

41) Раньше было 5в.Сййчас – 3,3в; 2,4в; 2,9в. Увв – 3,3в.
Если проц и УВВ работают на одном напряжении, то это унифицированный режим. Если на разных – расщепление уровня напряжения.
Система охлажд.За счет повышения такт частоты и интеграции элементов при поизводительности проц, проц стали выделять больше тепла, поэтому используют теплоотводы: пассивные и активные.
Пассивные – аллиминиевый радиатор, через пластины которого продувается воздух от вентилятора БП. Он имеет 100% надежность. Никакого зазора между радиатором и проц быть не должно.
Активные – содержат дополнительный вентилятор, который питается от системной платы и потребляет 12В и подкл к 12В разъему.Для более мощных компьютеров таких теплоотводов не хватает.
Бп – самый ненадежный элемент (преобразует 220В в 12В).
На БП имеется свой ФФ. ФФ мат платы и БП должны совпадать. Для современного БП стандарт АТХ 2.1, размер вент, крепление, уровни напряжения, напряжение вентилятора, размеры своих внутр элементов.
Все БП поддерживают -5-5,5В, -12-12В.Это «-» напряжение было необходимо для анал накопителей – гибких дисков. Оно поступает на 5 контакт шины ISA.
42).Современные платы исполняются на основе чипсетов (Chipset) - наборов из нескольких БИС, реализующих все необходимые функции связи основных компонентов - процессора, памяти и шин расширения. Чипсет определяет возможности применения различных типов процессоров, основной и кэш-памяти и ряд других характеристик системы, определяющих возможности ее модернизации.
Различаются : intel(мостовая и хабовая) и не intel
Гнезда: 3 типа соед.:1) не посредственное впаивание 2)гнездо типа слот, 3) генздо типа сокет. Сокет:однозгачно определяет типы подключаемых процессоров, напряж. Питания и шины процессоров. Слот: генздо процессора не определяет быстродействие матер. платы . Быстрод. определяется её архтектурой.Набор микросхем системной логики (или чипсет) является соединеним процессора с различными компонентами комьютера. Процессор не может взаимодействовать с памятью, платами адаптеров и различными устройствами без помощи наборов микросхем. Набор микросхем системной логики включает в себя интерфейс шины процессора (которая называется также Front-Side Bus или FSB), контроллеры памяти, контролеры шины, контроллеры ввода-вывода и т.п. Поэтому он определяет в конечном счете тип и быстродействие используемого процессора, рабочую частоту шины, скорость, тип и объем памяти. Системы с мощными процессорами могут проигрывать в быстродействии системам, содержащим процессоры меньшей частоты, но боле функциональные наборы микросхем. Начиная с 1989 года (с момента появления шины EISA), и до настоящего времени лидером в разработке и производстве микросхем системной логики является компания Intel.
При создании набора микросхем Intel использует два различных типа архитектуры: мостовую (North/South Bridge) и более современную hub-архитектуру, которая используется во всех последних наборах микросхем сстемной логики серии 800.
Большинство наборов микросхем системной логики фирмы Intel (и ее конкурентов) имеют двухуровневую архитектуру и состоят из двух блоков: северный мост (North Bridge («Северный мост») — это компонент соединения самой быстрой в ПК внешней шины процессора FSB (Front Side Bus) (800, 533, 400, 266, 200, 133, 100, 66 МГц) с более медленными шиными – шиной ускоренного графического порта AGP (Accelerated Graphics Port, 533,133,66 МГц) и периферийной шиной PCI (Peripheral Component Interconnect — 66, 33 МГц). Он содержит контроллеры кэш-памяти и оперативной памяти) и южный (South Bridge («Южный мост») представляет собой ИМС системной логики с более низким быстродействием, чем «Северный Мост». Это отдельный чип, который может использоваться в различных чипсетах (наборах микросхем)). а также микросхемы Super I/O (Super I/O представляет собой микросхему, подключаемую к шине ISA). В новой серии 800 набора микросхем используется hub-архитектура, где компонент North Bridge называется Memory Hub (ICH). В hub-архитектуре соединение компонентов выполняется с помощью нового интерфейса (hub-интерфейса).
