

20. Избыточное кодирование
Обнаружение ошибок — действие, направленное на контроль целостности данных при передаче данных. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после её получения.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды, избыточные коды).
Наиболее раннее применение избыточности в числовой информации для обнаружения и исправления ошибок упоминается ещё в Библии: приводятся возраст отца до рождения первого сына, число прожитых лет после рождения первого сына и общее число прожитых лет. Общее число прожитых лет можно вычислить по двум первым числам, третье число — избыточное, но эта избыточность позволяет обнаружить и исправить ошибку.
В процессе хранения данных и передачи информации неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется в основном на канальном и транспортном уровнях;
обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
исправление ошибок (forward error correction) применяется на физическом уровне.
Избыточные коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности, используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически, любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды
Пусть
кодируемая информация делится на
фрагменты длиной k
бит, которые преобразуются в кодовые
слова длиной
n
бит. Тогда соответствующий блоковый
код обычно обозначают
![]() .
При этом число
.
При этом число![]() называетсяскоростью
кода.
называетсяскоростью
кода.
Если исходные k бит код оставляет неизменными, и добавляет n − k проверочных.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из k информационных бит сопоставляется n бит кодового слова. Однако, хороший код должен удовлетворять, как минимум, следующим критериям:
1. способность исправлять как можно большее число ошибок,
2. как можно меньшая избыточность,
3. простота кодирования и декодирования.
Приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует k-мерное линейное подпространство (назовём его C) в n-мерном линейном пространстве, изоморфное пространству k-битных векторов.
Это значит, что операция кодирования соответствует умножению исходного k-битного вектора на невырожденную матрицу G, называемую порождающей матрицей.
Пусть
![]() —
ортогональное подпространство по
отношению кC,
а H —
матрица, задающая базис этого
подпространства. Тогда для любого
вектора
—
ортогональное подпространство по
отношению кC,
а H —
матрица, задающая базис этого
подпространства. Тогда для любого
вектора
![]() справедливо:
справедливо:
![]()
Расстоянием
Хемминга
(метрикой
Хемминга)
между двумя кодовыми словами
![]() и
и![]() называется
количество отличных бит на соответствующих
позициях,
называется
количество отличных бит на соответствующих
позициях,![]() ,
что равно числу «единиц» в векторе
,
что равно числу «единиц» в векторе![]() .
.
Минимальное
расстояние Хемминга
![]() является
важной характеристикой линейного
блокового кода. Она показывает насколько
«далеко» расположены коды друг от друга.
Она определяет другую, не менее важную
характеристику —корректирующую
способность:
является
важной характеристикой линейного
блокового кода. Она показывает насколько
«далеко» расположены коды друг от друга.
Она определяет другую, не менее важную
характеристику —корректирующую
способность:
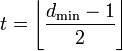 ,
округляем «вниз», так чтобы 2t
< dmin.
,
округляем «вниз», так чтобы 2t
< dmin.
Корректирующая
способность определяет, сколько ошибок
передачи кода (типа
![]() )
можногарантированно
исправить. То есть вокруг каждого кода
A
имеем t-окрестность
At,
которая At
состоит из всех возможных вариантов
передачи кода A
с числом ошибок (
)
можногарантированно
исправить. То есть вокруг каждого кода
A
имеем t-окрестность
At,
которая At
состоит из всех возможных вариантов
передачи кода A
с числом ошибок (![]() )
не болееt.
Никакие две окрестности двух любых
кодов не пересекаются друг с другом,
так как расстояние между кодами (то есть
центрами этих окрестностей) всегда
больше двух их радиусов
)
не болееt.
Никакие две окрестности двух любых
кодов не пересекаются друг с другом,
так как расстояние между кодами (то есть
центрами этих окрестностей) всегда
больше двух их радиусов
![]() .
.
Таким образом получив искажённый код из At декодер принимает решение, что был исходный код A, исправляя тем самым не более t ошибок.
