

7.5 Ассоциативная память
В соответствии с /3/, зачастую значительно удобнее искать информацию не по адресу, а по некоторому характерному признаку, содержащемуся в самой информации. Такой принцип лежит в основе ассоциативного ЗУ (АЗУ).
АЗУ – это устройство, способное хранить информацию, сравнивать её с некоторым заданным образцом и указывать на их соответствие или несоответствие друг другу. Признак, по которому производится поиск информации, называется ассоциативным признаком. Кодовая комбинация, используемая в роли образца для поиска, называется признаком поиска. Ассоциативный признак может быть частью искомой информации или дополнительно передаваться ей. В последнем случае его называют тэгом или ярлыком.
Один из вариантов построения ассоциативной памяти показан на рисунке 7.6 /3, 7/.
Как показано на рисунке 7.6, АЗУ включает в себя:
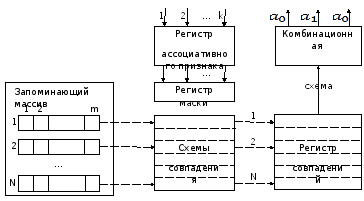
Рисунок 7.6 – Структура АЗУ
1) Запоминающий массив для хранения N m-разрядных слов, в каждом из которых несколько младших разрядов занимает служебная информация.
2) Регистр ассоциативного признака, куда помещается признак поиска; разрядность регистра k обычно меньше длины слова m.
3) Схемы совпадения, которые используются для параллельного сравнения каждого бита хранимых слов с соответствующим битом признака поиска и выработки сигналов совпадения.
4) Регистр совпадений, где каждой ячейке запоминающего массива соответствует один разряд, в который заносится единица, если все разряды соответствующей ячейки совпали с одноимёнными разрядами признака поиска.
5) Регистр маски, позволяющий запретить сравнение определённых битов.
6) Комбинационную схему, которая на основании анализа содержимого регистра совпадений формирует сигналы, определяющие результаты поиска информации.
При
обращении к АЗУ сначала в регистре маски
обнуляются разряды, которые не должны
учитываться при поиске информации. Все
разряды регистра совпадений устанавливаются
в единичное состояние. В регистр признака
заносится код искомой информации; в
процессе поиска схемы совпадения
одновременно сравнивают соответствующие
биты ячеек запоминающего массива с
соответствующим (по разряду) битом
признака. Те схемы, которые зафиксировали
несовпадение, переводят соответствующие
биты регистра совпадений в нулевое
состояние. Тогда единицы сохраняются
лишь в тех разрядах регистра совпадений,
которые соответствуют ячейкам, где
найдена искомая информация. Конфигурация
единиц в регистре совпадений используется
в качестве адресов, по которым производится
считывание из запоминающего массива.
Сигналы результата поиска могут принимать
следующие значения: ![]() – искомая информация не найдена;
– искомая информация не найдена; ![]() - искомая информация находится в одной
ячейке;
- искомая информация находится в одной
ячейке; ![]() - искомая информация содержится в более,
чем одной ячейке.
- искомая информация содержится в более,
чем одной ячейке.
Запись в АЗУ производится без указания конкретного адреса, в первую свободную ячейку. Свободной считается либо пустая ячейка, либо та, которая дольше всего не использовалась.
Главное преимущество АЗУ заключается в том, что время поиска информации зависит только от числа разрядов в признаке поиска и скорости опроса разрядов и не зависит от числа ячеек в запоминающем массиве. Из-за относительно высокой стоимости АЗУ редко используется как самостоятельный вид памяти.
Более подробно с видами поиска информации в АЗУ, методами опроса разрядов, способами выборки при множественных совпадениях можно ознакомиться в работе /3/.
Организация флэш-памяти.
В соответствии с /2, 5, 7, 17/, флэш-память – это особый вид энергонезависимой перезаписываемой полупроводниковой твердотельной памяти.