Иерархия шин не зависит от разрядности шины 1)FSB,3)MB-шина памяти,4)PCI express x10,32, 5)PCI,SATA,6)PCI expres x1,x8?ATA 7)LPC
43) Современные платы исполняются на основе чипсетов (Chipset) - наборов из нескольких БИС, реализующих все необходимые функции связи основных компонентов - процессора, памяти и шин расширения. Чипсет определяет возможности применения различных типов процессоров, основной и кэш-памяти и ряд других характеристик системы, определяющих возможности ее модернизации.
Большинство наборов микросхем системной логики фирмы Intel (и ее конкурентов) имеют двухуровневую архитектуру и состоят из двух блоков, а также микросхемы:
северный мост (North Bridge) — это компонент соединения самой быстрой в ПК внешней шины процессора FSB (Front Side Bus) (800, 533, 400, 266, 200, 133, 100, 66 МГц) с более медленными шиными – шиной ускоренного графического порта AGP (Accelerated Graphics Port, 533,133,66 МГц) и периферийной шиной PCI (Peripheral Component Interconnect — 66, 33 МГц). Он содержит контроллеры кэш-памяти и оперативной памяти. Наравне с центральным процессором, данная ИМС работает на полной тактовой частоте системной платы (на частоте шины FSB). Этот мост организован на одном чипе
южный мост (South Bridge) представляет собой ИМС системной логики с более низким быстродействием, чем «Северный Мост». Это отдельный чип, который может использоваться в различных чипсетах (наборах микросхем). Как правило, в чипсетах «Северный Мост» представлен различными разработками, в то время как «Южный Мост» «перекочевывает» из одного чипсета в другой. Южный мост содержит интерфейс подключения к шине PCI (33, 66 МГц) и содержит интерфейс шины ISA (8 МГц). Кроме того, обячно он содержит две схемы, реализующие интерфейс контроллера жесткого диска IDE, а также интерфейс универсальной последовательной шины USB (Universal Serial Bus). В состав моста входят также схемы, реализующие функции памяти конфигурации ПК и компоненты часов реального времени RTC CMOS RAM. Этот мост содержит также все компоненты, необходимые для шины ISA, включая контроллер ПДП и контроллер прерываний.
Super I/O (Super I/O представляет собой микросхему, подключаемую к шине ISA. Этот компонент чипсета часто поставляется сторонними производителями и содержит все стандартные периферийные устройства, в частности:• параллельный порт;• два последовательных порта;• контроллер накопителя на гибких магнитных дисках (НГМД);• интерфейс клавиатуры;• элементы интерфейса мыши.К числу дополнительных компонентов могут быть отнесены:• RTC CMOS RAM;• контроллеры IDE;• интерфейс игрового порта). Один из недостатков Super I/O — подсоединение к системе с помощью интерфейса шины ISA, что ограничивает ее быстродействие и эффективность возможностями этой шины, работающей на частоте 8 МГц.
44) Современные платы исполняются на основе чипсетов (Chipset) - наборов из нескольких БИС, реализующих все необходимые функции связи основных компонентов - процессора, памяти и шин расширения. Чипсет определяет возможности применения различных типов процессоров, основной и кэш-памяти и ряд других характеристик системы, определяющих возможности ее модернизации.
Различаются : intel(мостовая и хабовая) и не intel
Hub-архитектура обладает следующими преимуществами по отношению к мостовой архитектуре:
Увеличенная пропускная способность. Hub-интерфейс представляет собой 8-разрядный 4-х тактный интерфейс с тактовой частотой 66 МГц, имеющий удвоенную по отношению к PCI пропускную способность. Это объясняется тем, что за один цикл данные передаются четыре раза. Кроме того, пропускная способность устройств PCI увеличивается, так как отсутствует южный мост, передающий данные через микросхему Super I/O, и загружающий тем самым шину PCI.
