

8. Системы автоматизированного исследования, проектирования и управления
8.1. Информационно-поисковые системы
Рост сложности народнохозяйственных объектов, повышение требований к качеству управления ими, непрерывное возрастание объемов информации требуют применения специальных методов накопления информационных массивов, их хранения и поиска в них. Поиски рациональных и эффективных путей решения этих задач привели к созданию специального класса систем, получивших название информационно-поисковые системы (ИПС). В наиболее общем случае ИПС включает следующие компоненты: информационно-поисковый язык (ИПЯ); правила перевода с естественного языка на ИПЯ и обратно; критерий соответствия, используемый в процессе информационного поиска; информационные массивы; технические средства.
Увеличение объемов информации, которая должна храниться в ИПС, возрастание требований к оперативности ее обработки стимулируют широкое распространение автоматизированных ИПС, построенных на базе ЭВМ. Предпосылкой для этого служит непрерывное снижение стоимости выполнения одной операции, стоимости хранения единицы информации, а также рост быстродействия машин и объемов хранимой информации.
Одно ec главных направлений в развитии ИПС представляют банки данных. Под банком данных понимается специализированная ИПС, составными частями которой являются база данных и система управления ею.
База данных—это набор файлов, работа с которыми обеспечивается специальным пакетом прикладных программ — системой управления базой данных (СУБД) с целью создания массивов данных, их добавления и получения справок.
Отметим особенности, отличающие базу данных от обычного набора файлов:
наличие средств идентификации отдельных файлов, групп записей и самих записей. Идентификация (определение данных) выполняется при создании БД, а не во время доступа пользователя к данным;
минимальная избыточность данных, обеспечивающая оптимальное время доступа и низкую стоимость хранения данных.
В связи с тенденциями интеграции данных, оптимизации их структуры и строгой регламентации допуска основными функциями, реализуемыми СУБД, являются создание и поддержание базы данных. Реализация собственно справочной функции в большей степени (по сравнению с ИПС младших поколений) возлагается на пользователя и осуществляется им в прикладных программах путем применения предусмотренных в СУБД языковых средств.
Интеграция информационных массивов, применяемых для решения различных задач, требует специальной подготовки персонала. Существует три категории специалистов, использующих банк данных в качестве источника необходимой информации или осуществляющих функции его сопровождения: пользователи (прикладные программисты); администратор базы данных (одно лицо либо группа лиц, отвечающих за нормальное функционирование СУБД и сохранность БД, а также за оптимальную его организацию на физическом уровне);
системные программисты, в функции которых входит реализация нужного варианта физической организации.
Каждая из трех категорий персонала обладает своими средствами описания базы данных. При этом средства описания БД для системного программиста должны отличаться от средств описания, используемых прикладными программистами и администратором, поскольку в своей деятельности они ограничиваются описанием логической структуры БД. Логические описания администратора и системного программиста не тождественны: первый использует глобальное логическое описание данных, а второй - лишь некоторое подмножество глобального описания - подсхему. Общим правилом становится разграничение доступа и введение различных режимов доступа (только чтение, только запись, чтение и запись), реализуемые специальным механизмом доступа СУБД. Последовательное проведение этого принципа требует, чтобы пользователю не был известен сам факт существования (хранения в БД) данных, к которым не санкционирован доступ этого пользователя.
