 |
55644,0 |
6,045951 |
0,5 |
0,5 |
0,076923 |
|
13 |
5,5 |
61810,8 |
5,702279 |
-0,2 |
0,2 |
0,036364 |
|
14 |
5,5 |
66689,1 |
5,430417 |
0,1 |
0,1 |
0,018182 |
Примечание: данные графы 2, 3 взяты из статистики Госкомстат и Статинфо; данные графы 4 предсказанное Y из таблицы 3; данные графы 5 получены путем вычитания из графы 2 графу 5; данные графы 6 это данные графы 5 по модулю; данные графы 7 получены путем деления графы 6 на графу 2.
Таким образом, по формуле (2.22), получаем
![]()
Поскольку ошибка меньше 10%, то можно говорить о хорошем подборе модели к исходным данным.
Проанализируем уравнение регрессии полностью, то есть проверим выполняются ли предпосылки метода наименьших квадратов (МНК).
Исследование остатков ![]() предполагает проверку присутствие
следующих пяти предпосылок МНК:
предполагает проверку присутствие
следующих пяти предпосылок МНК:
случайный характер остатков;
нулевая средняя величина остатков, не зависящая от
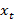 ;
;гомоскедастичность – дисперсия каждого отклонения
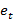 одинакова для всех значений
одинакова для всех значений 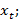
отсутствие автокорреляции остатков – значения
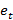 распределены независимо друг от друга;
распределены независимо друг от друга;остатки подчинены нормальному распределению.
Для анализа используем таблицу 3.
Остатки
исследуемого тренда образуют S=
5 серии, ![]() уровень значимости равен 0,05. В таблице
«Критерии значения для количества
серий» находим критические значения
уровень значимости равен 0,05. В таблице
«Критерии значения для количества
серий» находим критические значения
![]() (Таблицы,
стр. 354). Получаем, что
(Таблицы,
стр. 354). Получаем, что ![]() ,
следовательно, аналитическая форма
модели выбрана удачно.
,
следовательно, аналитическая форма
модели выбрана удачно.
Определим случайный характер остатков. Построим график отклонений фактических значений от теоретических значений признака.
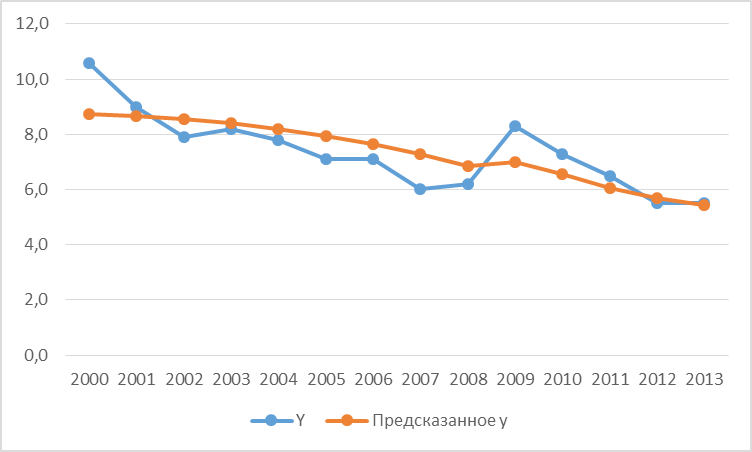
Рисунок 3.1. Фактические и теоретические значения уровня безработицы в Российской Федерации с 2000 по 2013 гг.
На рис. 3.1 показано как построенная модель парной регрессии аппроксимирует уровень безработицы в Российской Федерации с 2000 по 2013 года.
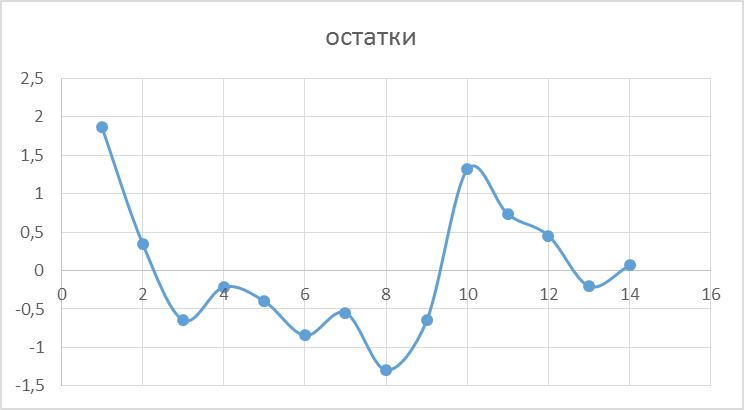
Рисунок 3.2 График остатков.
На рисунке 3.2 показан график остатков, получена горизонтальная полоса, которая показывает, что остатки представляют собой случайные величины и применение МНК оправдано.
Далее
нужно определить присутствие зависимости
остатков от ![]() .
Рассмотрим нулевую величину остатков,
которая не зависит от
.
Рассмотрим нулевую величину остатков,
которая не зависит от ![]() .
В качестве критерия рассмотрим статистику:
.