Уменьшенная загрузка шины PCI. Hub-интерфейс не зависит от шины PCI.
Уменьшение монтажной схемы. Несмотря на удвоенную по сравнению с PCI пропускную способность, hub-интерфейс имеет ширину всего 8 разрядов и требует для соединения с системной платой 15 сигналов. У шины PCI не менее 64 сигналов, что приводит к генерации электромагнитных помех, ухудшению сигнала, появлению «шума» и, в итоге, к увеличению себестоимости плат.
Компонент MCH обеспечивает передачу данных между шиной процессора (100/133 МГц) и шиной AGP (66 МГц) через hub-интерфейс, а компонент ICH связывает hub-интерфейс с портами IDE ATA-66 и шиной PCI (33 МГц).
Кроме того, в микросхеме ICH содержится новая шина Low-Pin-Count (LPC), представляющая собой 4-разрядную версию шины PCI, разработанная для поддержки микросхем системной платы ROM BIOS и Super I/O.
45) Современные платы исполняются на основе чипсетов (Chipset) - наборов из нескольких БИС, реализующих все необходимые функции связи основных компонентов - процессора, памяти и шин расширения. Чипсет определяет возможности применения различных типов процессоров, основной и кэш-памяти и ряд других характеристик системы, определяющих возможности ее модернизации.
Различаются : intel(мостовая и хабовая) и не intel
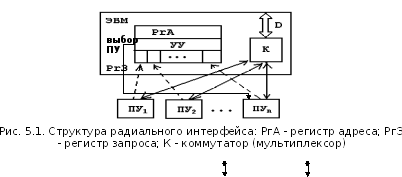 46)
При радиальном
ИФ центральная ЭВМ соединена с ПУ
посредством индивидуальных линий,
монопольно принадлежащих каждому из
них. Управление ИФ полностью сосредоточено
в ЭВМ.
46)
При радиальном
ИФ центральная ЭВМ соединена с ПУ
посредством индивидуальных линий,
монопольно принадлежащих каждому из
них. Управление ИФ полностью сосредоточено
в ЭВМ.
Если обмен информацией с ПУ осуществляется по требованию ЭВМ, то в регистр адреса записывается адрес ПУ. В соответствии с этим адресом УУ переключает коммутатор на соответствующее ПУ, соединяя шину данных ЭВМ с шиной ПУ, и выставляет соответст соответствующий сигнал выбора ПУ. Затем происходит обмен информацией.
Если обмен информацией осуществляется по требованию ПУ, то ПУ передаёт сигнал запроса по своей линии в ЭВМ, который поступает в i-ый разряд регистра запроса. Как только ЭВМ освобождается от предыдущего обмена, его УУ последовательно опрашивает все разряды регистра запроса. Порядок опроса Pr3 определяется приоритетами обслуживания периферийных устройств. Номер установленного бита в Pr3 является адресом ПУ и в соответствие с ним происходит переключение коммутатора. Далее обмен идёт так же, как и в первом случае.
