

эконометрика с косяками
.pdfМожно показать, что решение такой задачи сводится к нахождению собственных чисел и собственных векторов для матрицы ковариаций:
D = {σij}
где σij = cov(X(i) , X(j) )
(для реальных задач элементы этой матрицы заменяются их выборочными оценками).
Матрица ковариаций – это симметричная положительно определенная (всегда?) матрица, поэтому собственные числа этой матрицы вещественные и положительные:
λ(1) > λ(2) > ... > λ(k) > 0
Найдем собственный вектор e(1) ,
соответствующий λ(1) :
De(1) = λ(1)e(1)
Этот вектор и задает направление первой главной компоненты.
51

Направления всех остальных главных осей находятся аналогично.
Можно показать, что дисперсия для i-ой главной компоненты равна λ(i) :
DY(i) e(i) T De(i) = λ(i)
Важно то, что
DY(1) > DY(2) > ... > DY(k)
(почему ?)
и то, что
cov(Y(i) , Y(j) ) = 0 , при i j
Теперь мы можем те главные компоненты, вклад которых в суммарную дисперсию невелик, исключить из рассмотрения.
Обычно стараются оставить не более трех главных компонент.
Замечание. Если признаки в нашей матрице данных имеют различные размерности, то следует перейти к стандартизованным величинам
(Statgraphics делает это по умолчанию). Например: берем первый признак и
находим для него выборочное среднее x (1) и
52
стандартное отклонение S (1) , вместо
элементов первого столбца вписываем:
z(1) |
x(1) |
x (1) |
|
i |
|
|
|
S (1) |
, |
||
i |
|
|
|
И так поступаем со всеми столбцами – элементы получившейся матрицы будут уже безразмерными.
Для стандартизованных данных ковариационная матрица будет совпадать с матрицей корреляций
(т.е. ij rij ), на диагонали этой
матрицы будут стоять единицы (почему?). Суммарная дисперсия поэтому будет равна k.
ПРАВИЛО КАЙЗЕРА.
По умолчанию будут оставлены только те главные компоненты, для которых собственные значения больше единицы.
По существу это означает, что если данная главная компонента объясняет меньше чем k-ю часть суммарной дисперсии, то этой компонентой можно пренебречь.
Пример 6 (файл razmery.sf )
Лаб.раб.№11 с.96, пример-с.108)
53
В файле Razmery.sf представлены данные, которые используются модельерами при конструировании одежды: рост, длина рук, длина предплечий, длина ног, вес, окружность бедер, окружность груди, ширина груди.
Выделите две главные компоненты Y1 и Y2, проинтерпретируйте их. Какую долю суммарной дисперсии мы объясним, используя две главные компоненты ?
Кластерный анализ. Классификация без обучения.
Есть набор объектов, которые необходимо разбить на однородные в некотором смысле группы (кластеры (cluster) или таксоны).
/кластер-анализ = таксономия/
Про кластеры ничего не известно, иногда даже их число.
.
Точнее:, решается задача разбиения исходных данных на группы таким образом, чтобы в одной группе элементы были максимально
54

«схожи»(по какому-то заранее определенному критерию), а в разных – максимально отличались друг от друга.
При применении кластерного анализа, нам потребуются понятия расстояния между объектами и расстояния между кластерами.
Исходные данные можно опять представить в виде матрицы:
|
(1) |
x1 |
|
X x2(1) |
|
|
(1) |
xn
x1(2) ...
x2(2) ...
xn(2) ...
x1(k ) x2(k ) xn(k )
Каждая строка в этой матрице – это объект X i , а каждый столбец – это
признак.
Расстояние между объектами X1, X 2
(стрелки над обозначениями объектов в дальнейшем будем опускать)
55

1.Евклидово расстояние
|
k |
dE X1, X 2 |
x1i x2i 2 |
i1
2.Стандаризованное (нормализованное) евклидово расстояние
|
|
|
|
|
k |
|
|
dNE X1, X 2 |
|
|
z1i z2i 2 |
, |
|||
|
|
|
|
|
i 1 |
||
|
|
|
|
|
|
||
|
z(1) |
|
x(1) |
x (1) |
|
||
где |
i |
|
|
|
|
||
|
i |
|
S |
|
|
|
|
|
|
|
|
|
|
||
расстояние для стандартизованных данных
3. Хэммингово расстояние
k
dH X1, X 2 x1i x2i
i 1
Это расстояние для бинарных признаков равно количеству несовпадающих признаков.
Расстояние между кластерами
Sl – l-кластер объектов,
X l – среднее арифметическое точек, входящих в l-класс (центроид кластера).
1. Расстояние по принципу ближнего соседа |
||||||||||
. |
|
|
S , S |
|
|
min |
d X |
, X |
|
|
|
min |
1 |
2 |
|
Xi S1 , X j S2 |
i |
|
j |
|
|
2. Расстояние по принципу дальнего соседа. |
|
max S1, S2 |
max d Xi , X j |
|
Xi S1 , X j S2 |
56