Поясним на примере. Предположим, что есть два кодовых слова A и B, расстояние Хемминга между ними равно 3. Если было передано слово A, и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову A, чем к любому другому, и в частности к B. Но если каналом были внесены ошибки в двух битах (в которых A отличалось от B) то результат ошибочной передачи A окажется ближе к B, чем A, и декодер примет решение что передавалось слово B.
Коды Хемминга
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
![]() ,
где
,
где
![]() —
принятый вектор, будет равен номеру
позиции, в которой произошла ошибка.
Это свойство позволяет сделать
декодирование очень простым.
—
принятый вектор, будет равен номеру
позиции, в которой произошла ошибка.
Это свойство позволяет сделать
декодирование очень простым.
Общий метод декодирования линейных кодов
Любой
код (в том числе нелинейный) можно
декодировать с помощью обычной таблицы,
где каждому значению принятого слова
![]() соответствует
наиболее вероятное переданное слово
соответствует
наиболее вероятное переданное слово![]() .
Однако, данный метод требует применения
огромных таблиц уже для кодовых слов
сравнительно небольшой длины.
.
Однако, данный метод требует применения
огромных таблиц уже для кодовых слов
сравнительно небольшой длины.
Для
линейных кодов этот метод можно
существенно упростить. При этом для
каждого принятого вектора
![]() вычисляетсясиндром
вычисляетсясиндром
![]() .
Поскольку
.
Поскольку![]() ,
где
,
где![]() —
кодовое слово, а
—
кодовое слово, а![]() —
вектор ошибки, то
—
вектор ошибки, то![]() .
Затем с помощью таблицы по синдрому
определяется вектор ошибки, с помощью
которого определяется переданное
кодовое слово. При этом таблица получается
гораздо меньше, чем при использовании
предыдущего метода.
.
Затем с помощью таблицы по синдрому
определяется вектор ошибки, с помощью
которого определяется переданное
кодовое слово. При этом таблица получается
гораздо меньше, чем при использовании
предыдущего метода.
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Граница Хемминга и совершенные коды
Пусть имеется двоичный блоковый (n,k) код с корректирующей способностью t. Тогда справедливо неравенство (называемое границей Хемминга):
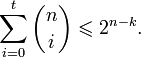
Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Коды, исправляющие ошибки, применяются:
в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
21. Распределенные системы. Отличия распределенных и сосредоточенных систем. Отличия распределенных и параллельных вычислений. Пример распределенного алгоритма – криптографический протокол принятия решения на основе случайного бита.
Под системой понимается множество элементов и связей между ними. Обозначим V – множество элементов системы. Тогда бинарное отношение R2 V V задает наличие попарных связей между элементами. Если для некоторых элементов xV и yV пара (x, y) R2 , то в системе существует связь от x к y. Если (x, y) R2 , то такой связи нет. Порядок элементов в паре важен, так как связи могут быть направленными, несимметричными.
В общем случае в системе могут быть также связи, задаваемые отношениями R4 V 4 , R5 V 5.,…, Rn V n. Здесь n – количество элементов в системе.
Вместо отношений (или вместе с отношениями) удобно рассматривать соответствующие предикаты P2 , P3 , P4 ,…, Pn . В дополнение к перечисленным рассматривают и предикаты P1 , которые можно интерпретировать как выражение свойств элементов множества V.
В общем случае систему можно описать как набор S = {V, {Pi, j}}, где индекс i обозначает арность отношения (или количество мест предиката), а индекс j дает возможность различать отношения одной и той же арности. Некоторые из предикатов P1, j могут характеризовать местоположение элемента системы. Аналогично, некоторые из предикатов P2, j могут характеризовать взаимное расположение элементов, например, расстояние, время передачи сигнала, стоимость переноса информации или вещества от одного элемента системы к другому.
Распределенными системами будем называть такие системы, для которых предикаты местоположения элементов или групп элементов играют существенную роль с точки зрения функционирования системы, а, следовательно, и с точки зрения анализа и синтеза системы.
Распределенные системы могут быть непрерывными и дискретными.
Непрерывные распределенные системы характеризуются бесконечным количеством элементов, а также тем, что в любой малой окрестности любого элемента (в смысле предикатов местоположения) находится, по крайней мере, еще один элемент.
Примеры распределенных систем.