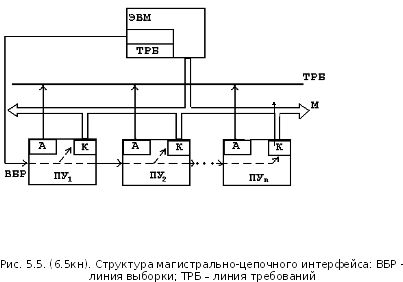
47)
При
магистральном подключении ЭВМ соединено
с ПУ посредством единой магистрали,
используемой ими на основе разделения
времени. Сигнал на любой линии магистрали
физически доступен каждому устройству,
поэтому для организации обмена между
ЭВМ и одним ПУ необходимо остальные ПУ
логически отключить.. Адреса ПУ для
одной магистрали не повторяются и
записываются в регистры ПУ (назначаются)
при подключении их к магистрали.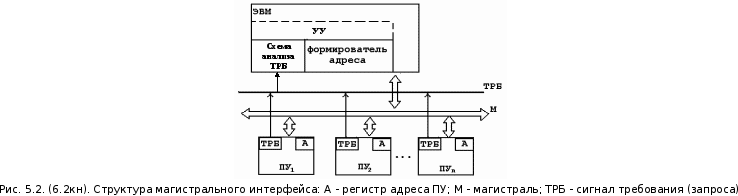
Если обмен информацией с ПУ происходит по требованию ЭВМ, то справедлива следующая последовательность действий:
1) цикл адресации - передача адреса ПУ по магистрали (все ПУ получают посланный адрес и сравнивают его со своим адресом);
2) устройство, у которого произошло совпадение адреса, устанавливает сигнал готовности к приёму информации на линию требований (ТРБ);
3) ЭВМ передаёт данные ПУ или ПУ передаёт запрашиваемую информацию ЭВМ.
Если обмен происходит по инициативе ПУ, то:
1) ПУ выставляет сигнал запроса на линию ТРБ (исключение возможности использования магистрали другими ПУ);
2) схема анализа требований анализирует полученные сигналы ТРБ по приоритету или другому признаку;
3) ЭВМ путем перебора адресов осуществляет цикл опроса ПУ, пока не будет получено подтверждение. Подтверждение запроса может быть передано по информационной шине;
4) получив подтверждение запроса, ЭВМ прекращает цикл опроса, и происходит обмен.
48) При цепочном ИФ подчинённые ПУ подключаются к ЭВМ последовательно, образуя цепочку. Всем ПУ присваиваются неповторяющиеся адреса.
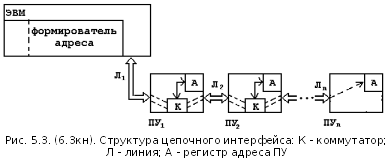
Если обмен информацией происходит по инициативе ЭВМ, то
1) адрес запрашиваемого устройства от ЭВМ по линии Л1 передаётся первому ПУ;
2) переданный адрес в ПУ сравнивается с собственным;
3) если адреса не совпали, то коммутатор соединяет линии Лi c Лi+1 и процедура сравнения повторяется;
4) если адреса совпали, то коммутатор не срабатывает, а устройство считается логически подключённым к ЭВМ;
5) далее происходит обмен информацией.
Если обмен происходит по инициативе ПУ, то
1) ПУ с помощью своего коммутатора отключает всю ветвь ПУ после себя (ветвь ПУ с более низким приоритетом);
2) передача адреса ПУ по линиям в направлении ЭВМ. Если стоящие впереди ПУ заняты обменом, то адрес блокируется;
3) обмен информацией.
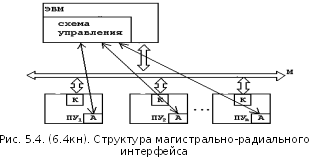
49) Комбинированный интерфейс . Основой любого комб. интерф. является
магистральный интерфейс. По магистр. Линиям передается адресн данные и команды, а некоторые управл. линией организ. либо как радиальн. либо как цепочн.
Все виды информации при магистрально-радиальном ИФ передаются по параллельной магистрали, а некоторые линии могут быть радиальными.
Если обмен информацией происходит по инициативе ЭВМ, то
1) ЭВМ по индивидуальной линии передаёт ПУ сигнал разрешения работы;
2) ПУ при помощи коммутатора подключается к магистрали и осуществляет обмен информацией.
Если обмен происходит по инициативе ПУ, то1) хотя все ПУ отключены от магистрали, но они могут передать по своей линии сигнал запроса;
2) схема управления принимает запросы и осуществляет арбитраж;
3) арбитр по одной из линий выдаёт сигнал разрешения обмена одному ПУ;
4) ПУ при помощи коммутатора подключается к магистрали и осуществляет обмен.