В качестве критерия рассмотрим статистику:
![]()
где
![]() – среднее арифметическое остатков
– среднее арифметическое остатков ![]() – стандартное отклонение.
– стандартное отклонение.
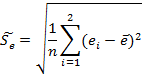
Рассчитаем критерий t-теста
Стьюдента дляm=n-1,m=14-1=13 степеней свободы и
для уровня значимости 0,05. Определим с
помощью функции СТЬЮДРАСПОБР вMicrosoftExcel. ЕслиI*![]() I,
то математическое ожидание случайных
отклонений несущественно отличается
от 0, то есть отклонение признается
несмещенным. В противно случае мат
ожидание отличается от 0, значит отклонение
признается смещенным. Так как модель
линейная и построена по МНК, то
I,
то математическое ожидание случайных
отклонений несущественно отличается
от 0, то есть отклонение признается
несмещенным. В противно случае мат
ожидание отличается от 0, значит отклонение
признается смещенным. Так как модель
линейная и построена по МНК, то![]() значит иIтоже равно 0.
Получились такие результаты:I*=
2,160, значитI* является
критическим значением. Получается, чтоI*
значит иIтоже равно 0.
Получились такие результаты:I*=
2,160, значитI* является
критическим значением. Получается, чтоI*![]() I,
то есть отклонение несмещенное.
I,
то есть отклонение несмещенное.
Далее проверим отсутствие автокорреляции остатков с помощью критерия Дарбина – Уотсона в нашем случае.
Таблица 5. Вспомогательная таблица для вычисления критерия Дарбина-Уотсона
|
t |
Y |
|
|
|
|
|
|
1 |
10,6 |
8,739815768 |
1,860184 |
- |
- |
3,460285 |
|
2 |
9,0 |
8,64853471 |
0,351465 |
-1,50872 |
2,2762328 |
0,123528 |
|
3 |
7,9 |
8,543376129 |
-0,64338 |
-0,99484 |
0,9897094 |
0,413933 |
|
4 |
8,2 |
8,410868605 |
-0,21087 |
0,432508 |
0,1870628 |
0,044466 |
|
5 |
7,8 |
8,19804074 |
-0,39804 |
-0,18717 |
0,0350334 |
0,158436 |
|
6 |
7,1 |
7,94265699 |
-0,84266 |
-0,44462 |
0,1976836 |
0,710071 |
|
7 |
7,1 |
7,646877219 |
-0,54688 |
0,29578 |
0,0874857 |
0,299075 |
|
8 |
6,0 |
7,29409327 |
-1,29409 |
-0,74722 |
0,5583318 |
1,674677 |
|
9 |
6,2 |
6,846623869 |
-0,64662 |
0,647469 |
0,4192166 |
0,418122 |
|
10 |
8,3 |
6,984254694 |
1,315745 |
1,962369 |
3,8508928 |
1,731186 |
|
11 |
7,3 |
6,566211116 |
0,733789 |
-0,58196 |
0,3386733 |
0,538446 |
|
12 |
6,5 |
6,045951383 |
0,454049 |
-0,27974 |
0,0782546 |
0,20616 |
|
13 |
5,5 |
5,702278662 |
-0,20228 |
-0,65633 |
0,4307655 |
0,040917 |
|
14 |
5,5 |
5,430416845 |
0,069583 |
0,271862 |
0,0739088 |
0,004842 |
|
Итого |
|
|
|
|
9,5232512 |
9,824144 |
Примечание: данные графы 2 взяты из статистики Госкомстат и Статинфо; данные графы 2 это предсказанное Y взяты из таблицы 3; данные графы 4 остатки взяты из таблицы 3; данные графы 5 получены путем вычитания из последующего значения предыдущего; данные графы 6 получены путем возведения в квадрат графы 5; данные графы 7 получены путем возведения в квадрат графы 4.
Таким образом, получаем из (2.27), что ![]() .
.
Из таблицы «Значения статистики
Дарбина-Уотсона» [Елисеева стр. 566]
определим критические значения критерия
Дарбина-Уотсона ![]() 1,05
и
1,05
и![]() для заданного числа наблюдений 14 и числа
независимых переменных модели равного
1, уровня значимости α=0,05.
для заданного числа наблюдений 14 и числа
независимых переменных модели равного
1, уровня значимости α=0,05.
Получаем, что 1,34<0,97<-0,34, это говорит
о том, что нет оснований отклонять
гипотезу ![]() об отсутствии автокорреляции в остатках.
об отсутствии автокорреляции в остатках.
Проверим наличие гетероскедастичности
в остатках регрессии с помощью рангового
коэффициента Спирмена. Суть этой проверки
заключается в том, что в случае
гетероскедастичности абсолютные остатки
коррелированы со значением фактора
![]() .
В таблице 6 показан расчет рангового
коэффициента Спирмена.
.
В таблице 6 показан расчет рангового
коэффициента Спирмена.
