27.Последовательная организация файлов. Операции добавления и удаления записей в последовательных файлах, блок переполнения.
База данных (БД) – это совместно используемый набор логически связанных данных и описание этих данных, предназначенное для удовлетворения информационных потребностей организации. Можно сказать, что база хранится на диске как набор записей различного формата, т.е. в виде файлов. В данном случае под файлом понимают набор записей одинакового формата, т.е. файл аналогичен отношению. Для наиболее быстрой обработки данных отношение при хранении разбивается на фрагменты. Такие фрагменты наз-ся блоки или страницы. Блоки м.б. по-разному организованы внутри файла, напр., м.б. файлы, организованные в виде кучи, хешированные и последовательные файлы
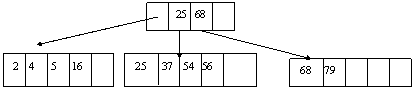
Последовательные файлы эффективно использовать в ситуациях, когда в подавляющем числе запросов записи д.б. отсортированы согласно значению нек-ого поля. Такая организация похожа на организацию файлов в виде кучи, но записи помещаются в файл так, чтобы не нарушать порядок сортировки. Кроме того, каждая запись имеет указатель на след-ющую за ней запись. Т.о., записи физически располагаются в порядке сортировки. Однако иногда возникают блоки переполнения, т.к. неэффективно при каждой вставке сдвигать весь файл. Борьба с блоками переполнения ведется двумя путями:
1) при удалении записи файл также не сдвигается, а освободившееся место заполняется по мере добавления записей;
2) время от времени производится реорганизация файла, т.е. он переписывается, расставляя записи в нужном порядке.
Пример:
28. Индексированные файлы: инициализация, поиск.
Такая организация основана на понятии уникального ключа. Основная особенность этих файлов в никогда не нарушаемой последовательности записей.
Идея индексированных файлов состоит в построении доп. файла, содержащего ключи записей и указатели на данные в главном файле. Индексы бывают разреженные (первичные) и плотные (вторичные).
Разреженные индексы
В разреженном индексе ключ должен гарантировать уникальное значение. Записи индекса состоят из пар (v, b), где b – адрес блока, а v – зн-ние ключа 1ой записи блока. Записи в главном файле д.б. упорядочены. Записи в индексе также упорядочены.
Плотное индексирование
Плотные индексы не требуют упорядочивать гл. файл и не требуют уникальности ключа, поэтому для нек-ого отношения можно построить мн-во плотных индексов. Запись в плотном индексе представляет собой пару (V, p), где V – зн-ние ключа записи, а p – адрес записи.
Обычно при организации индексированного файла каждый блок оставляют пустым на 20% для того, чтобы повысить эф-ть добавления записи (стремимся как можно реже вносить изменения в индекс).
В файле индекса в самой 1ой записи вместо значения ключа помещается -∞, чтобы упростить алгоритм поиска. Индекс также может состоять более чем из одного блока. В этом случае блоки индекса организуются как последовательный файл, либо над индексом строится еще один индекс.
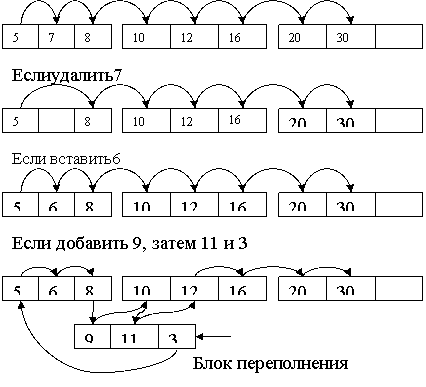
Инициализация. Есть записи с ключами 16, 2, 5, 37, 79, 56, 4, 25, 54, 68.
Процесс состоит из трех этапов.
1-ый этап. Сортируем записи в исходном файле и сортируем по блокам. Обычно файлы БД имеют тенденцию к увеличению, поэтому при создании блоки оставляют свободными на 20 %. После 1-го этапа главный файл имеет вид упорядоченных записей, размещенных в упорядоченные блоки.
2-ой этап. Создание индексного файла. При этом берутся первые элементы каждого блока и создаются пары (значение ключа, адрес блока). Исключение составляет первый блок. Для него пара (-∞,B) – это необходимо для работы со значениями меньше всех существующих в файле.
3-ий этап. Организация блоков индексного файла. Будем считать, что индексный файл организован в виде последовательности.
Алгоритм поиска заключается в следующем. Пусть ищем запись со значением ключа v1, тогда в индексе необходимо найти пару (v2, b) такую, что v2 ≤ v1 и либо v2 последняя запись индекса, либо последующие записи имеют вид (v3, b), где v3 > v1. Искомая запись гарантированно нах-ся в блоке, адрес к-ого принадлежит паре (v2, b). В этом случае говорят, что v2 покрывает v1. Т.о., эффективность поиска равна эффективности поиска в индексе + одно обращение к главному файлу. Поиск в индексе м.б. линейным, двоичным и интерполирующим.
|
|
|
|
|
|