

57) Прерывания шины pci
Шина PCI поддерживает аппаратные прерывания, которые использует установленное устройство, чтобы привлечь внимание шины. Это прерывания INTA#, INTB#, INTC# и INTD#. Прерывания INTx# чувствительны к уровню, что позволяет распределять их среди нескольких устройств PCI. Если одиночное устройство PCI использует только одно прерывание, то им должно быть INTA# — одно из основных правил спецификации шины PCI. Остальные дополнительные устройства должны использовать прерывания INTB#, INTC# и INTD#.
Для нормального функционирования шины PCI в персональном компьютере ее прерывания должны быть установлены в соответствии с существующими прерываниями ISA. Прерывания ISA не могут использоваться совместно, поэтому в большинстве случаев для каждой платы PCI, использующей прерывание INTA# шины PCI, следует установить прерывания, отличные от неразделяемых прерываний шины ISA. Рассмотрим в качестве примера систему, имеющую четыре разъема PCI и четыре установленные платы PCI, каждая из которых использует прерывание INTA#. В таком случае каждой из плат должен быть назначен отдельный запрос прерывания ISA, например IRQ9, IRQ 10, IRQ 11 или IRQ5.
Установка одинаковых прерываний для шин ISA и PCI обязательно приведет к конфликту. Также будут конфликтовать два устройства ISA с одинаковым прерыванием. Что же делать, если доступных прерываний недостаточно для всех установленных в системе устройств? В большинстве новых систем допускается использование одного прерывания несколькими устройствами PCI. Все системные BIOS, удовлетворяющие спецификации
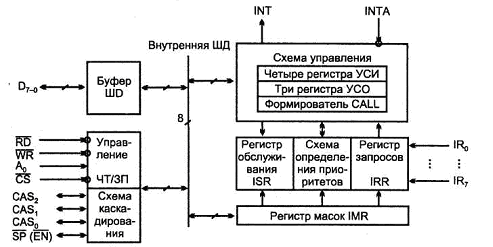
Рис. Структура программируемого контроллера прерываний
Биты регистра масок действуют также на работу схемы определения приоритетов и регистр обслуживания ISR, так что маскирование может быть осуществлено не только на стадии приема запросов, но и на более поздних стадиях их обработки.
Если приоритет запроса выше текущего приоритета, то при вложенных прерываниях формируется сигнал INT для процессора. При поступлении от процессора сигнала подтверждения прерывания INTA принятый запрос переходит в регистр обслуживания ISR (Interrupt Servicing Register) и сбрасывается в регистре запросов IRR. Установка бита ISR запрещает прерывания от всех других запросов с меньшими приоритетами. Подпрограмма обслуживания прерывания завершается сбросом бита регистра ISR.
Можно также обслуживать прерывания по результатам опроса источников запросов, когда сигнал INT не используется, и процессор сам производит поочередный опрос входов, начиная со старшего по приоритету. Обнаружение запроса ведет к его обслуживанию с переходом на соответствующую подпрограмму.
Буфер ШД восьмиразрядный, двунаправленный, с третьим состоянием. При программировании контроллера через него передаются управляющие слова, и считывается состояние регистров, а также код запроса, выработавшего сигнал INT. При обслуживании прерывания по сигналу INTA через буфер ШД в шину данных системы выдается трехбайтная команда вызова подпрограммы CALL.
Смысл
сигналов
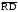 ,
,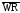 и
и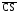 ,
ясен (совпадает со смыслом этих сигналов
в описанных выше устройствах). Сигнал
,
ясен (совпадает со смыслом этих сигналов
в описанных выше устройствах). Сигнал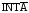 поступает от процессора в виде трех
последовательных импульсов, для выдачи
контроллером кода командыCALL,
младшего байта адреса начала подпрограммы
и старшего байта этого адреса. Первый
импульс
поступает от процессора в виде трех
последовательных импульсов, для выдачи
контроллером кода командыCALL,
младшего байта адреса начала подпрограммы
и старшего байта этого адреса. Первый
импульс
 сбрасывает запрос в соответствующем
битеIRR.
сбрасывает запрос в соответствующем
битеIRR.