1. Сеть газопроводов.
2. Электросети.
3. Сети связи.
4. Логистические системы.
5. Банковская система.
6. Корпорации.
7. Государственное и муниципальное управление.
Во многих случаях термин «распределенная» является альтернативой термину «сосредоточенная». Так бывает, когда существуют (или могут существовать) системы, решающие одинаковые задачи, системы, функционально эквивалентные, но конструктивно различные. Обозначим две такие системы Sd и Ssa (от английских терминов distributed и stand-alone).
Множество элементов в каждой из систем, обычно, можно разделить на два подмножества, V(Sd) = Ud Wd , V(Ssa) = Usa Wsa . Множества, обозначенные буквой U, состоят из сосредоточенных элементов, занимающих относительно небольшой объем пространства и реализующих некоторую функцию преобразования. Множества, обозначенные буквой W, состоят из элементов, связывающих некоторые сосредоточенные элементы между собой. Их основная задача не преобразование, а передача чего-либо в системе от одного элемента к другому. Элементы из множества Wd могут быть весьма разнообразными, с большим количеством характеристик.
В сосредоточенных системах элементы из множества Wsa описываются просто, а часто вообще исключаются из рассмотрения как несущественные для анализа свойств системы.
Множества сосредоточенных элементов Usa и Ud сосредоточенной и распределенной систем также могут отличаться. В сосредоточенной системе функционирование элементов из Usa инвариантно их местоположению. В распределенной системе функционирование элементов из Ud в общем случае зависит от их местоположения. Эта зависимость может быть нескольких видов:
1) зависимость от источников информации, имеющих определенное местоположение;
2) зависимость от поставленных задач, которые должны решаться элементами системы;
3) зависимость от параметров среды в различных точках.
С системой S связана цель G, ради которой система функционирует. Эта цель ставится самой системой (если система – активная), или поставлена извне. Для достижения цели в системе должна решаться задача – некоторая математическая формализация цели с четко определенным набором исходных данных и требуемых результатов.
Решение задачи предполагается получать с помощью алгоритма, т.е. предписания с указанием исполнителя (исполнителей) и последовательности элементарных шагов, которые должны быть сделаны исполнителями.
Распределенная система порождает распределенную задачу, поскольку исходные данные для задачи возникают в различных точках пространства. Также в различных точках требуются те или иные результаты решения задачи. Зачастую, задачу можно разбить в совокупность подзадач, некоторые из них могут быть сосредоточенными: все исходные данные возникают в одной точке пространства, и там же требуются результаты решения подзадачи.
Распределенная задача решается распределенным алгоритмом, собирающим исходные данные из разных точек и посылающим результаты расчетов в разные точки. Дополнительным фактором распределенности алгоритма может быть наличие нескольких исполнителей, находящихся в разных точках пространства (распределенный исполнитель).
Известно, что алгоритм оперирует кроме исходных данных, еще и промежуточными данными, а в больших системах работает с базами данных. Для распределенного алгоритма закономерно встает вопрос: как будут организованы эти данные – в виде сосредоточенной или распределенной базы данных?
Один из видов распределенных алгоритмов – протоколы. Протокол характеризуется тем, что имеется как минимум две стороны, разделенные каналом связи. На каждой из сторон выполняется локальный (сосредоточенный) алгоритм Ak . Локальный алгоритм A1 выполняется до некоторого момента времени, когда для продолжения работы ему требуются данные от другого локального алгоритма A2 . Он посылает через линию связи запрос на данные локальному алгоритму A2 . Алгоритм A2 отвечает, пересылая сообщение по линии связи. После этого локальный алгоритм A1 продолжает свою работу.
Протоколы, обычно, играют техническую роль и служат для установления режимов приема/передачи данных между удаленными объектами. В вычислительном отношении локальные алгоритмы – части протокола – не являются сложными.
Особый вид распределенных алгоритмов – криптографические протоколы. Они предназначены для доказательства одной или обеими сторонами, что они именно те, за кого себя выдают, для обмена конфиденциальной информацией и других подобных целей.
Рассмотрим один из простейших криптографических протоколов – распределенных алгоритмов.
