

6.4. Поиск
Одно из наиболее часто встречающихся в программировании действий - это поиск. Он же представляет собой идеальную задачу, на которой можно испытывать различные структуры данных по мере их появления. При дальнейшем рассмотрении мы будем исходить из того допущения, что группа данных, в которых надо отыскать элемент, фиксирована и задача заключается в том, что надо найти элемент, который имеет определенный ключ. Так как нас интересует сам процесс поиска, а не обнаруженные данные, то будем считать, что мы ищем не ключ элемента, а сам элемент, из множества элементов, представляющих собой положительные числа.
Линейный поиск
Если нет никакой дополнительной информации о разыскиваемых данных, то очевидный подход - простой последовательный просмотр массива с увеличением шаг за шагом той его части, где желаемого элемента не обнаружено. Такой метод называется линейным поиском.
Алгоритм поиска можно представить таким образом:
1. Сравнить первый элемент с требуемым.
2. Если элементы совпадают, то поиск закончен, элемент найден.
3. Если элементы не совпадают, то сравнивается следующий элемент, при этом вновь начинается процесс (2).
4. Этот процесс продолжается до тех пор, пока не будет достигнут конец массива или пока не будет найден требуемый элемент.
Этот алгоритм целесообразно применять для любой неупорядоченой последовательности чисел, или неотсортированного массива.
Поиск делением пополам
Совершенно очевидно, что если массив не отсортирован и нет никакой дополнительной информации, то никаких способов убыстрения его работы как с использованием алгоритма линейного поиска не существует. Но если известно, что массив отсортирован, поиск можно сделать более эффективным. Допустим данные отсортированы по возрастанию.
Основная идея состоит в том, что выбранный случайным образом элемент массива, при сравнении с требуемым, если он не равен ему, даст две ветви поиска
- при условии, что выбранный элемент массива больше искомого, из рассмотрения исключаются все элементы большие, чем выбранный;
- при условии, что выбранный элемент массива меньше искомого, из рассмотрения исключаются все элементы меньшие, чем выбранный;
Чтобы сбалансировать поиск, целесообразно каждый раз делить массив на две части, т.е. каждый раз выбирать элемент посередине. В этом случае вероятность нахождения элемента в каждой половине массива одинакова. Такой способ поиска получил название поиск делением пополам.
Поиск в таблице
Иногда поиск в массиве называют поиском в таблице, если это массив символов. Часто массив символов представляет собой строки или слова.
Для того чтобы установить факт совпадения мы должны очевидно убедиться, что все символы сравниваемых строк соответственно равны один другому. Поэтому сравнение сводится к поиску их не совпадающих частей, т.е. поиску на неравенство. Если не равный частей не существует можно говорить о равенстве
Рассмотрим это на примере. Пусть какой-то текст хранится в виде последовательности литер; задача состоит в том, чтобы отыскать в нем первое появление определенного "слова", которое можно определить как последовательность литер не длиннее самого текста. Алгоритмы, основанные на этой модели, имеют важное значение во многих областях информатики, что особенно заметно в программах символьной обработки.
При построении данного алгоритма надо точно сформулировать, что считать требуемым результатом.
1. Результатом будет совпадение букв между искомым словом и текстом. Если слово имеет индекс i от 1 до n, то начиная с некоторого j (где j индекс текста) до j=j+n наблюдается совпадение с символами i= 1...n.
2. Для всех значений символов, которые меньше символа j (символа с которого начинается совпадение) в тексте не будет наблюдаться совпадение с искомым словом.
3. Нельзя не учитывать еще одну возможность: в заданном тексте нужного слова может вообще не оказаться. Подобного типа недосмотр часто является причиной неверной работы программы. Это упущение можно исправить, если договориться, что в случае неудачного поиска слова выходное значение j следует сделать большим максимального значения, допустимого для начала сравниваемых цепочек.
Перечисленные три условия являются схемой для установления самого алгоритма Один очевидный метод - итерационный. Первое и третье условия устанавливаются в цикле while в качестве пароля, второе условие выступает как инвариант цикла. Начальное значение j задается равным О, т. е. поиск начинается с начала текста. При каждом прохождении цикла осуществляется проверка контрольных условий; если слово совпадает с текстом или j превышает размер букв в стоке т, то программа выходит из цикла, в противном случае j увеличивается на 1 и цикл повторяется.
Остается определить, как устанавливается само совпадение, т. е. как сравниваются литеры слова с литерами текста во всем диапазоне значений индекса i от 1 до n. Это обеспечивается циклом, вложенным в основной цикл для каждого значения j внутренний цикл охватывает весь диапазон значений i и п литер сравниваются по одной. При первом несовпалении литер внутренний цикл принудительно прерывается. Значение i на выходе из цикла показывает, было обнаружено совпадение или нет; если i меньше n, сравнение закончилось из-за несовпадения.