Примером магистрально-радиального интерфейса может служить шина ISA. На этой шине большинство линий являются магистральными, а некоторые линии – радиальные.
 49)
Цепочный. Все
виды информации передаются по общей
шине. Адресация организована также как
и в магистральной ИФ. Для ускорения
идентификации предусмотрена управляющая
шина, соединяющая ПУ по цепочному
принципу. Эта структура ИФ позволяет
строить системы, в которых обмен возможен
как между ЭВМ и ПУ, так и между двумя
любыми ПУ. Запрашивающее устройство
называется ведущим,
а второе устройство - ведомым.
49)
Цепочный. Все
виды информации передаются по общей
шине. Адресация организована также как
и в магистральной ИФ. Для ускорения
идентификации предусмотрена управляющая
шина, соединяющая ПУ по цепочному
принципу. Эта структура ИФ позволяет
строить системы, в которых обмен возможен
как между ЭВМ и ПУ, так и между двумя
любыми ПУ. Запрашивающее устройство
называется ведущим,
а второе устройство - ведомым.
50) В последовательном интерфейсе передача данных осуществляется всего по одной линии, хотя общее число линий может быть и больше. В этом случае по дополнительным линиям передаются сигналы синхронизации и управления. И последовательного типа характеризуется относительно небольшими скоростями передачи и низкой стоимостью сети связи. В параллельном интерфейсе передача сообщений выполняется последовательно квантами, содержащими m бит. Каждый квант передаётся одновременно по m линиям; величина m называется шириной интерфейса и обычно соответствует или кратна байту. Наиболее распространены интерфейсы, в которых m = 8 или m = 16.
51 52) При синхронной передаче передатчик поддерживает постоянные интервалы между очередными квантами информации в процессе передачи всего сообщения или значительной его части. Для реализации синхронного режима передатчик вначале сообщения передаёт заранее обусловленную последовательность бит, называемую символом синхронизации SYN. Переход линии ИФ из состояния “0” в состояние “1” используется приёмником для запуска внутреннего генератора. Приёмник распознаёт передаваемый символ SYN, после чего принимает очередной символ сообщения, начиная с его первого бита (рис. 5.7, а).
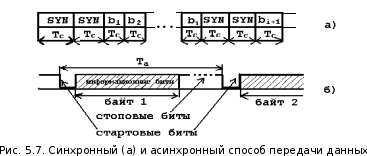
При нарушении синхронизации передатчик должен вставить в последовательность последовательность передаваемых байт сообщения дополнительные символы SYN. Если при последовательной и параллельной передаче используются дополнительные линии ИФ, то они могу использоваться для синхронизации. Часто при параллельной передаче в качестве линии синхронизации используется линия стробирования.
При асинхронной передаче синхронизация приёмника и передатчика осуществляется при передаче каждого кванта информации. Интервал между передачей квантов непостоянен.
При последовательной передаче каждый байт обрамляется стартовыми и стоповыми сигналами (рис. 5.7, б). Стартовый сигнал изменяет состояние линии ИФ и служит для запуска тактового генератора приёмника. Стоповые биты переводят линию в исходное состояние и останавливают работу генератора. Синхронизация поддерживается только в интервале передачи одного кванта.
Эффект перкоса информации сказываются на том, что приемник в нач.интервал времени может сработать ложно. Чтобы это исключить в месте с паралельными данными подается сигнал стробирования по которому данные с паралеллной шины записывают. в регистр.
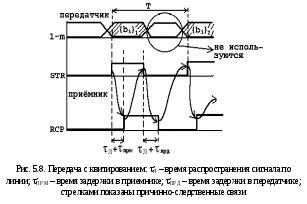
 Асинхронный
режим при параллельной передаче обычно
реализуется по схеме “запрос-ответ”
(рис. 5.8). Приёмник, получив сигнал по
линии стробирования и зафиксировав
квант сообщения по m линиям, формирует
ответный сигнал - квитанцию RCP. Такую
передачу называют передачей
с квитированием.