Впервые флэш-память была разработана компанией Toshiba в 1984 году. В 1988 году компания Intel разработала собственный вариант флэш-памяти. Полное историческое название флэш-памяти Flash Erase Electronically Electrically Programmable ROM – электрически стираемое перепрограммируемое ПЗУ. Считается, что название Flash было дано компанией Toshiba во время разработки первых микросхем флэш-памяти как характеристика скорости стирания информации в микросхеме («in a flash» - мгновенно).
Главной отличительной особенностью флэш является возможность перепрограммирования при подключении к стандартной системной шине микропроцессора. Число циклов репрограммирования флэш-памяти хотя и велико (от 10 000 до 1 000 000 раз), но ограничено. Это связано с тем, что перезапись идёт через стирание, которое приводит к износу микросхемы. Для увеличения долговечности флэш-памяти в её работе применяются специальные алгоритмы для «разравнивания» числа перезаписей по всем блокам микросхемы.
В отличие от жёстких дисков, CD- и DVD-ROM, во флэш-носителях нет движущихся частей, поэтому их и называют твердотельными. По оценкам производителей, информация на флэш может храниться от 20 до 100 лет. Благодаря компактным размерам, высокой степени надёжности и низкому энергопотребелению, флэш-память активно используется в современных вычислительных машинах в качестве съёмного носителя информации.
Одним из элементов структуры флэш-памяти является накопитель (матрица запоминающих элементов). По организации массива запоминающих элементов различают микросхемы флэш-памяти следующих типов /2, 5, 7, 17/:
1) Bulk Erase – стирание допустимо только для всего массива запоминающих элементов.
2) Boot Block – массив запоминающих элементов разделён на несколько блоков разного размера, содержимое которых может осуществляться независимо. Среди блоков есть так называемый загрузочный блок, содержимое которого аппаратно защищено от случайного стирания. В нём хранится программное обеспечение для правильной эксплуатации и инициализации микросхемы.
3) Flash File – массив запоминающих элементов разделён на несколько равноправных блоков одинакового размера, содержимое которых может стираться независимо. Файловая флэш-память ориентирована на замену жёстких дисков, поэтому её блоки являются аналогами секторов магнитных дисков.
Базовым элементом матрица является флэш-ячейка, которая состоит из транзистора особой архитектуры – полевого двухзатворного транзистора. Ячейки флэш-памяти можно соединить последовательно (в цепочку) или параллельно. В первом случае логическая организация памяти называется NAND (Not AND, НЕ-И), во втором – NOR (Not OR, НЕ-ИЛИ).
Процесс записи информации для ячеек NOR и NAND различный. В ячейках NOR запись осуществляется методом инжекции (когда электронам даётся дополнительная энергия для преодоления потенциального барьера пред изолированным затвором). В ячейках NAND запись производится путём туннелирования электронов (когда электроны переходят сквозь барьер). Стирание информации в ячейках обоих типов осуществляется механизмом туннельного перехода.
В чистом виде флэш-память NOR похожа на обычную оперативную память, а память NAND больше напоминает дисковый накопитель с блочным доступом. При существенно большей скорости чтения данных память NOR имеет значительно меньшую скорость стирания и несколько меньшую скорость записи по сравнению с памятью NAND. Однако память NOR позволяет исполнять записанный код, а программы из NAND перед исполнением всегда необходимо предварительно загружать в оперативную память. Ячейка NAND имеет значительно меньшие размеры в сравнении с ячейкой NOR. Хотя первоначально была более распространена память NOR в виде оперативной памяти для вы числительных машин и других программируемых устройств, то сегодня широкое применение получила память NAND в виде карт памяти и твердотельных носителей. Однако, для работы, требующей побайтового произвольного доступа (например, для хранения программного кода), память NOR предпочтительней. Следует отметить, что существуют гибридные решения, в одном корпусе объединяющие разные типы памяти.
Одна ячейка флэш-памяти содержит один транзистор, который в простейшем случае хранит один бит информации. Такие ячейки называются одноуровневыми (SLC – Single Level Cell). Создание многоуровневой ячейки или ячейки с многоуровневым кодированием (MLC – Multi Level Cell) позволило хранить на одном транзисторе два бита информации. В качестве опытных образцов существуют 4-битовые ячейки. Компания Intel в 1997 году /5/ представила флэш-память с 2-битовыми ячейками, которая получила название Strata Flash.
