

Методуказания_Матметоды_в_ЛХ
.pdfМетки и Остатки, График остатков выделите «селекторную кноп-
ку» Новый рабочий лист → ОК. На новом рабочем листе появятся несколько таблиц (см. рис.8). Назовите этот лист «Простая регрессия 1». Файл сохраните. Аналогичным образом постройте модель зависимости запаса М от среднего возраста древостоя А, лист с результатами анализа назовите «Простая регрессия 2». Таблицы с результатами регрессионного анализа 1 и 2 (кроме таблицы остатков) и графики скопируете в отчет (Word).
Рис. 8. Окно ввода данных для регрессионного анализа
Линейная регрессионная модель имеет вид уравнения: у = b0 + btx. Коэффициенты регрессии b0 и bt, находятся в нижней табличке (рис.9)., в рассмотренном примере модель имеет вид: М=5,99 + 0,36D (коэффициенты округлены до сотых долей).
31
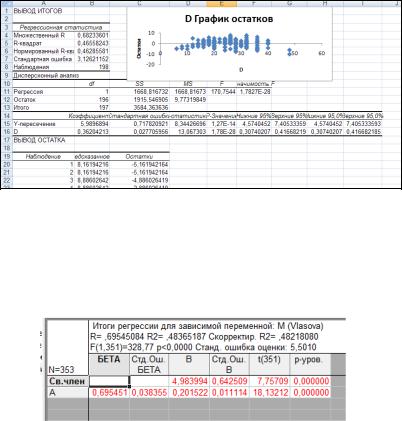
Рис.9. Результаты регрессионного анализа
2. Регрессионный анализ в среде Statistica
Откройте свой файл в среде Statistica. В строке меню выберите Ана-
лиз → Множественная регрессия → выберите переменные → зависимая: М, независимая: А → OK → Итоговая таблица регрессии. Полу-
ченную таблицу (рис.10) скопируйте в отчет вместе с заголовком.
Рис. 10. Регрессионный анализ в среде Statistica
Коэффициенты регрессии b0 и bt представлены в таблице в столбце В (рис.10), в рассмотренном примере модель имеет вид: М=4,98+0,20 А.
3. Анализ модели связи между таксационными показателями На основании полученных данных сделайте вывод о значимости и
адекватности полученных моделей, отметьте лучшую модель. Проанализируйте графики остатков. Полученные уравнения моделей и свои выводы запишите в отчет.
32
ЛАБОРАТОРНАЯ РАБОТА №7 РЕГРЕССИОННЫЙ АНАЛИЗ (МНОЖЕСТВЕННАЯ РЕГРЕССИЯ)
Цель работы: закрепить знания по разработке множественных регрессионных моделей и оценке их адекватности эмпирическим данным, получить практические навыки по автоматизации обработки данных в среде Excel и Statistica.
Содержание работы
1. Построение регрессионной модели в Excel
Раскройте лист «Исходные данные». В строке меню выберите Дан-
ные → Анализ данных → Регрессия → ОК. В появившемся окне диа-
лога нажмите кнопку в поле «Входной интервал Y» → выделите столбец с данными по запасу М, затем снова нажмите на кнопку, в поле «Входной интервал X» - выделите столбец с данными по высоте Н, диаметру D, полноте Р, затем снова нажмите на кнопку. В окне диалога
«Регрессия» поставьте «галочки» Метки, Остатки, График остатков, График подбора выделите «селекторную кнопку» Новый рабочий лист→ ОК. На новом рабочем листе появятся несколько таблиц. Назовите этот лист «Множественная регрессия 1». Файл сохраните.
Аналогичным образом постройте модель зависимости запаса М от Н, D, Р без константы. Для этого в окне диалога «Регрессия» поставьте дополнительную «галочку» Константа-ноль. Лист с результатами анализа назовите «Множественная регрессия 2». Таблицы с результатами регрессионного анализа 1 и 2 (кроме таблицы остатков) и графики скопируйте в отчет (MS Word). Запишите уравнения моделей, проанализируйте их (см. работу «Простая регрессия»), отметьте лучшую.
