

44. Интервальные оценки параметров распределения
Интервальной называют оценку, которая определяется двумя числами – концами интервала. Интервальные оценки позволяют установить точность и надежность оценок.
Пусть
найденная по данным выборки статистическая
характеристика
 служит оценкой неизвестного параметра
служит оценкой неизвестного параметра
 .
Будем считать
.
Будем считать
 постоянным числом (
постоянным числом ( может быть и случайной величиной). Ясно,
что
может быть и случайной величиной). Ясно,
что
 тем точнее определяет параметр
тем точнее определяет параметр
 ,
чем меньше абсолютная величина разности
,
чем меньше абсолютная величина разности
 .
Другими словами, если
.
Другими словами, если
 и
и
 ,
то чем меньше д , тем оценка точнее.
,
то чем меньше д , тем оценка точнее.
Таким образом, положительное число д характеризует точность оценки.
Однако
статистические методы не позволяют
категорически утверждать, что оценка
 удовлетворяет неравенству
удовлетворяет неравенству
 ;
можно лишь говорить о вероятности г, с
которой это неравенство осуществляется.
;
можно лишь говорить о вероятности г, с
которой это неравенство осуществляется.
Надежностью
(доверительной вероятностью) оценки
называют вероятность г, с которой
осуществляется неравенство
 .
.
Обычно надежность оценки задается наперед, причем в качестве г берут число, близкое к единице. Наиболее часто задают надежность, равную 0,95; 0,99 и 0,999.
Пусть
вероятность того, что,
 равна г:
равна г:

Заменив неравенство равносильным ему двойным неравенством получим:

Это
соотношение следует понимать так:
вероятность того, что интервал
 заключает в себе (покрывает) неизвестный
параметр
заключает в себе (покрывает) неизвестный
параметр
 ,
равна г.
,
равна г.
Интервал
 называется доверительным интервалом,
который покрывает неизвестный параметр
с надежностью г.
называется доверительным интервалом,
который покрывает неизвестный параметр
с надежностью г.
45. Доверительные интервалы для параметров нормального распределения
Пусть
количественный признак генеральной
совокупности распределен нормально.
Известно среднее квадратическое
отклонение этого распределения – у.
Требуется оценить математическое
ожидание а по выборочной средней. Найдем
доверительный интервал, покрывающий а
с надежностью г. Выборочную среднюю ne
x
будем рассматривать как случайную
величину ne
X
(ne
x
изменяется от выборки к выборке),
выборочные значения признака
 – как одинаково распределенные
независимые СВ с математическим ожиданием
каждой а и средним квадратическим
отклонением г. Примем без доказательства,
что если величина Х распределена
нормально, то и выборочная средняя тоже
распределена нормально с параметрами
– как одинаково распределенные
независимые СВ с математическим ожиданием
каждой а и средним квадратическим
отклонением г. Примем без доказательства,
что если величина Х распределена
нормально, то и выборочная средняя тоже
распределена нормально с параметрами

Потребуем, чтобы выполнялось равенство

Пользуясь формулой

заменив
Х на ne
X
и у на
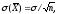 ,
получим
,
получим

где

Найдя
из предыдущего равенства
 получим окончательную формулу:
получим окончательную формулу:

Число
t определяется из равенства
 по таблице функции Лапласа.
по таблице функции Лапласа.
46. Виды зависимостей между случайными величинами
Зависимость одной случайной величины от значений, которые принимает другая случайная величина (физическая характеристика), в статистике называется регрессией. Если этой зависимости придан аналитический вид, то такую форму представления изображают уравнением регрессии.
Процедура поиска предполагаемой зависимости между различными числовыми совокупностями обычно включает следующие этапы:
установление значимости связи между ними;
возможность представления этой зависимости в форме математического выражения (уравнения регрессии).
Первый этап в указанном статистическом анализе касается выявления так называемой корреляции, или корреляционной зависимости. Корреляция рассматривается как признак, указывающий на взаимосвязь ряда числовых последовательностей. Иначе говоря, корреляция характеризует силу взаимосвязи в данных. Если это касается взаимосвязи двух числовых массивов xi и yi, то такую корреляцию называют парной.
При поиске корреляционной зависимости обычно выявляется вероятная связь одной измеренной величины x (для какого-то ограниченного диапазона ее изменения, например от x1 до xn) с другой измеренной величиной y (также изменяющейся в каком-то интервале y1 … yn). В таком случае мы будем иметь дело с двумя числовыми последовательностями, между которыми и надлежит установить наличие статистической (корреляционной) связи. На этом этапе пока не ставится задача определить, является ли одна из этих случайных величин функцией, а другая – аргументом. Отыскание количественной зависимости между ними в форме конкретного аналитического выражения y = f(x) - это задача уже другого анализа, регрессионного.
Таким образом, корреляционный анализ позволяет сделать вывод о силе взаимосвязи между парами данных х и у, а регрессионный анализ используется для прогнозирования одной переменной (у) на основании другой (х). Иными словами, в этом случае пытаются выявить причинно-следственную связь между анализируемыми совокупностями.
Строго говоря, принято различать два вида связи между числовыми совокупностями – это может быть функциональная зависимость или же статистическая (случайная). При наличии функциональной связи каждому значению воздействующего фактора (аргумента) соответствует строго определенная величина другого показателя (функции), т.е. изменение результативного признака всецело обусловлено действием факторного признака.
Аналитически функциональная зависимость представляется в следующем виде: y = f(x).
В случае статистической связи значению одного фактора соответствует какое-то приближенное значение исследуемого параметра, его точная величина является непредсказуемой, непрогнозируемой, поэтому получаемые показатели оказываются случайными величинами. Это значит, что изменение результативного признака у обусловлено влиянием факторного признака х лишь частично, т.к. возможно воздействие и иных факторов, вклад которых обозначен как є: y = ф(x) + є.
По своему характеру корреляционные связи – это соотносительные связи. Примером корреляционной связи показателей коммерческой деятельности является, например, зависимость сумм издержек обращения от объема товарооборота. В этой связи помимо факторного признака х (объема товарооборота) на результативный признак у (сумму издержек обращения) влияют и другие факторы, в том числе и неучтенные, порождающие вклад є.
Для количественной оценки существования связи между изучаемыми совокупностями случайных величин используется специальный статистический показатель – коэффициент корреляции r.
Если предполагается, что эту связь можно описать линейным уравне- нием типа y=a+bx (где a и b - константы), то принято говорить о существовании линейной корреляции.
Коэффициент r - это безразмерная величина, она может меняться от 0 до ±1. Чем ближе значение коэффициента к единице (неважно, с каким знаком), тем с большей уверенностью можно утверждать, что между двумя рассматриваемыми совокупностями переменных существует линейная связь. Иными словами, значение какой-то одной из этих случайных величин (y) существенным образом зависит от того, какое значение принимает другая (x).
Если окажется, что r = 1 (или -1), то имеет место классический случай чисто функциональной зависимости (т.е. реализуется идеальная взаимосвязь).
При анализе двумерной диаграммы рассеяния можно обнаружить различные взаимосвязи. Простейшим вариантом является линейная взаимосвязь, которая выражается в том, что точки размещаются случайным образом вдоль прямой линии. Диаграмма свидетельствует об отсутствии взаимосвязи, если точки расположены случайно, и при перемещении слева направо невозможно обнаружить какой-либо уклон (ни вверх, ни вниз).
Если точки на ней группируются вдоль кривой линии, то диаграмма рассеяния характеризуется нелинейной взаимосвязью. Такие ситуации вполне возможны.