Алгоритм, вкратце описанный выше приводит к искомой цели, но он не очень эффективен. По-существу, слово и текст совмещают, начиная с левых границ, и сравнивают их литера за литерой. Если обнаруживают не совпадение слово сдвигается на одну литеру вправо и сравнение повторяется. Процесс повторяется пока не будет достигнуто совпадение или конец текста. И том случае если не совпадает ни одно слово, или слово находится в конце текста происходит значительное число сравнений.
Трудно было поверить, что спустя целых 30 лет после того, как начались исследования в области кибернетики, можно существенно улучшить метод решения такой фундаментальной задачи, какой является поиск в тексте. Тем не менее в 1976 г. Р. Бойер и Дж. Мур, нашли более быстрый способ. Их идея позволяет увенчивать j более чем на 1 при каждом шаге в основном цикле программы. Сравнение слова с частью текста начинается от конца слова (помещаемого в начале текста) и продолжается по направлению к его началу. Если проверяемая литера в слове не совпадает с соответствующей литерой текста, то слово двигается вправо относительно этой позиции, которую назовем опорной, до тех пор, пока какая-нибудь литера снова не совпадет с литерой текста в этой позиции. Если этого не произойдет, то слово сдвигается таким образом, чтобы его первая литера отстояла от опорной позиции на один интервал.
Сразу же возникает вопрос, как находят следующую совпавшую литеру, - ведь если для этого нужно сравнивать литеры по одной, то никакого выигрыша нет. Существует другой способ: завести таблицу расстояний от конца слова до последнего появления каждой буквы в этом слове. Конечно нужно потратить определенное время на расчет такой таблицы, но сделать это необходимо только один раз: если текст достаточно длинный, дело того стоит.
Ниже приводятся рисунки для пояснения вышеуказанных алгоритмов.

Рис. 6.4. ПОИСК СЛОВА В ТЕКСТЕ осуществляется путем последовательных сравнений букв. Слово и текст являются массивами букв. В данном случае текст содержит 25 букв, а слово — четыре. Первая буква слова сравнивается с первой буквой текста; поскольку они совпадают (подчеркивание), сравниваются вторые буквы. На этот раз буквы отличаются (обычный кружок); следовательно, слово сдвигается на одну позицию вправо и проверка производится заново с начала слова. Слово считается найденным, когда все буквы совпадают. Условия, которым должен удовлетворять этот алгоритм, сформулированы в трех предложениях на языке исчисления предикатов, приведенных в нижней части рисунка. Первое высказывание (Р) гласит, что если слово выставлено в позицию j массива-текста, то для всех значений индекса массива-слова i элемент слово [i] одинаково элементом текст [j+i]. Высказывание (Q) утверждает, что для всех меньших значений j не существует ни одного совпадения цепочек; это значит, что ищется первое появление в тексте данного слова. Третье предложение, которое должно выполниться в конце поиска, гласит, что (1) выполнятся и Р, и Q (2) либо i будет иметь значение n (показывающее, что совпадение обнаружено е позиции j), либо j окажется больше того значения которое возможно для совпадения (признак того, что слово в данном тексте отсутствует).
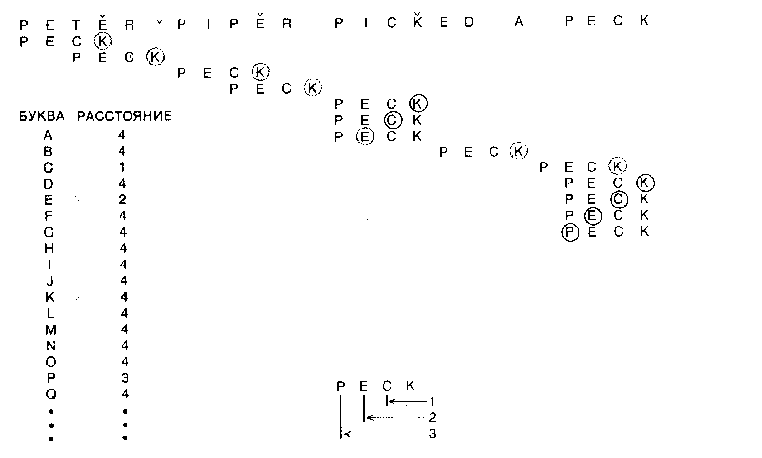
Рис. 6.5. АЛГОРИТМ БЫСТРОГО ПОИСКА был придуман в 1976 г. Р. Бойером и Дж, Муром, работающими в Техасском университете в Остине. Поиск ведется с начала текста, но с конца слова. Программа должна содержать таблицу расстояний от конца слова до каждой буквы (из одинаковых букв выбирается ближайшая к концу слова); если буква в слово не входит, в соответствующей позиции таблицы указывается длина всего слова. Когда очередная буква слова не совпадает с буквой текста, для последней из таблицы определяется .соответствующее расстояние; после этого слово сдвигается вправо на нужное число позиций. При первом сравнении буква к в слове не совпадает с буквой е в тексте, поэтому слово сдвигается на две позиции.