Сигнал RCP
является разрешением передатчику
перевести линии 1-m данных и линию
стробирования в исходное состояние,
после чего приёмник также сбрасывает
сигнал RCP. Сброс сигнала RCP служит для
передатчика разрешением на передачу
очередного байта. Линии данных используются
для передачи квантов сообщения только
в течение половины интервала передачи
Т.
Асинхронный
режим при параллельной передаче обычно
реализуется по схеме “запрос-ответ”
(рис. 5.8). Приёмник, получив сигнал по
линии стробирования и зафиксировав
квант сообщения по m линиям, формирует
ответный сигнал - квитанцию RCP. Такую
передачу называют передачей
с квитированием.
Сигнал RCP
является разрешением передатчику
перевести линии 1-m данных и линию
стробирования в исходное состояние,
после чего приёмник также сбрасывает
сигнал RCP. Сброс сигнала RCP служит для
передатчика разрешением на передачу
очередного байта. Линии данных используются
для передачи квантов сообщения только
в течение половины интервала передачи
Т.
Для увеличения пропускной способности асинхронного ИФ можно реализовать ускоренный параллельный ИФ за счёт использования пустых промежутков между интервалами передачи информации и организации двух линий квитирования (RCP1 и RCP2) и двух линий стробирования (STR1 и STR2) (рис. 5.9).

53) Системными ресурсами называются те ресурсы ЭВМ, которые используются узлами компьютера для обмена данными с помощью шин, такие как коммуникационные каналы, адреса и сигналы. Системные ресурсы обычно являются разделяемыми, т.е. используются совместно несколькими узлами. Обычно под системными ресурсами подразумевают:
• адреса памяти;
• каналы запросов прерываний (IRQ);
• каналы прямого доступа к памяти (ПДП – DMA);
• адреса портов ввода-вывода.
При подключении нового адаптера ПУ ему должны быть назначены (распределены) требуемые системные ресурсы. Возможны два способа конфигурирования адаптеров: автоматический и посредством переключения джамперов (съемных перемычек на контактах печатной платы). При последнем способе устанавливаемые параметры должны быть занесены в конфигурационные файлы (как при подключении дополнительных винчестеров). При автоматическом способе проблемы распределения ресурсов на шинах решаются на этапе инсталляции оборудования за счет применения технологии Plug and Play (PnP) – стандарта автоматической настройки конфигурации подключаемых устройств.
54) Логическая память может быть организована 2 различными видами:
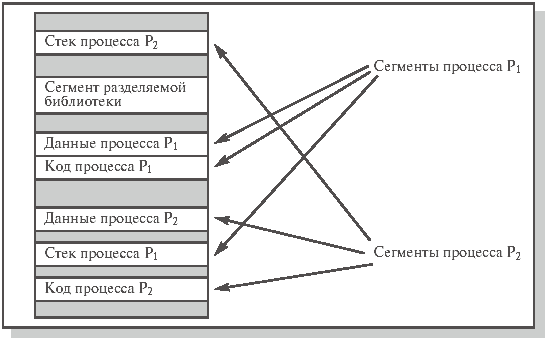
Непрерывная единая память
Сегментная организация памяти.
1) При непрерывной организации физической памяти, к любому ее месту можно обратится непосредственно минуя дополнительные операции.
При линейной организации физической памяти, она разбивается ОС на ряд разделов, при этом размеченных разделах хранятся данные для различных программ.
Сегмент – область памяти определенного назначения, внутри которой поддерживается линейная адресация. Сегменты содержат процедуры, массивы, стек или скалярные величины, но обычно не содержат информацию смешанного типа.