Ячейки MLC применяются в памяти NOR, но наиболее популярны в памяти NAND. Память SLC NAND, в сравнении с MLC NAND, имеет более высокие скорости передачи данных, меньшее энергопотребление и повышенную надёжность. Однако, MLC NAND имеет большую ёмкость и меньшую цену.
Для согласования выходного интерфейса флэш-памяти с внешней шиной используется контроллер, выполненный в виде отдельной микросхемы либо встроенный в микросхему флэш-памяти.
Архитектурные способы повышения скорости обмена данными между ЦП и ОП.
Как указано в /2/, быстродействие СБИС DRAM увеличивается существенно медленнее, чем быстродействие процессоров. Важнейшим архитектурным решением для сглаживания этого противоречия явилось введение в структуру вычислительных машин кэш-памяти – быстродействующего буфера между основной памятью и регистрами процессора. В эту буферную память из основной памяти помещаются копии команд и данных, относящихся к обрабатываемому в данный момент фрагменту программы. Работа кэш-памяти скрыта от пользователя. Кэш-память наиболее эффективна, если она встроена внутрь кристалла процессора (кэш-память 1-го уровня – L1). Её объём составляет 16-32 Кбайт. В большинстве современных компьютеров используют 2- или 3-уровневую кэш-память, L2 и L3, соответственно. Кэш-память L2 объёмом 256-512 Кбайт часто располагается в одном корпусе с процессором и соединяется с ним с помощью специальной локальной шины, работающей на основной или половинной частоте процессора. Кэш-память L3 объёмом в несколько Мбайт размещается на системной плате компьютера. Обычно всё содержимое кэш L1 находится в кэш L2, а всё содержимое L2 является частью кэш L3.
Вся доступная программе информация размещается в оперативной памяти. При обращении процессора к памяти вначале проверяется наличие требуемых данных в кэш-памяти. Обнаружение искомой информации фиксируется как кэш-попадание, в противном случае фиксируется кэш-промах. Обмен данными между кэшем и оперативной памятью осуществляется информационными блоками. В современных микропроцессорных системах используются блоки фиксированного размера, например, 32 байта. Управляет кэш-памятью специальный контроллер кэша. Если адресуемый операнд находится в кэше, он быстро извлекается из него (при чтении) или результат операции заносится в кэш (при записи). При отсутствии требуемого операнда в кэш-памяти процессор считывает из оперативной памяти блок данных, содержащий искомый операнд и помещает его в кэш. Запись данных, не имеющих копий в кэше, проводится непосредственно в оперативную память.
Пакетный обмен, с одной стороны, позволяет интенсифицировать поток данных в системной шине и за счёт этого уменьшить затраты времени на обмен, с другой стороны, повышает разнообразие вариантов обмена и усложняет управление. Можно выделить следующие способы обмена данными процессора с оперативной памятью, построенной на СБИС DRAM: пакетный доступ, конвейерный доступ и их сочетание.
Структура
оперативной памяти с пакетным доступом
и чередованием банков представлена на
рисунке 7.7 /2/ и содержит в себе следующие
блоки: накопитель,
разделённый на 4 банка (Б0, Б1, Б2, Б3);
регистр
данных,
содержащий 4 субрегистра- фиксатора
данных (Ф0, Ф1, Ф2, Ф3), соответственно 4-м
банкам; мультиплексор
(демультиплексор)
– М/ДМ; регистр
адреса
(РА), блок
управления
(БУ). Разрядность ячеек каждого банка
соответствует разрядности шины данных
в системной шине. Адреса присваиваются
ячейкам оперативной памяти с чередованием
номера банка (на рисунке 7.7: 0, 1, …, 11).
Накопитель (упорядоченный массив из
n-разрядных
ячеек) разделяется на m
банков: ![]() ,
k
– целое. В рассматриваемом примере k
= 2.
,
k
– целое. В рассматриваемом примере k
= 2.