Таблица 6. Расчет рангового коэффициента корреляции Спирмена.
|
№ |
|
|
|
1 |
1 |
14 |
|
2 |
2 |
13 |
|
3 |
3 |
4 |
|
4 |
4 |
2 |
|
5 |
5 |
5 |
|
6 |
6 |
12 |
|
7 |
7 |
7 |
|
8 |
8 |
3 |
|
9 |
10 |
9 |
|
10 |
9 |
11 |
|
11 |
11 |
6 |
|
12 |
12 |
8 |
|
13 |
13 |
10 |
|
14 |
14 |
1 |
|
Итого |
105 |
105 |
Примечание: данные графы 2 получены путем ранжирования от большего к меньшему графы 4 таблицы 1; данные графы 3 получены путем ранжирования значений, взятых по модулю от меньшего к большему графы 4 таблицы 2.
После присвоения х рангов (табл. 6), нужно найти абсолютные разности между ними, возвести их в квадрат и просуммировать, затем полученные значения подставить в формулу (2.25) для расчета коэффициента ранговой корреляции Спирмена по каждому фактору.
Таблица 7. Расчет коэффициента ранговой корреляции Спирмена.
|
№ |
|
|
|
1 |
13 |
169 |
|
2 |
11 |
121 |
|
3 |
1 |
1 |
|
4 |
-2 |
4 |
|
5 |
0 |
0 |
|
6 |
6 |
36 |
|
7 |
0 |
0 |
|
8 |
-5 |
25 |
|
9 |
-1 |
1 |
|
10 |
2 |
4 |
|
11 |
-5 |
25 |
|
12 |
-4 |
16 |
|
13 |
-3 |
9 |
|
14 |
-13 |
169 |
|
Итого |
0 |
580 |
Примечание: данные графы 2 получены путем вычитания из графы 3 таблицы 6 графы 2 таблицы 6; данные графы 3 получены путем возведения в квадрат графы 2.
Коэффициент ранговой корреляции Спирмена для Х равен:
![]()
Статистическую значимость коэффициента можно определить с помощью t-критерия (2.26).
Таким образом, получаем:
![]()
Далее сравним эту величину с табличной
величиной, рассчитанной с помощью
функции в MicrosoftExelСТЬЮДРАСПОБР при α=0,05 и числе степеней
свободыn=2=14-2=12;![]()
Получается что,
![]() ,
тогда принимается гипотеза об отсутствии
гетероскедастичности остатков.
,
тогда принимается гипотеза об отсутствии
гетероскедастичности остатков.
Далее исследуем остатки на наличие нормальности распределения с помощью теста Шапиро-Уилка.
Таблица 8. Расчетная таблица для вычисления статистики W
|
№ |
|
|
|
|
|
|
|
1 |
1,8602 |
-1,2941 |
1,6747 |
0,7251 |
-1,7906 |
2,5157 |
|
2 |
0,3515 |
-0,8427 |
0,7101 |
1,3318 |
-0,5537 |
1,8855 |
|
3 |
-0,6434 |
-0,6466 |
0,4181 |
0,7460 |
1,0974 |
-0,3514 |
|
4 |
-0,2109 |
-0,6434 |
0,4139 |
0,1802 |
1,1318 |
-0,9516 |
|
5 |
-0,3980 |
-0,5469 |
0,2991 |
0,1240 |
1,7138 |
-1,5898 |
|
6 |
-0,8427 |
-0,3980 |
0,1584 |
0,9727 |
0,1960 |
0,7767 |
|
7 |
-0,5469 |
-0,2109 |
0,0445 |
0,0240 |
-0,7472 |
0,7712 |
|
8 |
-1,2941 |
-0,2023 |
0,0409 |
|
|
|
|
9 |
-0,6466 |
0,0696 |
0,0048 |
|
|
|
|
10 |
1,3157 |
0,3515 |
0,1235 |
|
|
|
|
11 |
0,7338 |
0,4540 |
0,2062 |
|
|
|
|
12 |
0,4540 |
0,7338 |
0,5384 |
|
|
|
|
13 |
-0,2023 |
1,3157 |
1,7312 |
|
|
|
|
14 |
0,0696 |
1,8602 |
3,4603 |
|
|
|
|
Итого |
|
|
9,8241 |
|
|
3,0563 |
Примечание: данные графы 2 - это остатки из табл.2, данные графы 3 получены путем ранжирования от меньшего к большему графы 2, данные графы 4 получены путем возведения квадрат графы 3, данные графы 5 взяты из табл. [http://www.machinelearning.ru/wiki/index.php?title], данные графы 6 получены путем вычитания соответствующего, но номеру значения из графы 3, данные графы 7 получены путем умножения графы5 на графу 6.
Так как
![]()
![]()
Из таблицы выбираем критическое значение W*, дляn=14 и уровня значимости α = 0,05,W*= 0,874. Так какW>W*, то можно утверждать о том, что распределение случайных отклонений нормальное. Все предпосылки МНК выполнены, что говорит о качестве полученных оценок параметров эконометрической модели.
Рассчитаем средний коэффициент эластичности по формуле (2.10):
![]()
Таким образом, ВВП является статистически значимым фактором, оказывающим влияние на уровень безработицы в Российской Федерации.