В разных точках пространства находятся два объекта, O1 и O2 , каждый из которых решает свою часть (P1 или P2) общей задачи P. Вместе с тем, кроме стремления решить общую задачу, объекты имеют и свои частные задачи, Q1 и Q2 . Таким образом, объект O1 решает одновременно задачи P1 и Q1 , а объект O2 – задачи P2 и Q2 . И, если задачи P1 и P2 совместимы и взаимно дополняют друг друга, то задачи Q1 и Q2 – противоречат друг другу.
Следовательно, объекты O1 и O2 сотрудничают, но, одновременно, и конкурируют. А можно сказать и, что объекты конкурируют, но вынуждены сотрудничать. Смотря как расставить акценты, какая из задач, Pi или Qi , важнее для объекта Oi .
Описанная ситуация встречается очень часто. Университеты заинтересованы в решении задачи совершенствования подготовки специалистов и в этой задаче они сотрудничают. В то же время ежегодно вузы конкурируют из-за способных абитуриентов. Научные организации часто проводят совместные исследования на стыке их интересов (на стыке наук). Но они же конкурируют при распределении финансов. Два различных подразделения фирмы работают для достижения общих целей фирмы, но каждое из них хочет получить в рамках фирмы большее развитие, чем другое подразделение. В общем, друзья-соперники. Частичная конкуренция.
В нашей задаче объекты O1 и O2 должны прийти к общему компромиссному решению в интересах решения задачи P. Предположим, что имеется два равноценных (с точки зрения задачи P) решения. Одно из них также устраивает объект O1 , а другое – устраивает объект O2 . Тогда объекты O1 и O2 решают бросить жребий. Это можно сделать: написать каждое решение на своей бумажке, свернуть бумажки в трубочку, прокрутить в лототроне и одну из бумажек вытащить. Это и будет компромиссное решение.
Сложность состоит в том, что объекты O1 и O2 находятся на большом расстоянии друг от друга, и не могут провести процедуру с лототроном. Процедура с лототроном выполняется в одном месте, она возможна для сосредоточенной системы. Наша система – распределенная.
Процедуру с лототроном мог бы выполнить объект O1 и сообщить результат объекту O2 .Однако объект O2 не вполне доверяет объекту O1 . Даже телевизионная трансляция выполнения процедуры не является убедительным доказательством – это может быть искусно смонтированная запись.
Выход состоит в следующем. Обозначим одно из решений числом 0, другое – числом 1. Каждый из объектов независимо от другого должен назвать какое-нибудь целое число ni в пределах, например, от 0 до 99. Затем объекты обмениваются числами ni и вычисляют результат n1 + n2 (mod 2). Это и будет решение, т.е. число 0 или 1.
Абсолютно одновременно переслать друг другу числа ni объекты не могут. Кто-то пришлет свое число первым и окажется в невыигрышном положении. Например, O1 переслал свое число n1 объекту O2 , заинтересованному в том, чтобы выиграло решение «1». Тогда O2 , зная n1 , решает уравнение n1 + n2 (mod 2) = 1 относительно переменной n2 , и посылает O1 найденное значение n2 . Решение уравнения практически не требует времени: получив от O1 четное число, O2 должен ответить нечетным, и наоборот.
Эта несправедливость должна быть устранена. При этом ясно, что все равно какая-то из сторон обмена сообщениями первой пришлет свое число. Необходимо сделать так, чтобы у второй стороны не хватило времени на «подбор ответа».
Объекты O1 и O2 могут договориться, что вся процедура «бросания жребия» на расстоянии должна завершиться за несколько минут. Если, при этом, оба объекта знают, что подбор ответа требует нескольких часов работы суперЭВМ, то они могут быть спокойны за то, что решение не «подстроено» другой стороной.
Для обеспечения таких временных параметров в вычислениях должна использоваться функция f(x), значение которой y = f(x) при известном аргументе x вычислить можно относительно быстро. Но вот решить уравнение f(x) = y, т.е. отыскать неизвестное x при известном значении y, быстро нельзя. Более того, желательно, чтобы не было известно никаких математических методов для решения этого уравнения, кроме полного перебора или подобного ему по сложности.