При этом адрес i-ой ячейки представляется следующим образом (Формула 7.1):
![]() ,
(7.1)
,
(7.1)
где d – адрес внутри банка, b – номер банка (b = 0, 1, …, m-1). Такое распределение адресов между m банками называют m-кратным чередованием банков.
При пакетном обмене в РА запоминается адрес внутри банка. БУ обеспечивает считывание целой строки ячеек из накопителя, соответствующей адресу в РА во всех m банках.
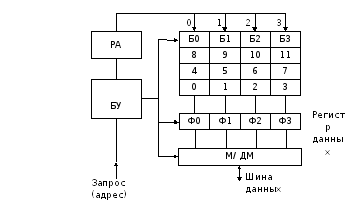
Рисунок 7.7 – Структура оперативной памяти с пакетным
доступом и чередованием банков
Содержимое
считанных ячеек фиксируется в регистре
данных. Далее данные из Ф0, Ф1, … по очереди
с использованием мультиплексора
передаются по системной шине данных.
Пусть, например, осуществляется считывание
пакета из ячеек с адресами 4, 5, 6, 7 (Рисунок
7.7). Если обозначить время доступа через
![]() ,
а время передачи через
,
а время передачи через ![]() ,
то оценка времени чтения пакета
,
то оценка времени чтения пакета ![]() без чередования банков вычисляется по
формуле 7.2, а с чередованием банков
осуществляется по формуле 7.3.
без чередования банков вычисляется по
формуле 7.2, а с чередованием банков
осуществляется по формуле 7.3.
![]() (7.2)
(7.2)
![]() (7.3)
(7.3)
Быстродействие памяти по отношению к быстродействию процессора характеризуется числом тактов ожидания в цикле обращения к памяти. Допустим, что время доступа соответствует 3 тактам, а время передачи – 2 тактам. Тогда в случае без чередования банков время передачи пакета из 4 слов можно охарактеризовать вектором (5, 5, 5, 5), а при использовании чередования банков – (5, 2, 2, 2). Из приведённых оценок видно, что в структурах оперативной памяти с пакетным доступом интенсивность обмена повышается.
При записи работа организована следующим образом: данные пакета из процессора по очереди записываются в субрегистры Ф0, …, Ф3, а затем осуществляется запись одновременно в ячейки всех банков.
Структура оперативной памяти с конвейерным доступом и чередованием банков представлена на рисунке 7.8 /2/.
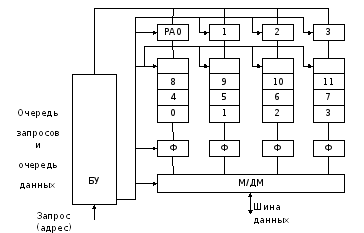
Рисунок 7.8 - Структура оперативной памяти с конвейерным
доступом и чередованием банков
Она содержит следующие блоки: накопитель, разделённый на 4 банка (Б0, Б1, Б2, Б3); 4 регистра данных (Ф) с независимым управлением (в отличие от структуры на рисунке 7.7); мультиплексор (демультиплексор) – М/ДМ; регистры адреса РА0-РА3 для каждого банка; блок управления (БУ). Разрядность ячеек для каждого банка соответствует разрядности данных в системной шине. Адреса присваиваются ячейкам оперативной памяти с чередованием номера банка (на рисунке 7.8: 0, 1, …, 11).
Цикл обращения к памяти (например, чтения) содержит 3 фазы: доступ к ячейке, воспроизведение данных, передача данных от регистров Ф через мультиплексор и системную шину в процессор. В качестве примере рассмотрим чтение пакета с последовательностью адресов 8, 6, 1, 7. Ограничение на расположение адресов ячеек здесь менее жёсткое, чем при пакетном доступе. Требуется, чтобы адреса ячеек пакета находились в разных банках. Если длительность фаз считать одинаковой, равной T, то справедливы следующие оценки для времени чтения пакета из 4 слов: без конвейеризации – формула 7.4, с конвейеризацией – формула 7.5 /2/.