Сигналы
IR0...IR7
- входы запросов прерывания (Interrupt
Requests),
A0-
младший разряд адреса, показывает, к
какому регистру управляющих слов (УСИ
или УСО) обращается процессор. Сигналы
CAS2-0
связаны с работой контроллера в групповой
схеме, образуют выходную шину для
ведущего контроллера и входную для
ведомых. Сигнал
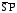 (
( )
двухфункциональный, как
)
двухфункциональный, как он определяет, является ли контроллер
ведущим или ведомым в групповой схеме,
как
он определяет, является ли контроллер
ведущим или ведомым в групповой схеме,
как используется в так называемом
буферизованном режиме для разрешения
выхода на шину системы, т.е. для управления
выходными буферами участников обмена.
используется в так называемом
буферизованном режиме для разрешения
выхода на шину системы, т.е. для управления
выходными буферами участников обмена.
58)
APIC-
улучшенный программируемый контроллер
прерываний. Он был добавлен в
процессореPentium.
– шина соединяет «фронтальный» контроллер
I/O APIC с локальными контроллерами APIC.
Линии IRQ, идущие от устройств, соединены
с контроллером I/O APIC, который, таким
образом, выступает в качестве маршрутизатора
по отношению к локальным контроллерам.
На материнских платах Pentium III и более
ранних процессоров шина APIC была
последовательной трехлинейной шиной,
а начиная с модели Pentium 4, шина APIC
реализована на базе системной шины.

Контроллер I/O APIC включает в себя 24 линии IRQ, таблицу переадресации прерываний на 24 записи, программируемые регистры и блок для отправки и приема APIC-сообщений через APIC. В отличие от IRQ-выводов чипа 8259А, приоритет прерывания не связан с номером линии. статическое распределение – сигнал IRQ доставляется локальным контроллерам APIC, указанным в соответствующей записи таблицы переадресации. Прерывание направляется одному конкретному процессору, подмножеству процессоров или всем процессорам сразу (широковещательный режим); динамическое распределение – сигнал IRQ доставляется локальному APIC-контроллеру процессора, выполняющему процесс с наименьшим приоритетом.
Преимущества расширенного контроллера прерываний:
возможность реализации межпроцессорных прерываний — сигналов от одного процессора другому
поддержка до 256 входов IRQ, в отличие от 16 на классической IBM PC
крайне быстрый доступ к регистрам текущего приоритета прерывания и подтверждения прерывания. Контроллер прерываний, совместимый с IBM PC, исполнялся как устройство шины ISA с очень медленным доступом к его регистрам (порт 0x20)
59) Прежде всего, организация обмена данными осуществляется между периферийными устройствами и памятью. Возможны три способа обмена данными по общим магистралям:
1. Это программный обмен информации.
2. Это обмен по прерыванию
3. Обмен в режиме прямого доступа к памяти
Программный обмен информации
В этом режиме процессор является единоличным хозяином системной магистрали. Все циклы обмена информации инициируются процессором и выполняются в строго определённом порядке. Обмен информации производится в соответствии с командами заданными программой, не на какие внешние события процессор не реагирует.
Обмен по прерыванию.
Прерывание микропроцессорной системы бывает двух основных типов: векторное прерывание (при этом требуется проведение цикла чтения по магистралям) и радиальное прерывание (его тип непосредственно передаётся через сигнал по прерыванию). При векторном прерывании код номера прерывания передаётся процессору тем устройством, которое запросило его. Для этого процессор проводит цикл чтения по магистрали и по шине данных и получает код номера прерывания. Шина адресов не используется. На каждый номер прерывания предусмотрена специальная программа обработки. Когда поступает какое-либо прерывание, процессор прекращает выполнение текущей программы, сохраняет содержимое основных регистров в специальной СТЭК-памяти (?stack?) и загружает начальный адрес программы обработки соответствующего прерывания. При завершении программы обработки прерывания процессор возвращает из СТЭК-памяти(?stack?) сохранённые значения регистра, и прерванная программа продолжается.
Обмен в режиме прямого доступа к памяти(ПДП).