Конечно, область определения функции f(x) должна быть при этом очень большой, чтобы сделать практически невозможным полный перебор. Область из двух элементов, 0 и 1, мала, область от 0 до 99 тоже недостаточна. Целые числа, с которыми приходится оперировать, должны иметь в десятичной записи не менее 150-200 цифр или не менее 512 бит в двоичной записи. Такие числа называют «длинными».
Пусть f(x) и h(z, v, w) – две таких трудно обращаемых функции. В функции h(z, v, w) первые два аргумента – длинные числа, а третий – битовый. Функции f и h известны объектам O1 и O2 , и они владеют алгоритмами быстрого вычисления значений этих функций при заданных значениях аргументов, но не умеют быстро обращать эти функции, т.е. решать уравнения.
Распределенный алгоритм бросания жребия состоит из следующих шагов.
1. Объект O2 выбирает случайным образом число x из большого интервала [0, q – 1]. Вычисляет y = f(x).
2. Объект O2 пересылает число y объекту O1 . Объект O1 не сможет восстановить число x.
3. Объект O1 выбирает случайным образом число z из большого интервала [0, q – 1]. Объект O1 выбирает случайный бит w. Эти действия могут выполняться одновременно с п.1.
4. Объект O1 вычисляет s = h(z, y, w). Число z здесь необходимо для «маскировки» бита w, а число y – для «проверки» объектом O2 правильности действий объекта O1 .
5. Объект O1 пересылает число s объекту O2 . Бит w отправляется объекту O2 , но он «запрятан» в числе s. Объект O2 не сможет восстановить этот бит. Объект O2 не сможет восстановить и число z.
6. Объект O2 выбирает случайный бит c.
7. Объект O2 отправляет бит c объекту O1 . Открытая пересылка.
8. Объект O1 пересылает число z и бит w объекту O2 . Открытая пересылка. Объект O1 уже может определить результат бросания жребия: c + w (mod 2).
9. Объект O2 вычисляет t = h(z, y, w). Здесь z и w только что получены от O1 , а y было вычислено в п.1.
10. Объект O2 сравнивает t и s, ранее полученное от объекта O1 .
11. Если t = s, то объект O2 вычисляет результат бросания жребия: c + w (mod 2).
Функции f и h могут быть различными. В частности, используются функции:
f(x) = gx (mod p) и h(z, v, w) = vwgz (mod p).
Здесь «секретные» значения x, w, z находятся в показателях степеней, и для того, чтобы найти их, требуется решить задачу дискретного логарифмирования, для которой эффективный алгоритм, существенно лучший полного перебора, неизвестен.
Константы p, q, g должны быть известны тому и другому объектам. Число p – длинное простое число. Число q – также длинное простое число, являющееся делителем числа p – 1. Число g p, не равное 1, удовлетворяет условию gq = 1 (mod p).
Распределенные алгоритмы, решающие сосредоточенные задачи.
Одно из направлений в разработке распределенных алгоритмов – высокопроизводительные вычисления. Распределенная компьютерная система в этом случае используется как один мощный вычислитель, решающий одну задачу. Известным примером является задача «взлома» шифра, созданного алгоритмом шифрования DES. Дешифровка текста не представляет трудностей, если известен ключ шифрования. Если ключ не известен, то дешифровку можно попытаться выполнить путем полного перебора. Но метод полного перебора требует очень большого времени даже для самых быстрых однопроцессорных ЭВМ.
Решение задачи можно ускорить, используя многопроцессорную ЭВМ. В этом случае вычисления распараллеливаются, т.е. все процессоры одновременно, выполняя одинаковые или различные команды, участвуют в решении задачи. Как именно происходит распараллеливание – зависит от архитектуры многопроцессорной ЭВМ. При наличии в ее составе n процессоров в идеальной ситуации ускорение вычислений может достигать величины, близкой к n раз. Реально, алгоритмы не полностью распараллеливаются, часть процессоров может простаивать в отдельные периоды времени, и производительность увеличивается менее чем в n раз.