![]() (7.4)
(7.4)
![]() (7.5)
(7.5)
В
общем случае возможно сочетание обоих
изложенных способов доступа. При этом
накопитель оперативной памяти разбивается
на ![]() банков, образующих прямоугольную
матрицу. Адреса ячеек располагаются по
порядку сначала в банках первой строки,
затем второй и т.д. Организуется пакетный
доступ к строке ячеек и конвейерный
доступ к строкам. В каждом интервале,
равном
банков, образующих прямоугольную
матрицу. Адреса ячеек располагаются по
порядку сначала в банках первой строки,
затем второй и т.д. Организуется пакетный
доступ к строке ячеек и конвейерный
доступ к строкам. В каждом интервале,
равном ![]() цикла памяти, осуществляется доступ к
k
ячейкам с идущими подряд адресами.
цикла памяти, осуществляется доступ к
k
ячейкам с идущими подряд адресами.
В следующей главе рассмотрим, каким образом осуществляется управление памятью.
Управление памятью. Динамическое распределение памяти.
Согласно /2 - 4/, непосредственно адресуемая процессором оперативная память (ОП) имеет сравнительно небольшой объём, что в большинстве случаев не позволяет её вместить все команды и данные исполняемых программ. Обычно в памяти содержатся только их фрагменты. Все программы и данные хранятся во внешней относительно дешёвой памяти – ВЗУ. Поскольку процессор не имеет прямого доступа к ВЗУ, команды и данные исполняемой программы предварительно надо переписать в ОП. Ещё больше трудностей возникает в многозадачном режиме работы ВМ, когда в ОП одновременно должны храниться команды и данные нескольких задач. На ОС возлагаются функции по распределению ресурса ОП между отдельными программами. Так как заранее неизвестно, какие программы и в какой комбинации могут выполняться, распределение памяти между программами должно осуществляться динамически в ходе вычислений. Процедура, при которой ОС активным частям программ выделяет определённые области ОП и осуществляет привязку адресов загружаемым программам к конкретным адресам физикой ОП, называется динамическим распределением памяти.
В основе всех известных методов динамического распределения памяти лежат 2 положения: 1) каждому заданию (процессу) необходимо выделять непрерывную и перемещаемую область памяти, и 2) должна обеспечиваться возможность попеременной загрузки заданий в ОП.
Для организации обменов между ВЗУ и ОП внешняя память представляется в виде набора частей (блоков) отдельных программ. Если требуемый фрагмент программы отсутствует в ОП, процессор обращается к ОС которая, используя специальные процедуры, считывает из внешней памяти в ОП соответствующий блок. Если для требуемого фрагмента в ОП недостаточно места, то ОС предварительно освобождает такое место, пересылая неиспользуемые блоки из ОП в ВЗУ. Перемещаемость программ при их размещении в ОП можно обеспечить, если для адресации операндов внутри каждого блока использовать метод базирования (см. относительные режимы адресации в главе 5). Этот метод предполагает, что все программы представлены в относительных адресах с началом в нулевой ячейке. Тогда адрес операнда определяется базовым адресом (сохраняется в одном из сегментных регистров процессора) и смещением относительно этого базового адреса (указывается или вычисляется в команде). Путём изменения содержимого сегментных регистров программы можно перемещать в ОП, не нарушая их внутренней адресации.
Попеременная загрузка заданий (программ) в современных ВМ осуществляется путём свопинга (от англ. swap – обмен) между ОП и ВЗУ. В мультипрограммных системах такой обмен осуществляется автоматически (без участия программиста) с помощью специальных программно-аппаратных средств под управлением ОС.
Динамическое распределение памяти тесно связано с понятием виртуальной памяти. Согласно /3/, под виртуализацией памяти понимается метод автоматического управления иерархической памятью, при котором программисту кажется, что он имеет дело с единой памятью большой ёмкости и высокого быстродействия. Эту память называют виртуальной (кажущейся). Впервые идея виртуализации памяти появилась в 1959 году.