Прямой доступ к памяти освобождает процессор от управления операциями ввода - вывода, позволяя осуществлять параллельно во времени выполнение процессором программы с обменом данными между периферийными устройствами(ПУ) и оперативной памятью(ОП), и производить этот обмен со скоростью, ограниченной только пропускной способностью ПУ и ОП. Таким образом увеличивается производительность ЭВМ. Прямым доступом к памяти управляет контроллер ПДП, который выполняет следующие функции:
Управление инициируемой процессором или ПУ передачей данных между ПУ и ОП.
Задание размеров блока данных, который подлежит передаче, и области памяти, используемой при передачи.
Формирование адресов ячеек ОП, участвующих при передаче.
Подсчет числа едениц переданных данных и определение момента завершения операции ввода-вывода.
60) Прямой доступ к памяти (DMA) - это метод непосредственного обращения к памяти, минуя процессор. Процессор отвечает только за программирование DMA: настройку на определенный тип передачи, задание начального адреса и размера массива обмениваемых данных. Обычно DMA используется для обмена массивами данных между системной памятью и устройствами ввода-вывода.
Общий алгоритм ПДП. Для осуществления прямого доступа к памяти контроллер должен выполнить ряд последовательных операций:
принять запрос (DREQ) от устройства ввода-вывода;
сформировать запрос (HRQ) в процессор на захват шины;
принять сигнал (HLDA), подтверждающий захват шины;
сформировать сигнал (DACK), сообщающий устройству о начале обмена данными;
выдать адрес ячейки памяти, предназначенной для обмена;
выработать сигналы (MEMR, IOW или MEMW, IOR), обеспечивающие управление обменом;
по окончании цикла DMA либо повторить цикл DMA, изменив адрес, либо прекратить цикл.
Каскадный режим (Cascade Mode)
Этот режим использует объединение нескольких контроллеров DMA для расширения числа подключаемых каналов. Выходы HRQ и входы HLDA от дополнительных контроллеров соединяются соответственно со входами DREQ и выходами DACK первичного контроллера DMA . Это дает возможность запросам от дополнительного устройства распространяться через сеть приоритетных цепей предшествующего устройства.
Таким образом, канал первичного контроллера DMA, к которому подключен дополнительный контроллер, программируется на выполнение каскадного режима и служит только для определения приоритета дополнительного устройства и транзита сигналов HRQ в CPU и HLDA из CPU. Все другие сигналы каскадного канала первичного контроллера DMA в формировании циклов подсистемы DMA не участвуют.
Программирование контроллера.Контроллер DMA может программироваться процессором, когда HLDA не активен; это утверждение истинно, даже если активен HRQ. Ответственность процессора заключается в гарантии, что программирование контроллера и активный HLDA взаимоисключающие. Если -CS и HLDA в низком состоянии, контроллер DMA входит в режим программирования. Выбор регистров при программировании осуществляется с помощью адресной шины A0-A3, работающей на вход, а выбор режима записи или считывания - с помощью сигналов -IOW или -IOR. При записи/считывании 16- разрядных регистров адреса или счетчика соответствующего канала необходим дополнительный разряд адреса, в качестве которого используется внутренний триггер FF. По FF=0 происходит обращение к младшему байту, а по FF=1 - к старшему байту регистра адреса или счетчика. Кроме того, для контроллера существуют дополнительные специальные команды, которые могут быть выполнены в режиме программирования и не зависят от набора разрядов на шине данных. К ним относятся следующие команды:
сброс триггера FF (Clear First/Last Flip-Flop; 00C, 0D8). Эта команда выполняется перед записью или чтением информации из регистров адреса или счетчика слов контроллера DMA. Триггер FF устанавливается таким образом, чтобы микропроцессор адресовал старший и младший байты в нужной последовательности;
очистка (Master Clear; 00D, 0DA). По этой программной команде в контроллере DMA выполняются такие же действия, как и по аппаратному RESET. Очищаются регистры команд, состояния, запросов и триггер FF, а регистр маски устанавливается. После этого контроллер DMA переходит в холостой цикл;
cброс регистра маски (Clear Mask Register; 00E, 0DC). По этой команде очищаются разряды масок для всех 4 каналов, что разрешает им принимать запросы DMA. После включения питания предполагается, что все внутренние ячейки, особенно регистр MOD, будут загружены некоторым действительным значением. Это необходимо сделать, даже если некоторые каналы не используются.