2. Построение регрессионной модели в среде Statistica
Откройте свой файл с исходными данными в среде Statistica. В стро-
ке меню выберите Анализ → Множественная регрессия → выберите переменные → зависимые:M, независимые: Н, D, P → ОK → нажмите на кнопку Итоговая таблица регрессии.
Полученную таблицу (рис. 9) скопируйте в отчет вместе с заголовком, сделайте вывод об адекватности модели. Если в таблице отдельные строки набраны черным шрифтом*, исключите эти переменные из модели, посмотрите, как это отразится на ее качестве, включите ее в отчет, сделайте соответствующие выводы.
*Примечание: черным шрифтом выделяются незначимые коэффициенты регрессии(уровень значимости p больше чем 0,05).
33
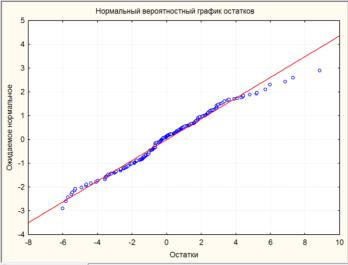
Для построения графика остатков: разверните свернутое окно Ре-
зультаты множественной регрессии → откройте вкладку Анализ остатков → Нормальный график остатков → ОК. Полученный график
(рис.11) скопируйте, вставьте в отчет, проанализируйте.
Рис. 11. Графическое представление остатков регрессии в среде Statistica
34
ЛАБОРАТОРНАЯ РАБОТА №8. РАЗРАБОТКА МНОЖЕСТВЕННЫХ МОДЕЛЕЙ РОСТА ДРЕВОСТОЯ ЭЛЕМЕНТОВ ЛЕСА В СРЕДЕ PROGNOZ
Цель работы: закрепить знания по разработке множественных регрессионных моделей роста древостоя элементов леса на основе материалов фактического состояния лесного фонда объекта, представить их в аналитическом и графическом видах, а также получить практические навыки работы на ПК в среде Prognoz.
Краткие теоретические сведения
Система «Прогноз» предназначена для использования экспертами при разработке математических моделей роста элемента леса и представление их в аналитическом, графическом и табличном видах, при анализе, обработке входной информации о таксационной характеристике древостоя элемента леса. Пользователями системы являются эксперты.
Содержание работы
1. Ознакомление с интерфейсом программы Prognoz и построение множественных регрессионных моделей
Откройте программу Prognoz: Пуск → Программы → Prognoz 2→ prognoz 2.exe. В строке меню выберите: Кнопка “Office” → Открыть → Укажите путь: Папка: D:\MatMethods\id\id_LX-№ группы. Имя файла: v12.dat (№ вашего варианта ) → Тип файла: *.dat - нажмите кнопку Открыть → После сообщения программы о принятии к обработке задания → Расчет. Ознакомьтесь с полученными статистиками основных таксационных показателей и интерфейсом программы. (рис.12 )
Откройте вкладку Оценка модели → оцените предложенную модель. В графическом виде данная зависимость представлена на вкладке График. Модель считается пригодной для использования, если для каждой переменной, включенной в модель | Т | > 2, коэффициент детерминации R2 > 0,5 (качество модели улучшается по мере приближения значение R2 к 1). Далее самостоятельно постройте множественные регрессионные модели относительного текущего прироста по среднему диаметру (Pd), средней высоте (Ph), среднему запасу (Рm) в зависимости от других таксационных показателей, выберите оптимальные и представьте их в аналитическом и графическом видах.