В соответствии с /2, 3/, использование виртуальной памяти позволяет писать программы, размер которых превосходит имеющуюся ОП. При этом с помощью виртуальных (логических) адресов обеспечивается адресация всего адресного пространства ВМ, которая, напомним, зависит от разрядности шины адреса. Систему виртуальной памяти можно представить в виде одноуровневой логической и двухуровневой (ОП и ВЗУ) физической памяти. Адреса, к которым программа может обратиться, образуют виртуальное адресное пространство системы, а реальные адреса – физическое адресное пространство, причём линейное, состоящее из N ячеек разрядностью n. Программа пишется в виртуальных адресах, но для её выполнения требуется, чтобы обрабатываемые команды и данные находились в ОП. Для этого необходимо, чтобы каждому виртуальному адресу соответствовал физический адрес.
Все операции по управлению виртуальной памятью, динамическому распределению памяти и преобразованию адресов в ВМ выполняются автоматически. В современных процессорах некоторые из указанных функций реализуются с помощью специального контроллера управления памятью MMU (Memory Management Unit).
Среди моделей виртуальной памяти можно выделить сегментную, страничную и сегментно-страничную организацию виртуальной памяти.
Сегментная и сегментно-страничная организация памяти.
В
соответствии с /2, 8/, сегментирование
– это разделение памяти на логические
блоки произвольной длины. Логическое
пространство задачи обычно представляется
в виде нескольких сегментов. Каждый
сегмент имеет имя, в соответствии с
которым ОС при распределении памяти
назначает базовый адрес. Количество
сегментов определяет пользователь при
подготовке программы. Для раздельного
хранения команд, данных, стековых данных
выделяются специальные сегменты: сегмент
кода, сегмент данных, сегмент стека.
Максимальное количество сегментов (s)
определяется разрядностью поля команды,
которое используется для задания номера
сегмента. Например, в процессорах Pentium
разрядность индекса селектора сегмента
равна 13, что соответствует 8192 сегментам.
Предельный размер (длина) каждого
сегмента определяется разрядностью
внутрисегментного смещения. Например,
для процессоров Pentium
длина сегмента ограничивается величиной
![]() Гбайта. Длина сегмента может меняться
во время выполнения программы. Сегмент
может переполниться, но это случается
редко, поскольку длина сегментов
достаточно большая.
Гбайта. Длина сегмента может меняться
во время выполнения программы. Сегмент
может переполниться, но это случается
редко, поскольку длина сегментов
достаточно большая.
Сегменты всех активных задач, определённые в виртуальном адресном пространстве, размещаются в ВЗУ. Поскольку объём ОП относительно невелик, то не все сегменты могут в неё поместиться. Соответствие между виртуальной памятью и физической ОП устанавливается ОС с помощью специальной таблицы соответствия (дескрипторной таблицы), которую ОС формирует всякий раз, когда в распределении памяти происходят изменения (например, при загрузке новой задачи). Размер таблицы определяется максимальным числом сегментов виртуального адресного пространства. Каждая строка таблицы (дескриптор) содержит информацию о номере сегмента, базовом адресе сегмента в ОП. Базовые адреса назначаются при загрузке сегмента и при любом изменении в распределении памяти. Пример сегментного распределения памяти представлен на рисунке 8.1 /2/.
Стрелками на рисунке 8.1 показано размещение сегментов в ОП в соответствии с адресами, определяемыми ОС, а пунктирными линиями – обмены между сегментами ОП и ВЗУ при свопингах.
Помимо базового адреса сегмента в ОП каждый дескриптор таблицы соответствия содержит биты управления виртуальной памятью и дополнительные атрибуты, используемые механизмом защиты процессора (см. главу 6).
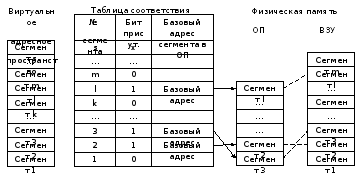
Рисунок 8.1 – Сегментное распределение памяти
Например, бит присутствия P (Present) показывает, где находится искомый сегмент: в ОП (P=1) или на диске (P=0). Бит доступа A (Access) помогает ОС выбрать сегмент, который возвращается в ВЗУ, когда в ОП нет достаточного места для нового сегмента.