3. |
Расстояние |
по |
|
принципу средней связи |
||||||||||
cp S1, S2 |
|
1 |
|
d Xi , X j |
|
|||||||||
|
|
|
||||||||||||
|
|
|
n n |
X |
S |
X |
S |
|
|
|
. |
|||
|
|
|
2 |
|
|
|
|
|||||||
|
|
|
|
1 2 |
|
i |
1 |
j |
|
|
|
|
|
|
4. Расстояние по центроидам. |
||||||||||||||
C |
S1, S2 d |
X1, X2 |
|
|
|
|
||||||||
3. |
Обобщенное расстояние (Колмогоров) |
|
|
|||||||||||
|
|
|
1 |
|
|
|
|
|
|
|
|
|
1 |
|
S , S |
|
|
|
d X |
, X |
|
|
|||||||
|
|
|
||||||||||||
|
1 2 |
|
|
|
i |
|
j |
|
||||||
|
|
n1n2 Xi S1 X j S2 |
|
|
|
|
||||||||
4. .
Иерархические процедуры
1.Агломеративные процедуры – сначала n
кластеров, на каждой итерации объединение ближайших кластеров и пересчет матрицы расстояний.
2.Дивизимные процедуры – сначала один кластер, затем его разделение.
Остановимся на одном из вариантов агломеративной процедуры.
Агломеративная процедура
При объединении классов, расстояния пересчитываются.
Формулы пересчета расстояний между кластерами при объединении:
57

Пусть имеются три кластера и мы объединяем первый и второй кластеры. Как будет выглядеть расстояние между новыми
кластерами S(1,2) , S3 = (1,2)3 ?
(здесь S(1,2) S1 S2 )
Можно проверить, что:
1.Расстояние по принципу ближнего соседа
(1,2)3 min S(1,2) , S3
min{ min S1, , S3 , min S2, , S3 } min{ 1,3 , 2,3}
2.Расстояние по принципу дальнего соседа.
(1,2)3 max S(1,2) , S3 ... max{ 1,3 , 2,3}
3.Расстояние по принципу средней связи.
(1,2)3 |
cp S(1,2) , S3 |
|
|
n1 |
|
1,3 |
|
n2 |
2,3 |
|
n1 |
n2 |
n1 n2 |
||||||||
|
|
|
|
|
|
|||||
4. Расстояние по центроидам. |
|
|
|
|
||||||
(1,2)3 C S(1,2) , S3 d X(1,2) , X3 ,
|
|
|
n1 |
|
|
|
n2 |
|
|
|
|
где X |
(1,2) |
X1 |
X 2 -центроид |
||||||||
n1 n2 |
n1 n2 |
||||||||||
нового кластера.
58
Основная идея агломеративной процедуры заключается в последовательном объединении группируемых объектов - сначала самых близких, а затем все более удаленных друг от друга.
Процедура построения классификации состоит из последовательных шагов, на каждом из которых производится объединение двух ближайших групп объектов (кластеров).
Алгоритм
0)Выбрать расстояние между объектами и кластерами
1)Объявить каждый объект кластером
2)Вычислить матрицу расстояний между этими кластерами
3)Найти минимальный элемент в этой матрице, объединить соответствующие кластеры
4)Пересчитать матрицу расстояний
5)Снова на шаг 3)
Замечание о методе Варда В отличие от описанного выше
алгоритма, в методе Варда на каждом шаге выбирается тот вариант объединения кластеров, для которого приращение суммарной внутрикластерной дисперсии
минимально.
59
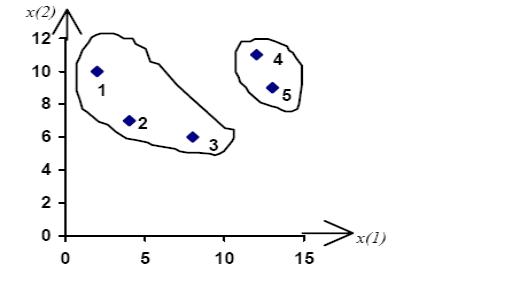
Пример .
Провести классификацию пяти семей по двум показателям: уровень расходов (млн. руб) за летние месяцы на культурные нужды, спорт и отдых (х1) и питание (х2).
№ |
1 |
2 |
3 |
4 |
5 |
семьи |
|
|
|
|
|
X1 |
2 |
4 |
8 |
12 |
13 |
|
|
|
|
|
|
X2 |
10 |
7 |
6 |
11 |
9 |
|
|
|
|
|
|
Изначально – каждая семья кластер. Расстояния берем «по ближайшему соседу»
Матрица расстояний R1 примет вид:
60