35
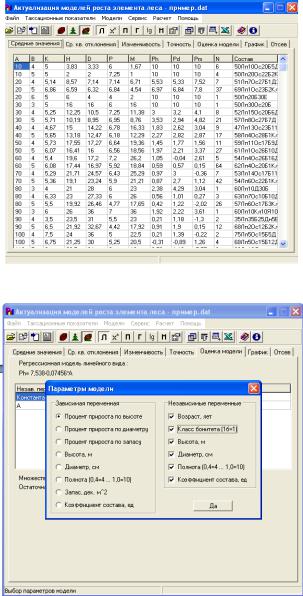
Рис. 12. Статистики основных таксационных показателей в среде Prognoz
Рис. 13. Окно для ввода параметров модели в среде Prognoz
36
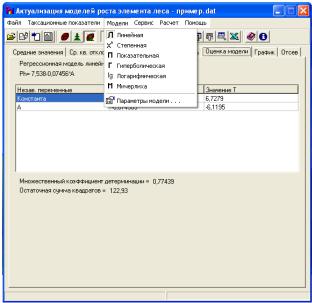
Откройте вкладку Оценка модели → выберите в меню вид модели → Параметры модели: установите зависимую переменную Ph и несколько независимых переменных → нажмите на кнопку Да → Расчет
(рис. 13).
Оцените полученную модель, поэкспериментируйте с изменением вида модели и набором независимых переменных до достижения наилучшего результата. Уравнение оптимальной модели запишите, откройте вкладку График, «сфотографируйте» график нажав клавишe Prt Scr, вставьте в отчет (MS Word). Повторите вышеописанные действия для
Pd, Pm.
Рис. 14. Вкладка для выбора вида модели в среде Prognoz
2. Актуализация базы данных (в Excel)
В свой рабочий файл в Excel вставьте новый лист, назовите его «Ак-
туализация БД», скопируйте на него с листа «Исходные данные» суще-
ствующую базу данных (PP...Vydel), после столбца «Vydel» добавьте 6 новых (табл. 7).
37
Таблица 7. Структура исходных данных
рр |
… |
Vydel |
Н а+10 |
D а+10 |
М а+10 |
H |
D |
M |
Б |
|
7 |
|
|
|
|
|
|
… |
… |
… |
|
|
|
|
|
|
Проведите соответствующие расчеты по формулам:
На+10 = Ha + (Ha * Ph)/100 Dа+10 = Da + (Da * Pd)/100 Mа+10 = Ma + (Ma * Pm)/100
- значения ср. высоты, ср. диаметра, ср. запаса
древостоя через 10 лет;
На, Da, Ma - значения ср. высоты, ср. диаметра, ср. запаса в настоящее время (из существующей базы данных);
Ph, Pd, Pm - относительный текущий прирост по средней высоте, среднему диаметру, среднему запасу (вычисляется по Вашим оптимальным моделям).
Рассчитайте изменение по средним таксационным показателям:
Нi = | (Ha - На+10)/Ha * 100 | Di = | (Da - Dа+10)/Da * 100 | Mi = | (Ma - Mа+10)/Ma *100 |
Для того чтобы сделать вычисления по модулю, выделите 1-ю ячейку в столбце ДН, выберите в меню Вставка → Функция → Математические → ABS → введите формулу, используя соответствующие ссылки → OK → Enter. Полученное значение растяните до конца столбца. Аналогично вычислите D, M.
3. Оценка актуализации БД
Рассчитайте основные статистики для На+10, Dа+10, Ma+10, Н, ΔD, ΔM: Данные → Анализ данных → Описательная статистика. В поле
«Входной интервал» → выделите столбцы с данными На+10, Dа+10,
Ma+10, Н, ΔD, ΔM, поставьте «птички» Метки в первой строке и Итоговая статистика → выделите «селекторную кнопку» Новый рабочий
лист → ОК. Полученную таблицу скопируйте и вставьте на лист «Основные статистики» как продолжение имеющейся там таблицы. Отредактируйте ее и скопируйте в отчет. Сравните значения основных таксационных показателей бывших и измененных. Сделайте выводы.