Доступ к элементам дескрипторной таблицы осуществляется с помощью указателей (селекторов), для размещения которых используются сегментные регистры, например, в процессорах Pentium, регистры CS, DS, ES, FS, CS, SS.
Способ формирования физического адреса операнда сегментированной памяти показан на рисунке 8.2 /2/:
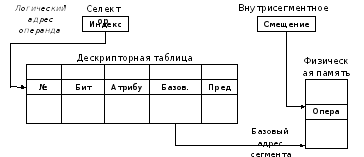
Рисунок 8.2 – Вычисление физического адреса в сегментной
памяти
При обращении к сегменту памяти, присутствующему в ОП, в выполнении команд нет никаких отличий по сравнению с обычной физической памятью. По логическому адресу операнда, состоящему из двух частей (селектора – номера виртуального сегмента и смещения внутри сегмента) выбирается строка в дескрипторной таблице сегментов, где считывается информация о начальном адресе сегмента в ОП. К этому адресу добавляется внутрисегментное смещение (вторая часть логического адреса), что и даёт требуемый физический адрес искомого операнда в ОП.
Если требуемый сегмент отсутствует в ОП, то возникает прерывание, по которому процедура обработки этого прерывания переписывает в ОП нужный сегмент. При наличии свободного места для загрузки сегмента никаких проблем не возникает, и после загрузки нового сегмента в ОП осуществляется повторный запуск команды обращения к памяти. Если в ОП недостаточно места для записи отсутствующего сегмента, то соответствующая процедура ОС сначала освобождает требуемое место, переписывая на диск один или несколько неиспользуемых в данный момент сегментов. Для этого наиболее часто используется алгоритм LRU (Last Recently Used), обеспечивающий замену сегмента, к которому не было обращения самое продолжительное время. ОС использует бит доступа A для определения приблизительного времени последнего использования сегмента. Используя механизм свопинга, ОС создаёт иллюзию, что все сегменты программы постоянно находятся в ОП.
Рассмотренный способ реализации виртуальной памяти, при котором целые сегменты загружаются и удаляются из ОП только при необходимости, называют сегментацией с подкачкой сегментов или сегментацией с вызовом сегментов по требованию.
Особенностью использования сегментированной памяти является то, что после многократных свопингов сегментов, в ОП могут образовываться свободные участки памяти слишком малого размера и неудобные для использования. Это явление называется внешней фрагментацией (неиспользуемое пространство попадает не в сегменты, а в пустоты между ними). Чтобы избежать подобной ситуации, ОС выполняет уплотнение сегментов. При первом способе каждый раз при появлении пустого пространства следующие сегменты перемещаются ближе к адресу 0, удаляя, таким образом, это пустое пространство. При втором способе уплотнение выполняется только тогда, когда на долю пустот придётся больше некоторого процента от общего объёма памяти.
Несмотря на отмеченный недостаток использование сегментной модели в значительной степени упрощает изолирование программных блоков отдельных задач друг от друга в мультизадачной системе. Для каждой задачи обычно выделяется собственная локальная память, и одновременно задача может разделять с другими задачами совместную память, которую называют глобальной. Соответствие между логическими и физическими адресами в мультизадачной системе устанавливаются с помощью глобальной GDT (общей для всех задач) и локальных LDT (отдельных для каждой задачи) дескрипторных таблиц. Общий объём адресуемой виртуальной памяти отдельной задачи определяется разрядностью адресных полей её логического адреса. Например, в процессорах Pentium пространство виртуальных адресов задачи не может превышать 64 Тбайт.
Страничная и сегментно-страничная организация памяти.
Согласно /2 - 4/, при страничной организации памяти виртуальное и физическое адресные пространства разбиваются на блоки фиксированного размера – страницы. Размер страниц обычно выбирается равным 4 Кбайта (реже 4 Мбайта). Блок ОП, соответствующий виртуальной странице, часто называют страничным кадром или фреймом. Страницам виртуальной и физической памяти присваивают номера. Страничная организация памяти создаёт иллюзию линейной ОП такого же размера, как и адресное пространство программы.