Современные многопроцессорные машины имеют десятки и сотни процессоров, отдельные – тысячи процессоров. Но такие уникальные машины очень дороги, установлены в специальных суперкомпьютерных центрах или в военных организациях и не всегда доступны рядовым пользователям.
Альтернативой является использование отдельных компьютеров, соединенных глобальными сетями связи и принадлежащих частным лицам и различным организациям. Компьютеры могут иметь относительно невысокую производительность, но использование в сети сразу нескольких десятков или сотен тысяч компьютеров для решения одной задачи создает эффект того же суперкомпьютера, но, может быть, еще более мощного.
Именно такая распределенная компьютерная система использовалась для упомянутой задачи дешифрования. Это не была «жесткая» система – компьютеры использовались на добровольной основе, в любой момент времени любой компьютер мог выйти из системы. Но точно также и новые компьютеры могли присоединяться к уже работающим.
Идея и соответствующая технология использования глобальной сети компьютеров для решения сложной задачи получила название Grid. Если Web обеспечивает доступ к глобальным информационным ресурсам, то Grid должен обеспечить доступ к глобальным вычислительным (обрабатывающим) ресурсам. Основные проекты использования Grid в настоящее время связаны с обработкой большого числа (терабайты, пентабайты) экспериментальных данных в физике элементарных частиц, наблюдений в астрономии, расшифровкой генома человека в биологии.
22. Балансировка нагрузки в распределенных системах. Статическая и динамическая балансировки. Математическая постановка задачи динамической балансировки. Этапы балансировки. Архитектура подсистемы балансировки.
Балансировка нагрузки (Load Balancing) применяется для оптимизации выполнения распределённых (параллельных) вычислений с помощью распределённой (параллельной) ВС. Балансировка нагрузки предполагает равномерную нагрузку вычислительных узлов (процессора многопроцессорной ЭВМ или компьютера в сети). При появлении новых заданий программное обеспечение, реализующее балансировку, должно принять решение о том, где (на каком вычислительном узле) следует выполнять вычисления, связанные с этим новым заданием. Кроме того, балансировка предполагает перенос (migration – миграция) части вычислений с наиболее загруженных вычислительных узлов на менее загруженные узлы.
Следует различать декомпозицию задач и проблему отображения задач на вычислительную среду. Декомпозиция задачи является этапом процесса создания параллельной программы. Декомпозиция предназначена для разделения приложения на модули (задачи). Задачи исполняются на отдельных процессорах. В результате декомпозиции распределенного приложения появляется набор задач, которые параллельно решают задачу. Эти задачи могут быть независимыми или связанными друг с другом посредством обмена данными. Отображение (или "распределение задач") является отдельным этапом, позволяющим распределить задания, полученные на этапе декомпозиции, между процессорами.
Итак, будем считать, что распределенное приложение представляет собой совокупность логических процессов, которые взаимодействуют друг с другом, посылая друг другу сообщения. Логические процессы распределяются по разным вычислительным узлам и могут функционировать параллельно. При распределении логических процессоров по вычислительным узлам их стараются распределять так, чтобы загрузка вычислительных узлов была равномерной.
Однако при выполнении распределенного приложения возникает конфликт между сбалансированным распределением объектов по процессорам и низкой скоростью обменов сообщениями между процессорами. Если логические процессы распределены между процессорами таким образом, что издержки на коммуникацию между ними сведены к нулю, то некоторые процессоры (компьютеры) могут простаивать, в то время как остальные будут перегружены. В другом случае, "хорошо сбалансированная" система потребует больших затрат на коммуникацию. Следовательно, стратегия балансировки должна быть таковой, чтобы вычислительные узлы были загружены достаточно равномерно, но и коммуникационная среда не должна быть перегружена.
Реализация распределённой системы имитации требует разработки алгоритмов синхронизации объектов (или процессов), функционирующих на различных узлах ВС. Алгоритмы синхронизации мы уже обсуждали ранее. Эффективность реализации этих алгоритмов, в свою очередь, зависит от равномерности распределения (балансировки) вычислительной нагрузки по узлам ВС во время функционирования распределённой программной системы, каковой является, в частности, распределённая система имитации.