Однако полная осведомленность администратора о структуре БД не соответствует степени доступности администратора к данным: обычно администратор имеет доступ лишь к минимальному объему данных, (например, к некоторым тестовым массивам), обеспечивающему выполнение им своих функций. Таким образом, каждая из этих трех групп специалистов имеет собственное представление о структуре БД, а также собственные средства ее описания (рис.8.1)
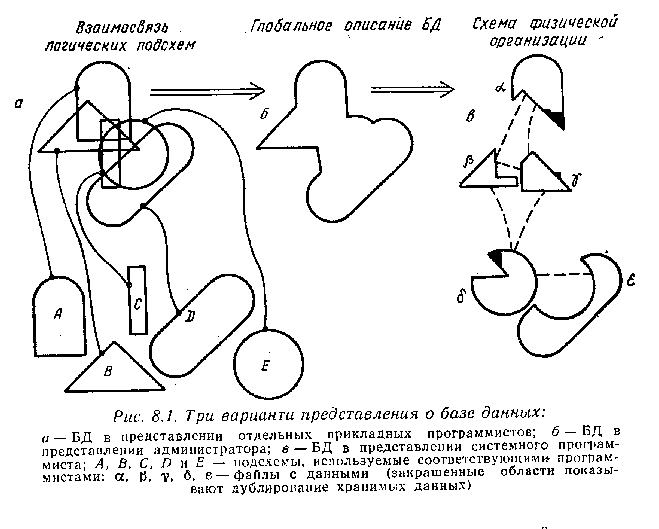
Данные, которые хранятся в ИПС могут быть организованы различным образом, в зависимости от того, какие существуют связи между элементами. Характер связи между ними определяет три основных типа организации данных: иерархический, сетевой и реляционный.
Иерархическая система называется так потому, что в ней существует упорядоченность элементов в записи. В каждой группе записей один элемент считается главным, а другие элементы носят подчиненный характер по отношению к главному. Группы записей упорядочиваются в определенную последовательность, как ступеньки лестницы, и поиск данных может осуществляться прохождением уровней в соответствии с порядком, определяемым последовательностью главных элементов.
Базы данных, построенных по иерархическому принципу, начали использоваться с самого начала периода широкого внедрения вычислительной техники в 40-е годы, и примеров работы с такими базами данных можно привести немало.
В качестве примера рассмотрим базу данных, организованную в магазине. Первый уровень в организации такой структуры может включать таблицу, содержащую номера пролетов, где лежат продукты и основные категории продуктов, хранящихся в каждом пролете. Категория продукта выступает в качестве главного элемента. Только осуществив поиск таблицы с номерами пролетов и категориями находящихся в них продуктов с последующим отбором нужной категории, такой, как овощи, можно получить доступ к таблицам следующего уровня.
Второй уровень иерархии может включать таблицы, содержащие перечень наименований самих продуктов, хранящихся в том или ином пролете, В таблицах следующих уровней может содержаться информация о ценах на каждый продукт, о поставщике и о сроке хранения. Только последовательно пройдя несколько иерархических уровней, можно отыскать нужную информацию, такую, например, как стоимость продукта. До тех пор пока в файле не будут организованы дополнительные указатели, обработка запросов, которые минуют иерархическую последовательность, как, скажем, непосредственные запросы о стоимости продукта, будет обходиться очень дорого с точки зрения машинных ресурсов.
Сетевая модель отличается несколько большей гибкостью по сравнению с иерархической, поскольку в этом случае между файлами можно установить множественные связи. Такие связи позволяют пользователю получить доступ к нужному файлу без обращения ко всем другим файлам более высокого уровня. За счет этого дополнительные связи существенно трансформируют вертикальную структуру базы данных. В базе данных, используемой в магазине, например в магазине связь может быть установлена между списком пролетов и таблицей цен на продукты, и тогда станет возможным отыскать стоимость продукта данного наименования без предварительного поиска промежуточной таблице, содержащей перечень продуктов, хранящихся в данном пролете.
Реляционная модель, предложенная в 1970 году привлекает к себе широкое внимание в настоящее время, поскольку полагают, что основанная на ней структура обладает большей гибкостью, чем любые другие структуры. Эта гибкость достигается за счет отсутствия иерархии элементов. При поиске информации ее элементы могут использоваться в качестве ключей. Под записью здесь понимается уже не совокупность отдельных элементов, один из которых выделен как главный, а строка двумерной таблицы: элементы же образуют колонки таблицы.
В настоящее время ИПС объединяются в глобальные сети, что существенно расширяет диапазон их применения.