В модели виртуальной памяти со страничной организацией соответствие между виртуальными и физическими страницами устанавливается в процессе распределения памяти при заполнении специальной таблицы страниц, каждая строка которой (страничный дескриптор) содержит базовый адрес страничного кадра в ОП, а также биты управления виртуальной памятью и биты защиты информации на странице. Назначение и использование битов присутствия P и доступа A такое же, как у одноимённых битов при сегментной организации памяти. Признак модификации D устанавливается в страничном дескрипторе при выполнении операции записи в определяемую дескриптором страницу. ОС использует значение этого бита для исключения необязательных свопингов страницы. Если D=1, то к странице было обращение для записи и перед удалением из ОП её необходимо переписать в ВЗУ, в противном случае, (D=0) этого делать не нужно. Страничное распределение памяти аналогично сегментному распределению памяти, представленному на рисунке 8.1, только вместо сегментов используются страницы.
Принципы работы системы виртуальной памяти со страничной организаций похожи на принципы функционирования сегментной памяти. При обращении к памяти номер виртуальной страницы извлекается из виртуального адреса и используется как индекс для поиска нужного дескриптора в таблице страниц. Если страница присутствует в ОП, то из соответствующего дескриптора извлекается базовый адрес соответствующего страничного кадра, который совместно со смещением в виртуальном адресе, определяет физический адрес требуемого операнда (Рисунок 8.3) /2/.

Рисунок 8.3 – Вычисление физического адреса в страничной
памяти
Если требуемая страница отсутствует в ОП, то формируется прерывание, по которому ОС загружает из ВЗУ отсутствующую страницу. После этого управление возвращается процессору, который повторно выполняет команду обращения к памяти. При необходимости освобождения памяти некоторые страницы выгружаются и ОП в ВЗУ. Для этого применяется алгоритм LRU (выгружается дольше всего неиспользовавшаяся страница) или алгоритм FIFO (выгружается страница, которая была загружена раньше всех, независимо от того, когда в последний раз производилось к ней обращение).
Рассмотренный метод работы с виртуальной памятью, при котором страницы переносятся в ОП только в случае необходимости, называется вызовом страниц по требованию.
В отличие от сегментов, страницы не имеют прямой связи с логической структурой программы. Трансляция виртуального адреса в физический выполняется автоматически и быстрее, чем при сегментной организации виртуальной памяти.
Фиксированная длина страниц позволяет решить проблему внешней фрагментации и упрощает распределение памяти. При необходимости загрузки новой страницы в ОП её можно поместить либо в незанятый страничный кадр, либо вытеснить другую страницу, освободив, таким образом, требуемое место. В любом случае, не требуется по-новому располагать страницы в ОП.
Если в сегментной памяти сегменты загружаются целиком, то страничная организация позволяет сократить объём передаваемой между ОП и ВЗУ информации за счёт того, что страницы программы могут не загружаться в ОП, пока они действительно не понадобятся. Сначала в ОП загружается начальная страница программы, и ей передаётся управление. Если в процессе выполнения программы потребуется выборка операндов из другой страницы, ОС загрузит отсутствующую страницу. Особенно заметны преимущества страничной организации памяти при реализации мультизадачных систем. В таких системах при загрузке новой задачи её страницы могут быть направлены в любые свободные в данный момент страничные кадры независимо от того, расположены они подряд или нет.
Однако страничная память тоже подвержена фрагментации. Если пользовательская программа и данные занимают ровно целое число страниц, то при их загрузке в память свободного места там не останется. Но, если они не занимают ровно целое число страниц, на последней странице останется неиспользованное пространство, и в ОП будут появляться свободные участки, бесполезно занимая место. Эта проблема получила название внутренней фрагментации, так как неиспользуемое пространство является внутренним по отношению к странице. Чтобы свести к минимуму объём бесполезного пространства, страницы должны быть небольшими, однако для их хранения потребуется большая таблица страниц.