38
ЛАБОРАТОРНАЯ РАБОТА №9. МНОГОМЕРНЫЕ МЕТОДЫ ИССЛЕДОВАНИЯ. КЛАСТЕРНЫЙ АНАЛИЗ
Цель работы: ознакомиться с процедурой кластерного анализа в среде Statistica, провести на его основе селекционную оценку вегетативного и семенного потомства плюсовых деревьев сосны обыкновенной.
Краткие теоретические сведения
Кластерный анализ объединяет различные процедуры, используемые для проведения классификации. В результате применения этих процедур исходная совокупность объектов разделяется на кластеры или группы (классы) схожих между собой объектов. Под кластером обычно понимают группу объектов, обладающую свойством плотности, дисперсией, отделимостью от других кластеров, формой, размером.
Содержание работы
Исходные данные (по материалам О.В. Шейкиной) представляют собой замеры, произведенные на 5 участках у вегетативного и семенного потомства плюсовых деревьев сосны обыкновенной: высоты ствола (Н), диаметра ствола (D), водоудерживающей способности хвои (Humidity). Требуется выделить наиболее перспективные группы плюсовых деревьев для дальнейшего использования их при создании лесных культур.
Создайте новый файл в Excel, скопируйте в него свой вариант* из файла с исходными данными: D:\ Mat Methods\ID klaster.xls. Новый файл сохраните в папке с номером своей группы, указав Имя файла:
Ваша фамилия_klaster , Тип файла: Книга Microsoft Excel 97-2003. За-
кройте его, а потом откройте в среде Statistica. В строке меню выберите Файл → Открыть, укажите соответствующий путь, при этом выберите
Тип файла: Excel Files(*.xls).
В появившемся окне диалога выберите: Импортировать выбран-
ный лист в таблицу данных → ОК, затем поставьте «птички» Имена переменных из первой строки и Имена наблюдений из первого столбца → ОК.
*Примечание: варианты исходных данных для выполнения лабораторной работы выбираются в соответствии с первыми буквами фамилий: А, Е, Л, Р, Х, Э - 2 участок клоны; Б, Ж, М, С, Ц, Ю – 3 участок клоны; В, З, Н, Т, И, Я – 1 участок семья; Г,И, О,У, Ш – 2 участок семья; Д, К, П, Ф, Щ, Ч – 3 участок семья.
39
Вполученном листе данных отредактируйте формат записи наблю-
дений: откройте вкладку Наблюдения → Диспетчер имени наблюде-
ний → Число знаков: 3 → OK. Сохраните внесенные изменения.
Встроке меню выберите Анализ → Многомерный разведочный анализ → Кластерный анализ. Выберите метод кластеризации метод К-средних →OK. Нажмите на кнопку Переменные →отметьте все пе-
ременные: h; d, humidity, в поле Кластер: Наблюдения, Количество кластеров: 3; Количество итераций: 10 → ОК.
Вокне результатов выберите закладку Дополнительно, последовательно выделите кнопки:
Итоги: средние кластеров и евклидовы расстояния; Дисперсионный анализ; График средних;
Описательная статистика для каждого кластера; Члены каждого кластера и расстояния.
Просмотрите, проанализируйте и скопируйте в отчет вместе с заголовками таблицы и график.
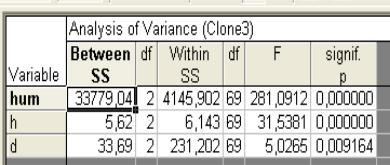
Cделайте выводы о том, какой фактор оказал наибольшее влияние на разделение объектов по кластерам (см. табл. «Дисперсионный анализ» (рис.15) и «График средних» (рис.16); из полученных кластеров выделите тот, в котором наблюдается наибольшая засухоустойчивость растений, наименьшая, и кластер, занимающий среднее положение между ними; перечислите номера плюсовых деревьев, в соответствии с полученной классификацией.
Рис. 15. Результаты дисперсионного анализа для выделения кластеров
40