Адрес состоит из двух компонентов: номер сегмента, смещение внутри сегмента. Далее оказалось удобным размещать в разных сегментах различные компоненты процесса (код программы, данные, стек и т. д.). Попутно выяснилось, что можно контролировать характер работы с конкретным сегментом, приписав ему атрибуты, например права доступа или типы операций, которые разрешается производить с данными, хранящимися в сегменте.
55) Пространство ввода вывода представляет собой набор Pr которые физич. Находятся в контроллерах.Это регистры которые называются портами. Адрес портов вв\в для устройств которые есть в списке BIOS (LPT, PS\2) Всегда жестко фиксированы. Адреса остальн. Устройств назначаются произвольно при включении питания. Утилита Post опред. Наличием контролера и если он есть то, то назнач. ему адрес порта и записывает этот адрес в таблицу базовых адресов. Адрес портов не представляет не прерывного пространства. Адреса портов 0-FFh отведены для подсистемных устройства. Остальные порты назнач. по принципу max числа 2-ичн единиц. При обращении к портам использ. Инструкции Ir – из порта в ЦП, OUT – из ЦП в порт.
60) Прерывание — временный останов выполнения одной программы в целях оперативного выполнения другой, в данный момент более важной (приоритетной) программы. Прерывания возникают при работе компьютера постоянно. Достаточно сказать, что все процедуры ввода-вывода информации выполняются по прерываниям. Контроллер прерываний обслуживает процедуры прерывания, принимает запрос на прерывание от внешних устройств, определяет уровень приоритета этого запроса и выдает сигнал прерывания в МП. МП, получив этот сигнал, приостанавливает выполнение текущей программы и переходит к выполнению специальной программы обслуживания того прерывания, которое запросило внешнее устройство. После завершения программы обслуживания восстанавливается выполнение прерванной программы. Контроллер прерываний является программируемым. Прерывания бывают: - аппаратные инициируются при обращениях к МП со стороны внешних устройств (таймера, клавиатуры, дисководов, принтера и т. д.). - программные (вызываются операционной системой) Программные прерывания бывают в BIOS и ОС. Программы обработки прерываний OS, в отличие от программ обработки прерываний BIOS, не встроены в ПЗУ и для разных операционных систем могут быть разными.
Все аппаратные прерывания делятся на маскируемые и немаскируемые. Всего для процессоров х86 таблица прерываний содержит до 256 процедур обслуживания прерываний.
Немаскируемые прерывания обслуживаются процессором независимо от состояния флага разрешения прерывания IF. К таким прерываниям относятся прерывания, приходящие по линии NMI (и по линии SMI для процессоров, поддерживающих режим системного управления). Сигнал на эту линию проходит от схем контроля паритета памяти и от линии контроля канала (для шины ISA - IOCHK). По битам 6,7 регистра 061h распознается источник прерывания. Запретить немаскируемое прерывание NMI, можно обнулив бит 7 порта 0A0h. Отдельные источники блокируются битами 4, 5 регистра 061h, а при помощи битов 6, 7 регистра 062h устанавливается источник, от которого блокируется немаскируемое прерывание.
Обработка маскируемых прерываний может запрещаться и разрешаться путем установления или сброса флага процессора IF инструкциями DI (запрещение) и EI (разрешение). Эти прерывания обслуживаются специальным контроллером, который имеет 8 входов запросов прерываний IRQx от внешних источников. При обработке запроса контроллер подает по шине данных 8-битный вектор прерывания, соответствующий номеру запроса. Этот вектор является индексом, по которому в таблице прерываний храниться ссылка на процедуру обработки.
Прерывание на шине ISA
В проекте два источника прерывания, один от стековой памяти HFx (half flag), другой от кнопки BUTTONx.
Обработка прерываний в любом случае заключается в чтении стековой памяти до конца, проверке нажатия кнопки и чтении счетчика внешних событий. Нажатие кнопки должно вызывать сброс счетчика событий.
Оба прерывания не должны «шунтировать» друг друга, т.е. если продолжительно нажать на кнопку не должен пропасть запрос на прерывание от стека.